Downloaded 117 times







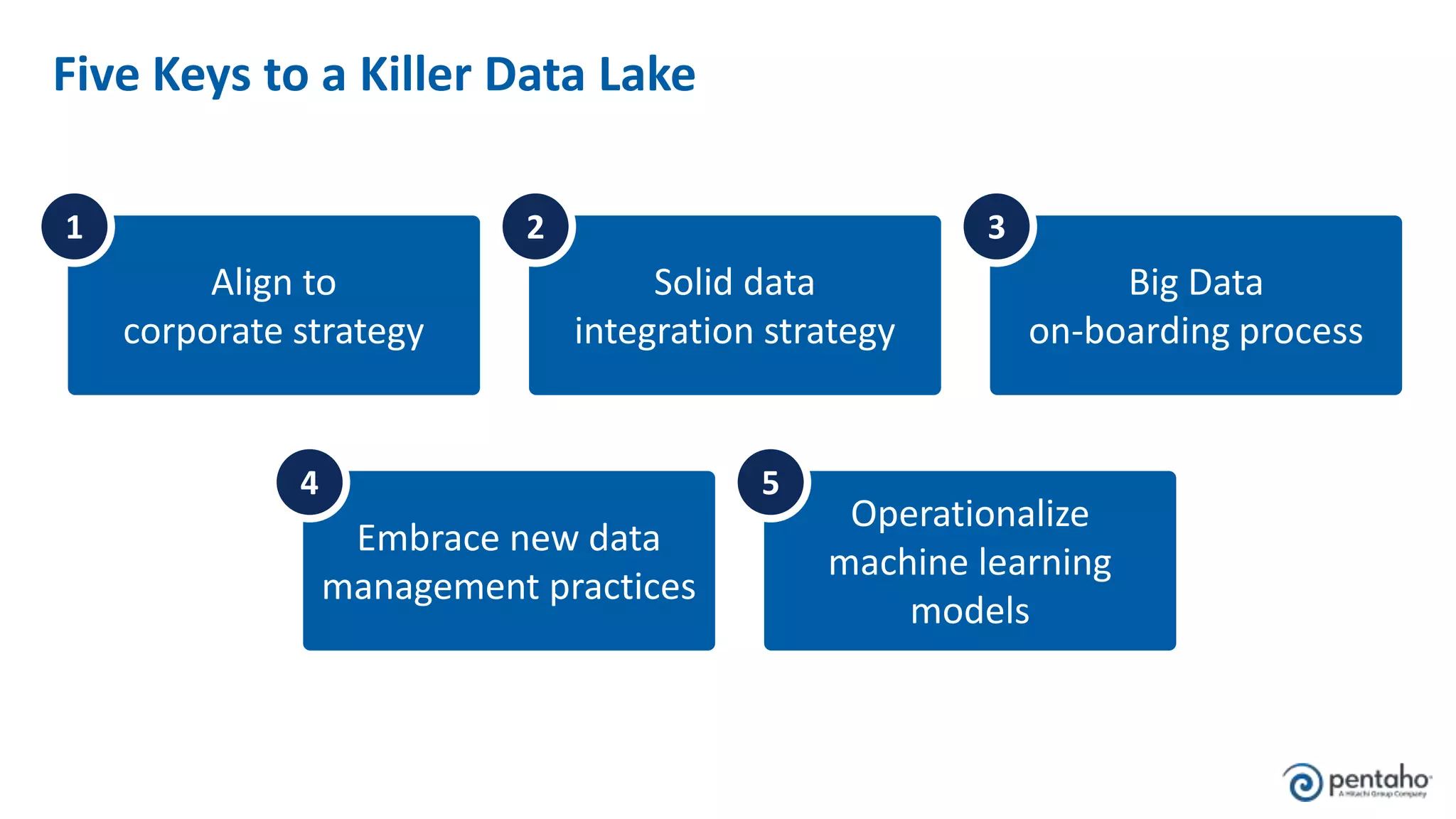


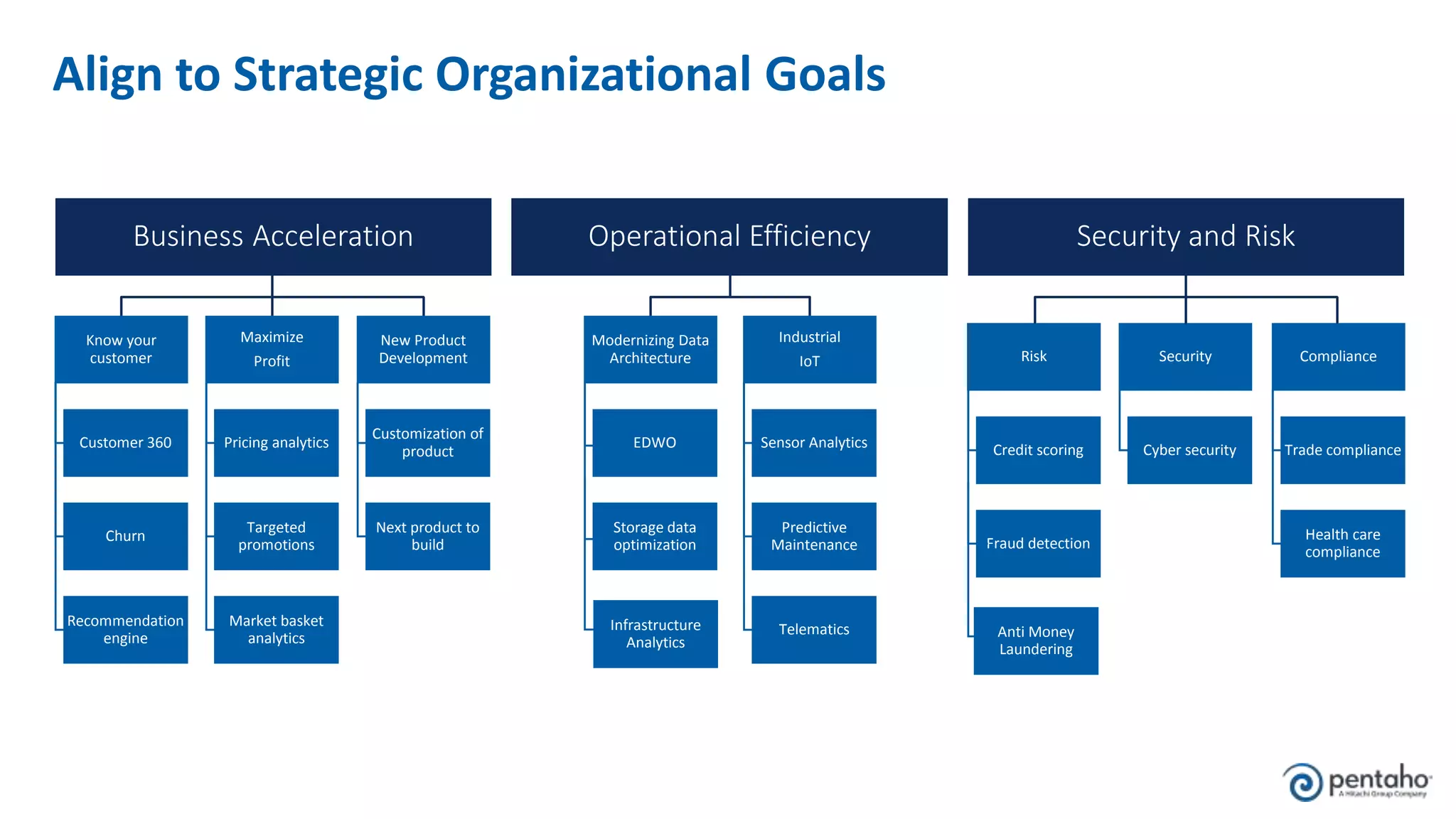


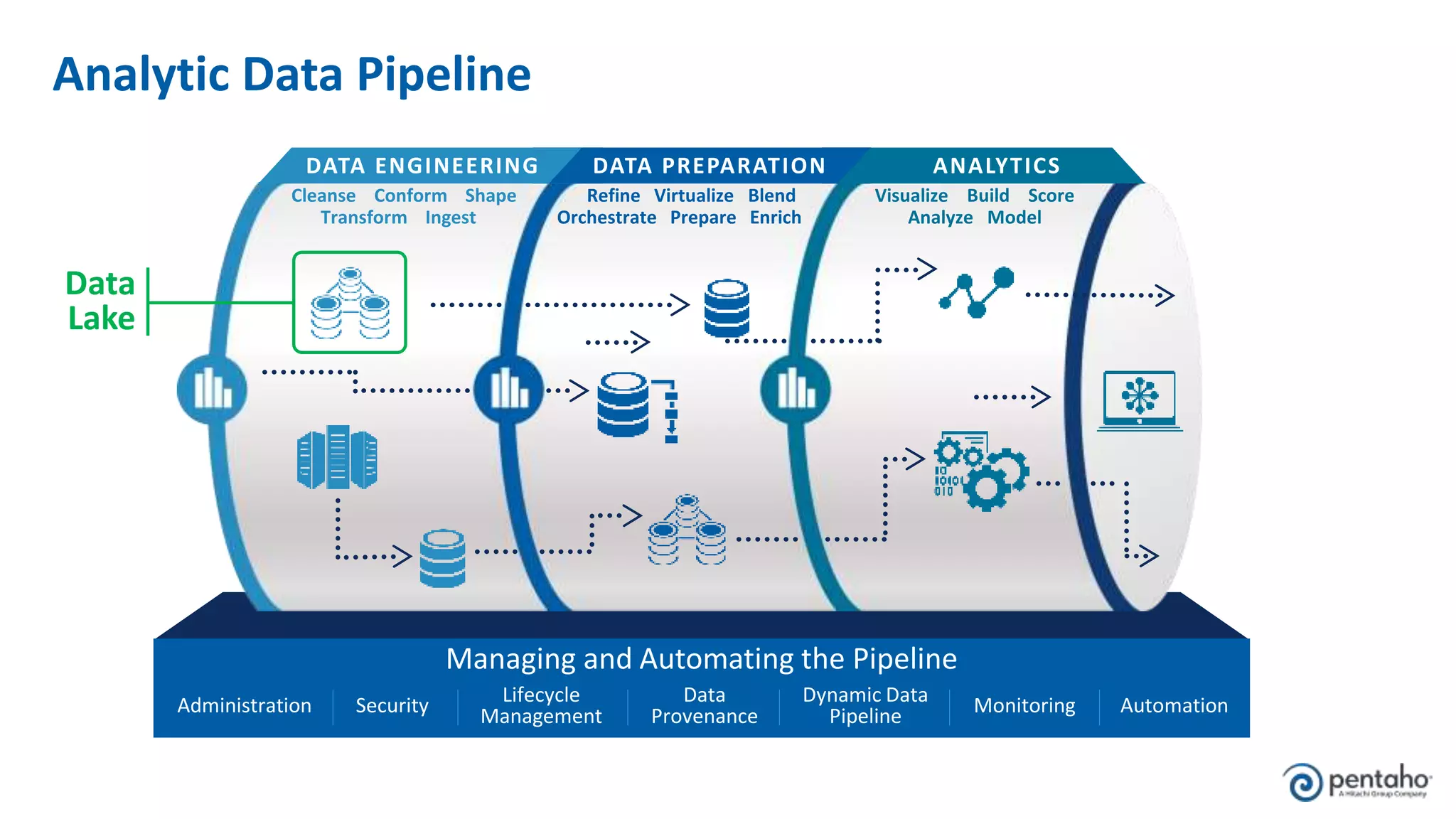


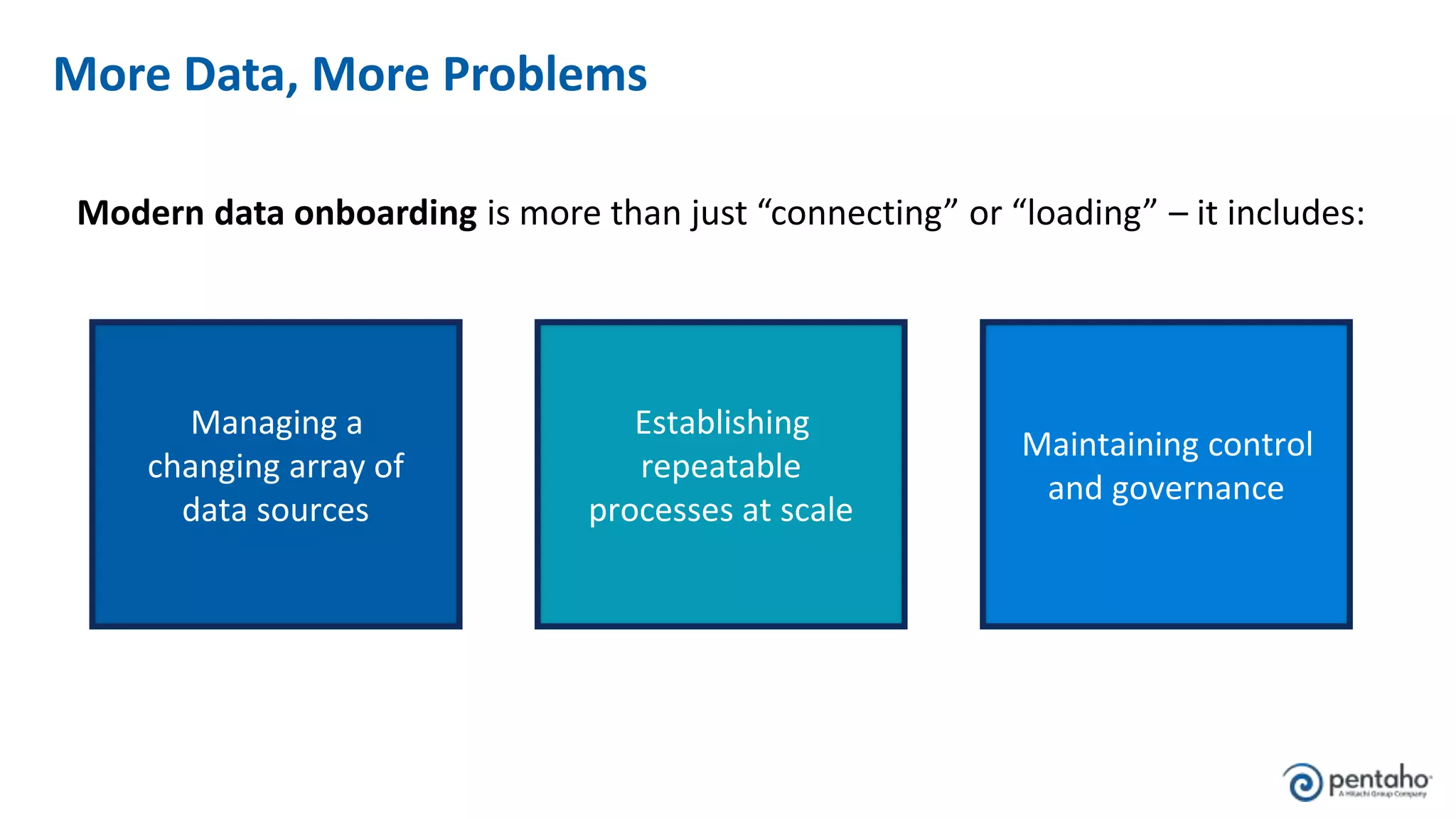
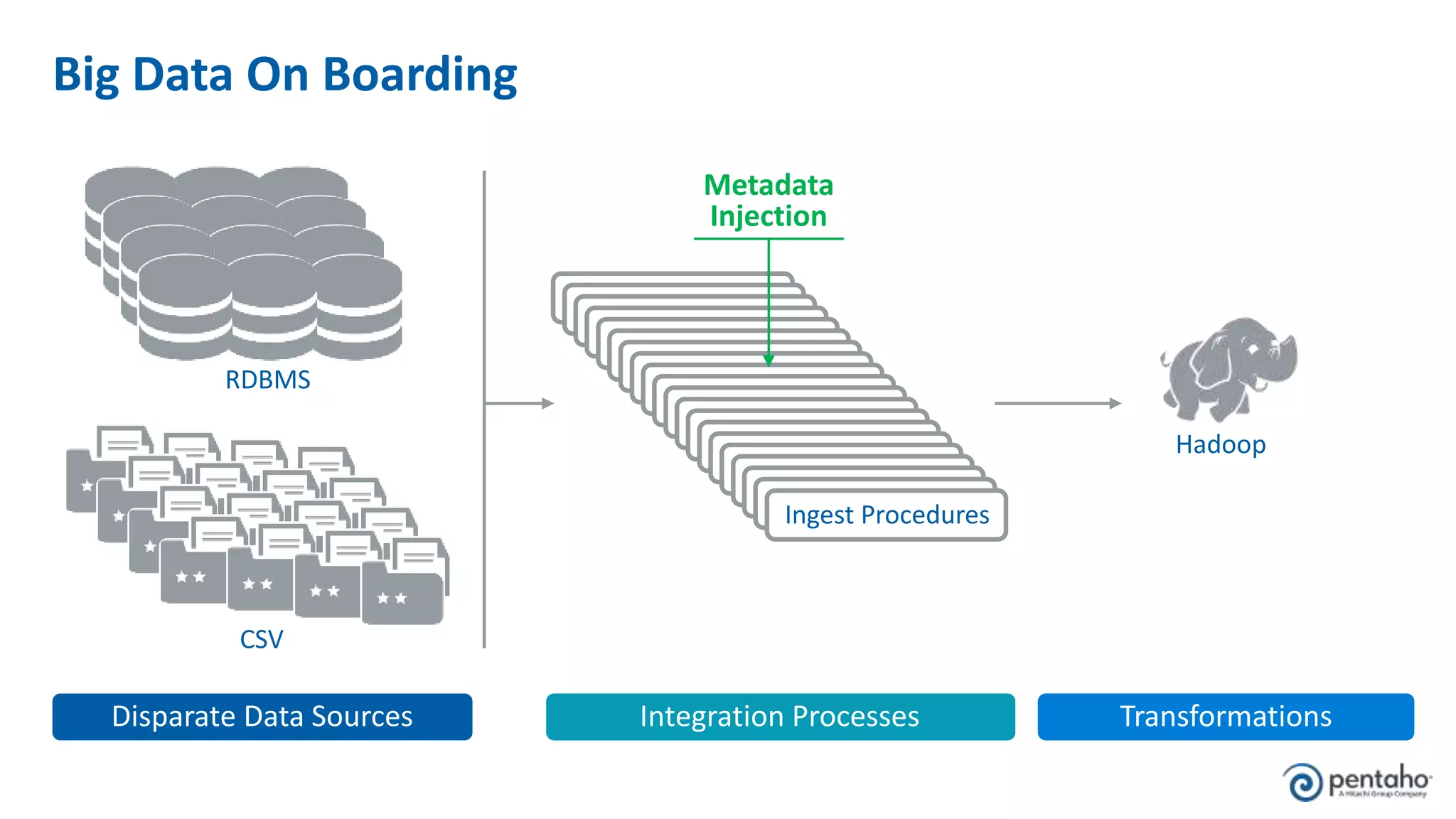



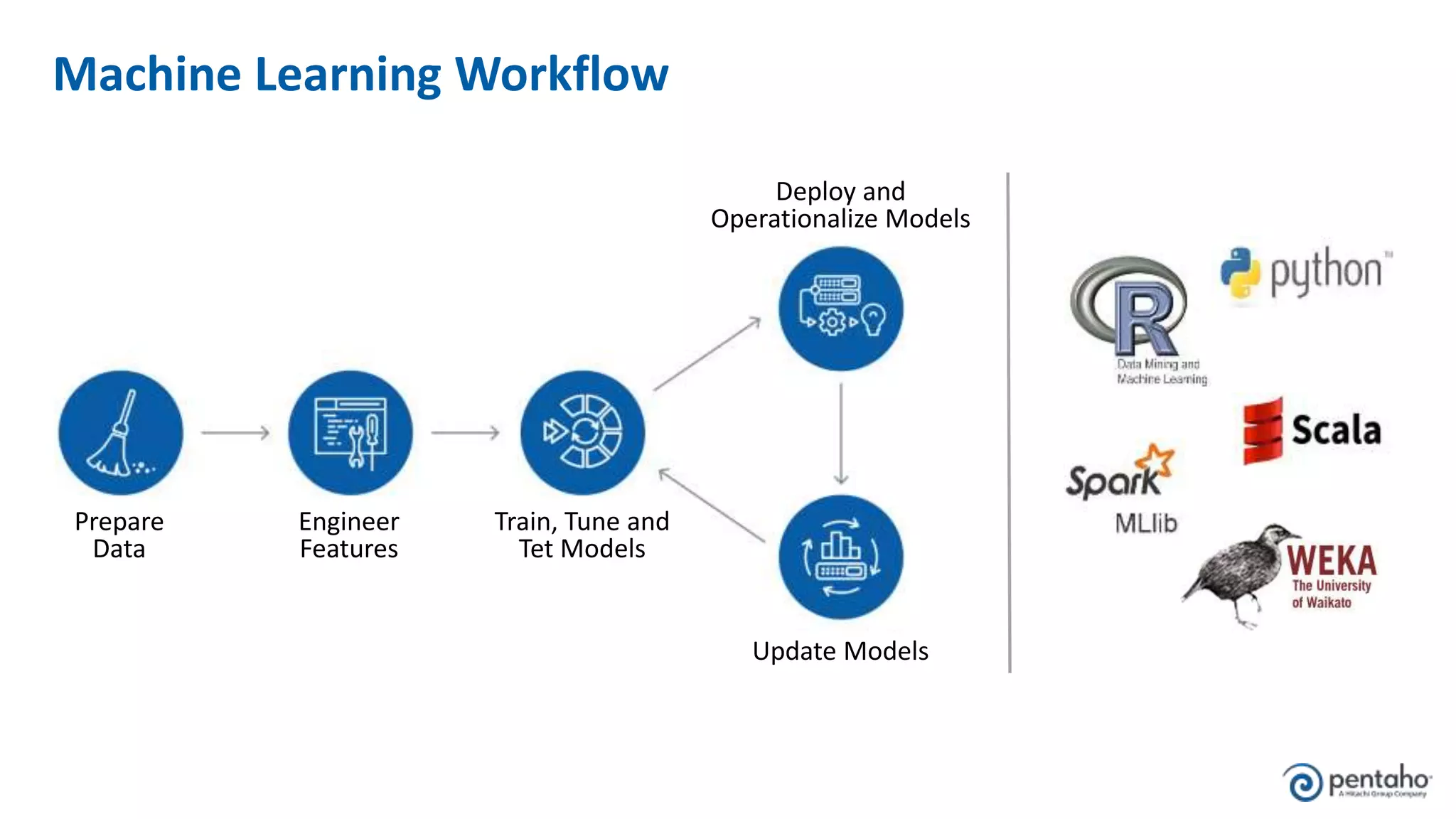

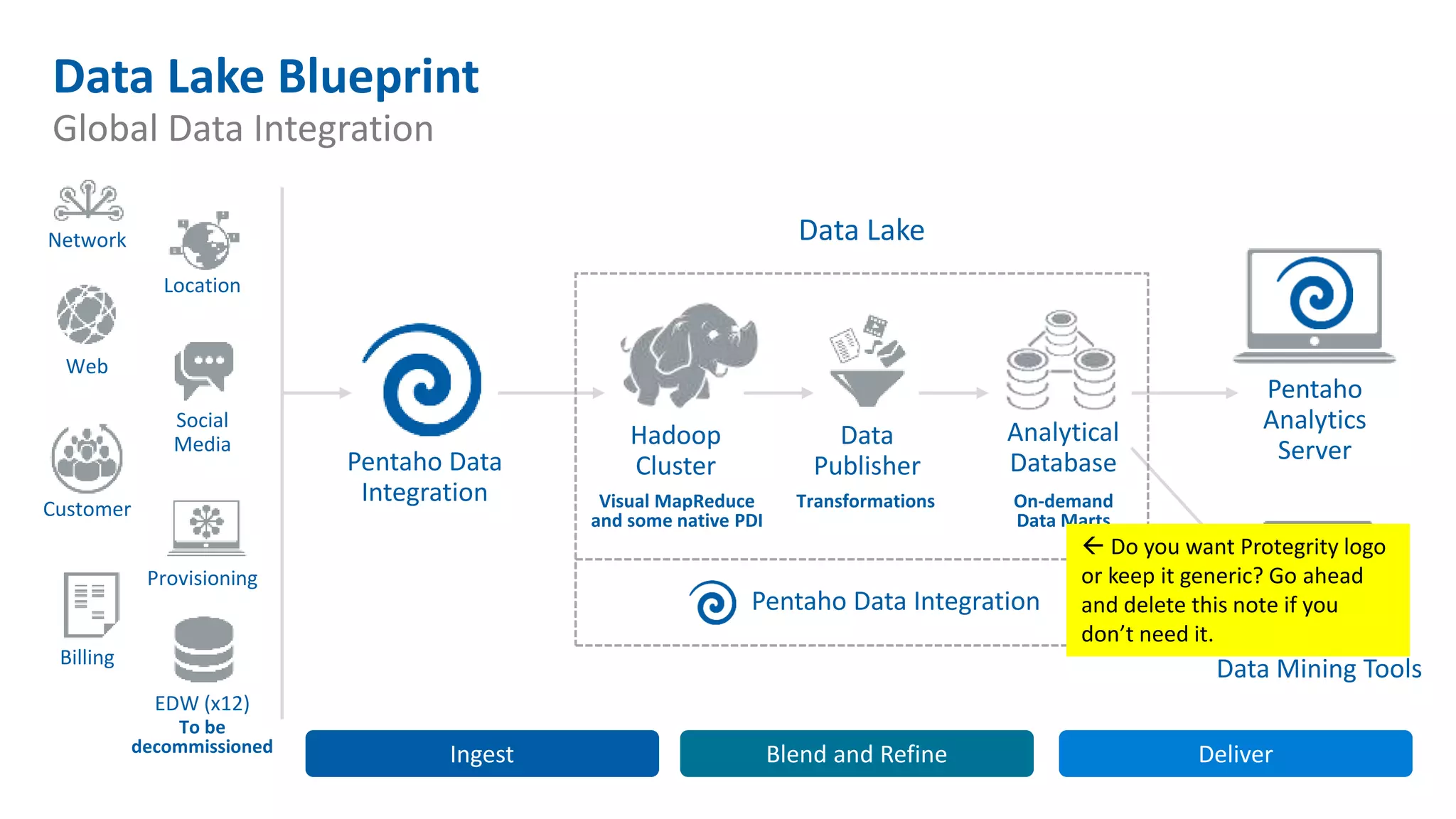






The document outlines five keys to building a successful data lake: 1. Align the data lake to corporate strategic goals and objectives and ensure executive sponsorship. 2. Establish a solid data integration strategy that manages and automates the data pipeline across sources. 3. Develop a process for onboarding big data from diverse sources at scale while maintaining governance. 4. Embrace new data management practices like early data ingestion, adaptive processing, and applying analytics to all data. 5. Operationalize machine learning models by preparing data, training and testing models, and deploying models to uncover new insights.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















