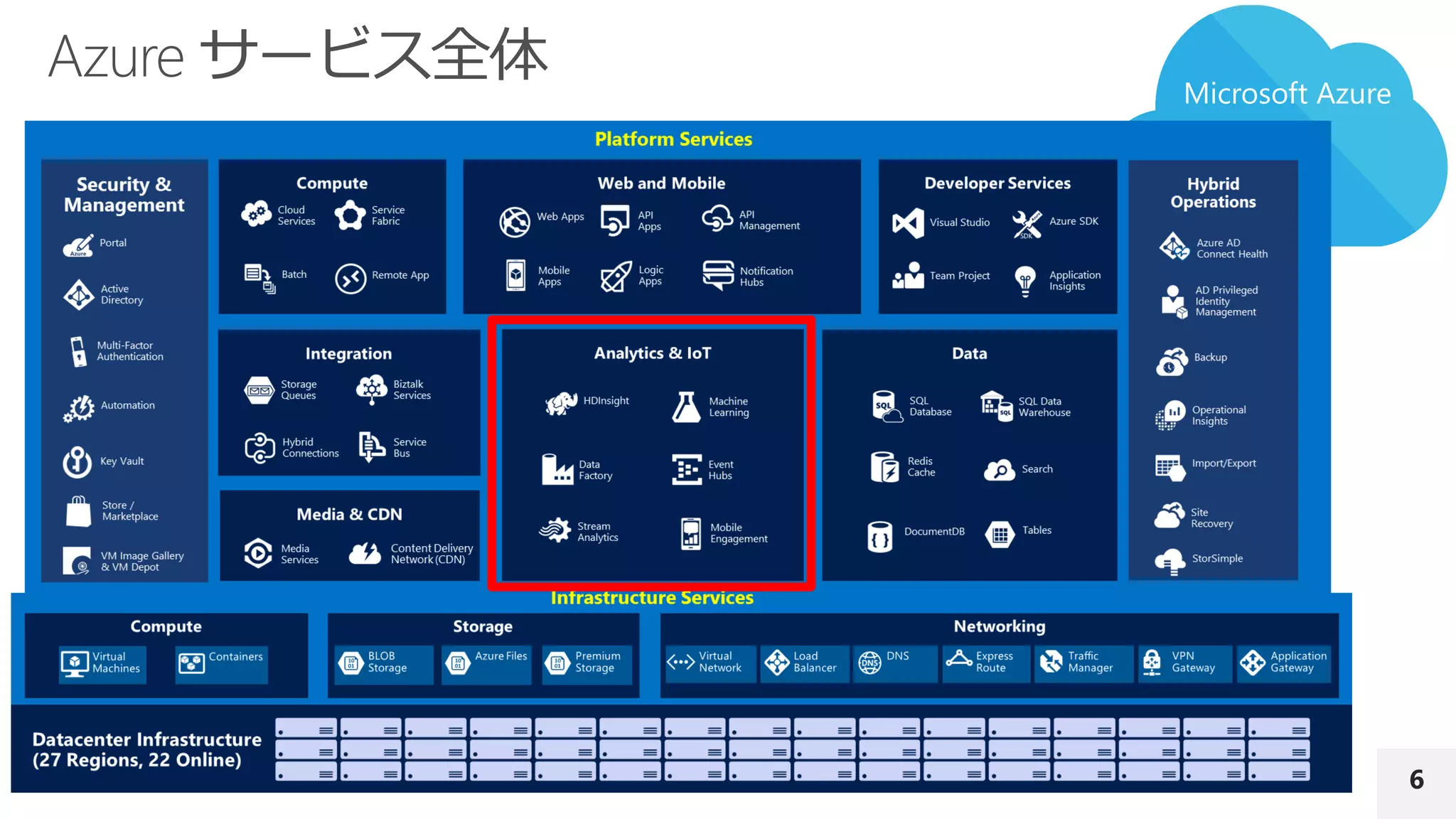
マイクロソフトは より効率的、かつ大量のデータを使ったデータ分析のための基盤を急ピッチで拡充しています。
分析自体やデータ準備の前処理における手段の1つとして使って頂くことを想定している各種製品・サービスについて説明します。
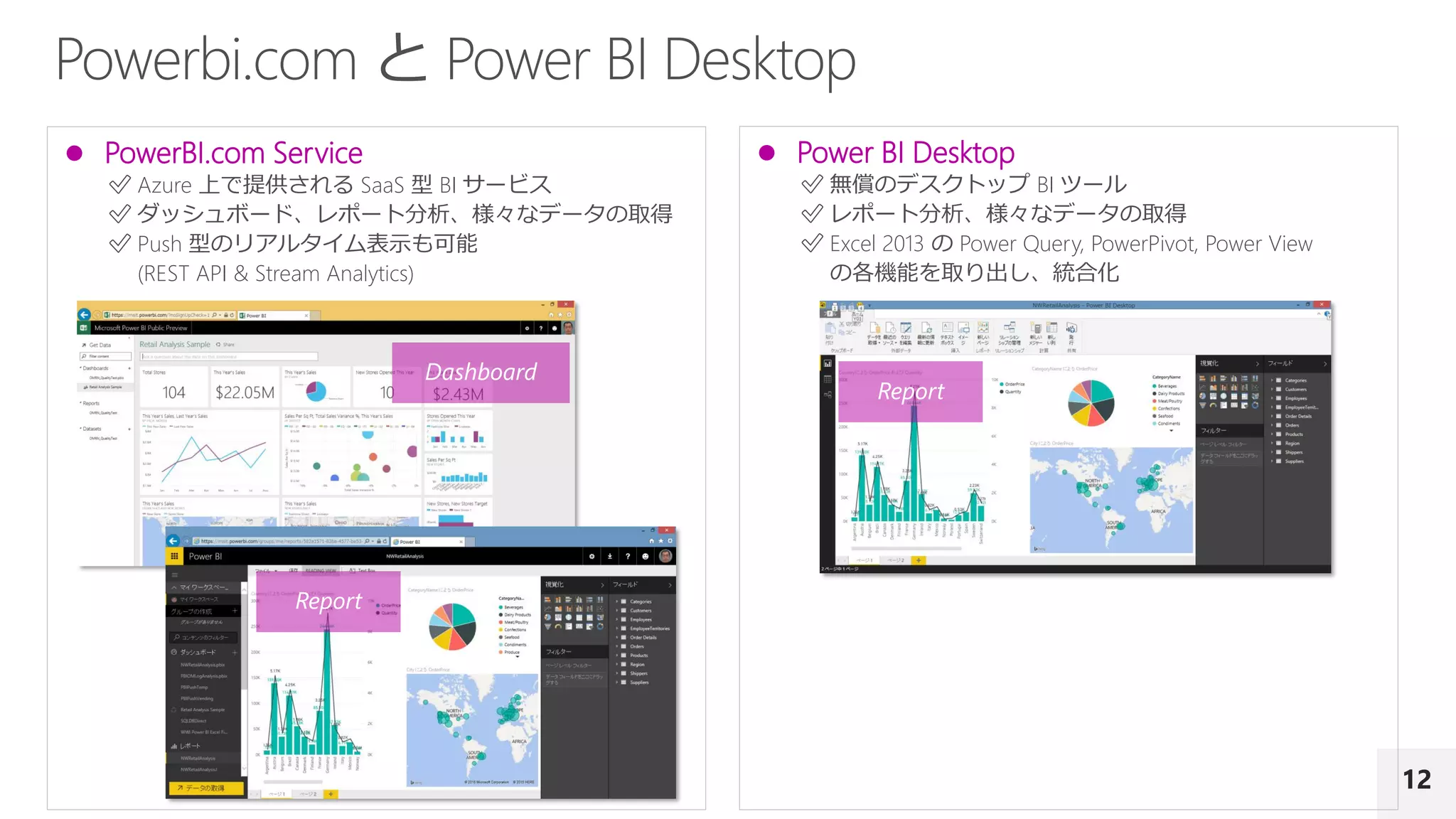
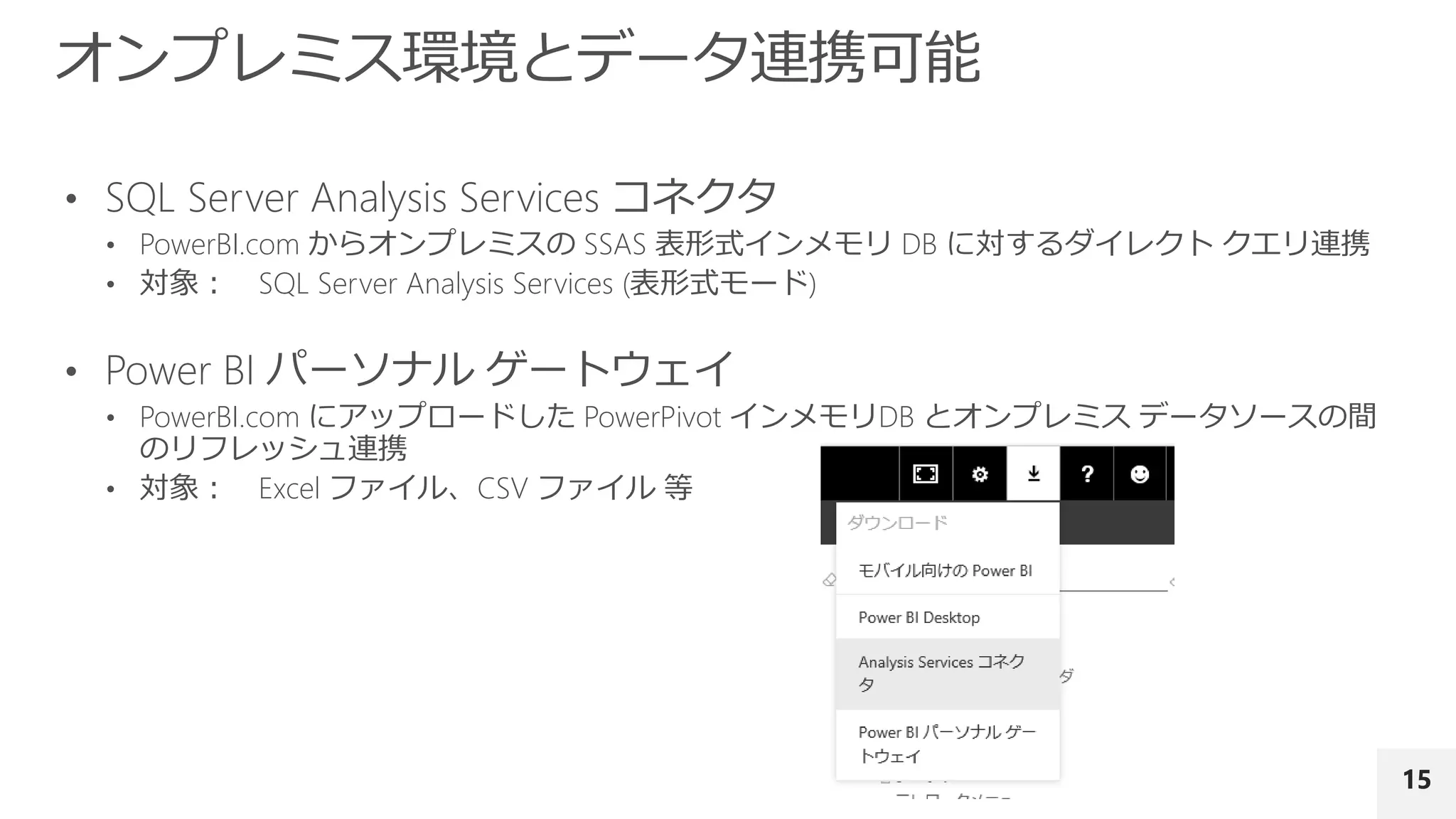
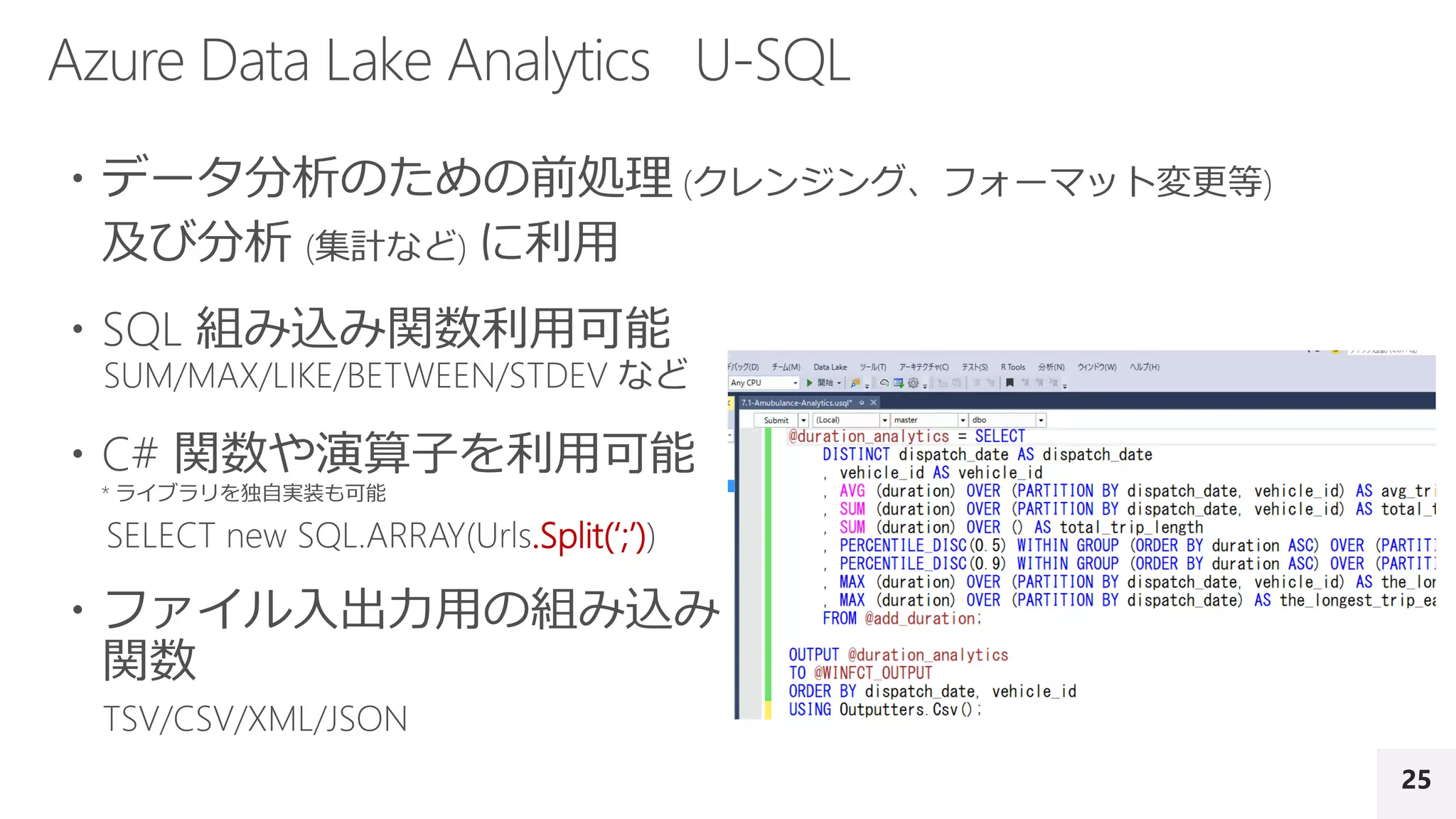
具体的には、R の並列実行環境である Microsoft R Server、Power BI、並列処理基盤である Azure Data Lake Analytics、Azure Machine Learning を取り上げます。
8
Machine
Learning
Stream Analytics
SQL DataWare House
/ SQL Database
/ DocumentDB
IoT Hub /
Event Hub
各種デバイス
Data Factory
Data Lake Store
Storage
(Blob / Table / Queue)
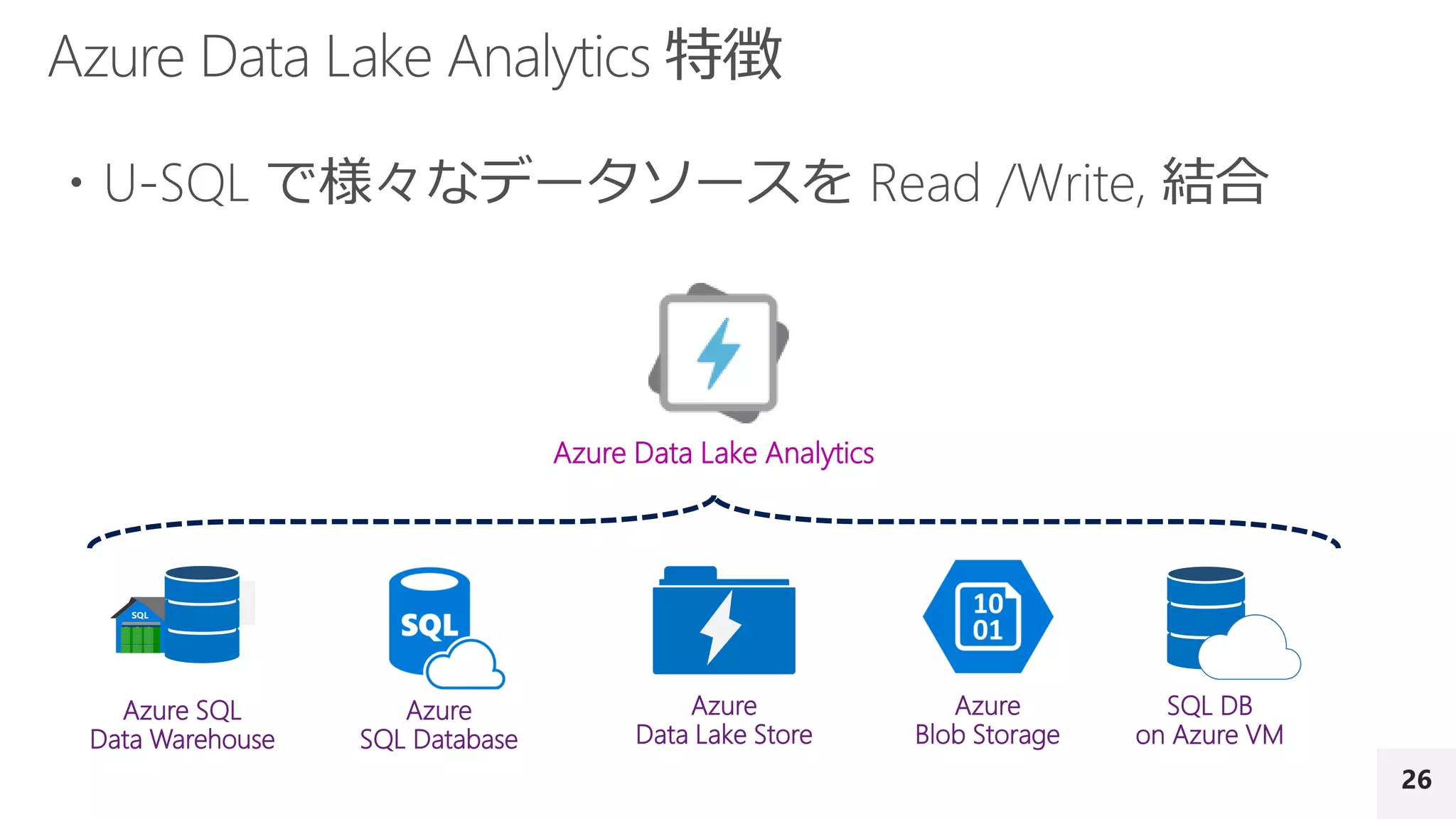
Data Lake Analytics
Power BI
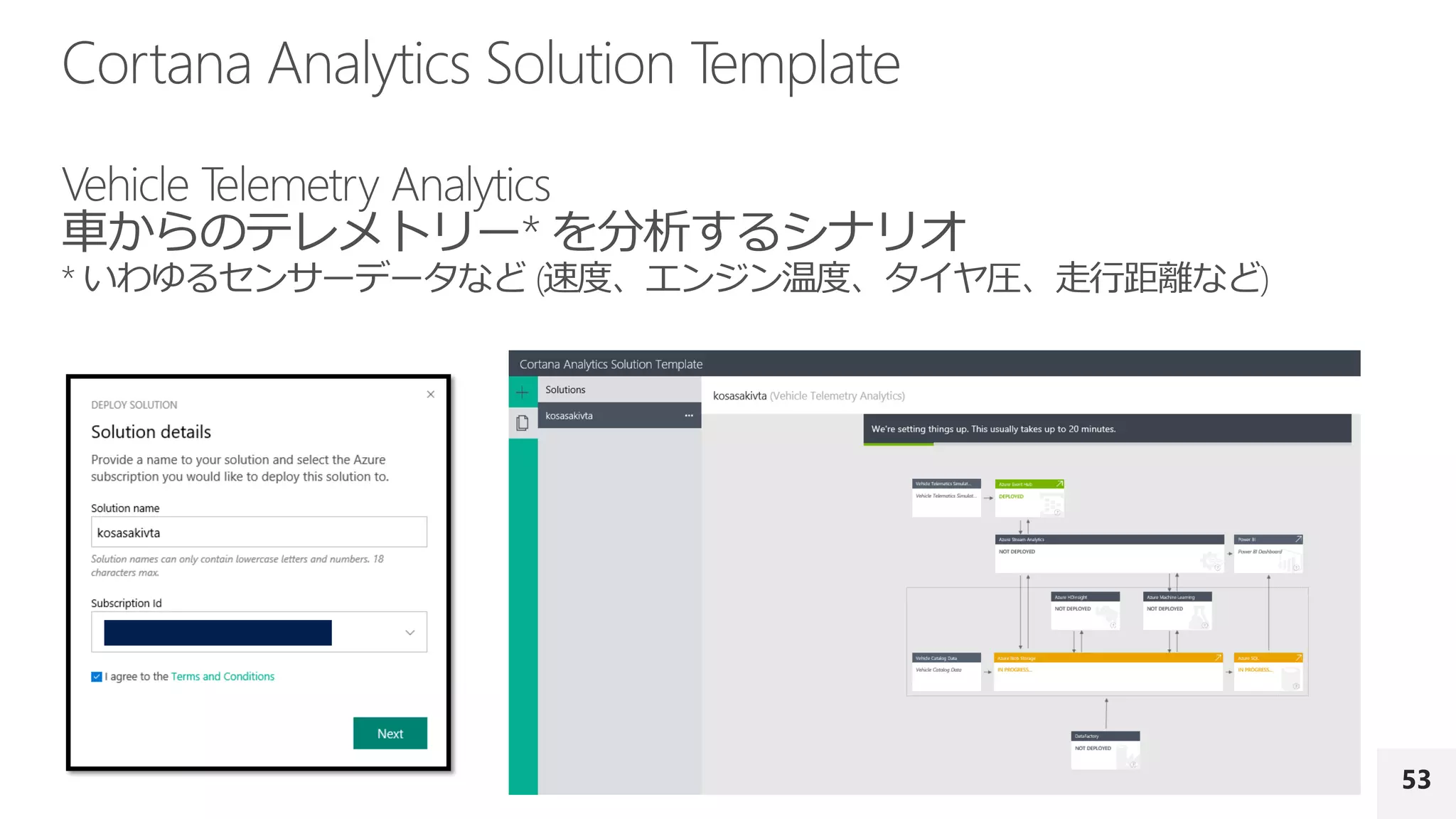
Cortana Analytics Suite (コルタナ アナリティクス スイート) * IoT Hub と R Server 除く
一部サービス含む
Microsoft
R Server
HDInsight
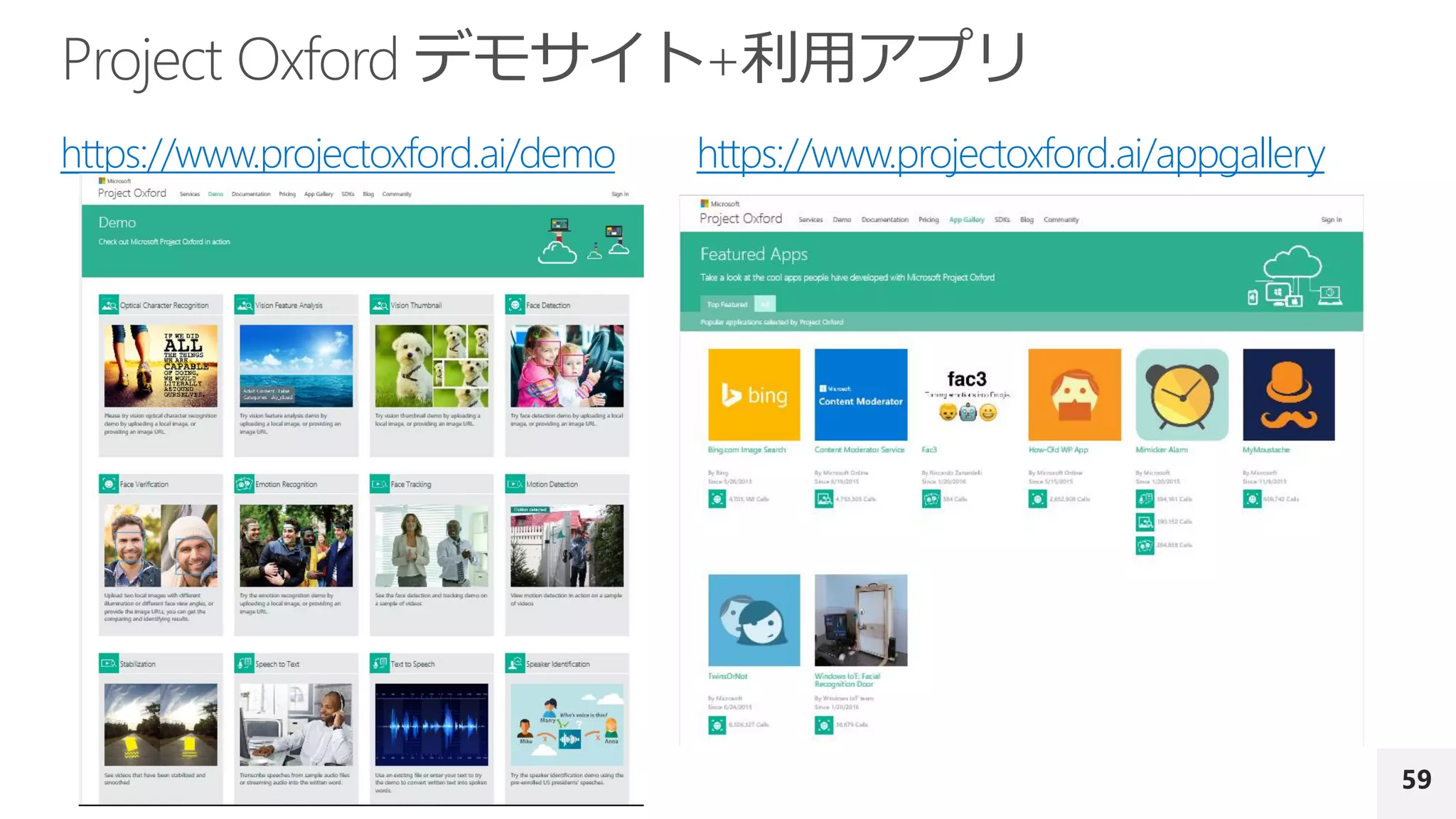
Project
Oxford
Data Catalog
30
• 無償、オープン ソースのR ディストリビューション
• マイクロソフトによって拡張して提供
Microsoft R Open (MRO)
• スケール実行が可能でサポートが受けられる
R ディストリビューション
• マイクロソフトによって作成した特別なコンポーネントを含む
Microsoft R Server (MRS)
31.
31
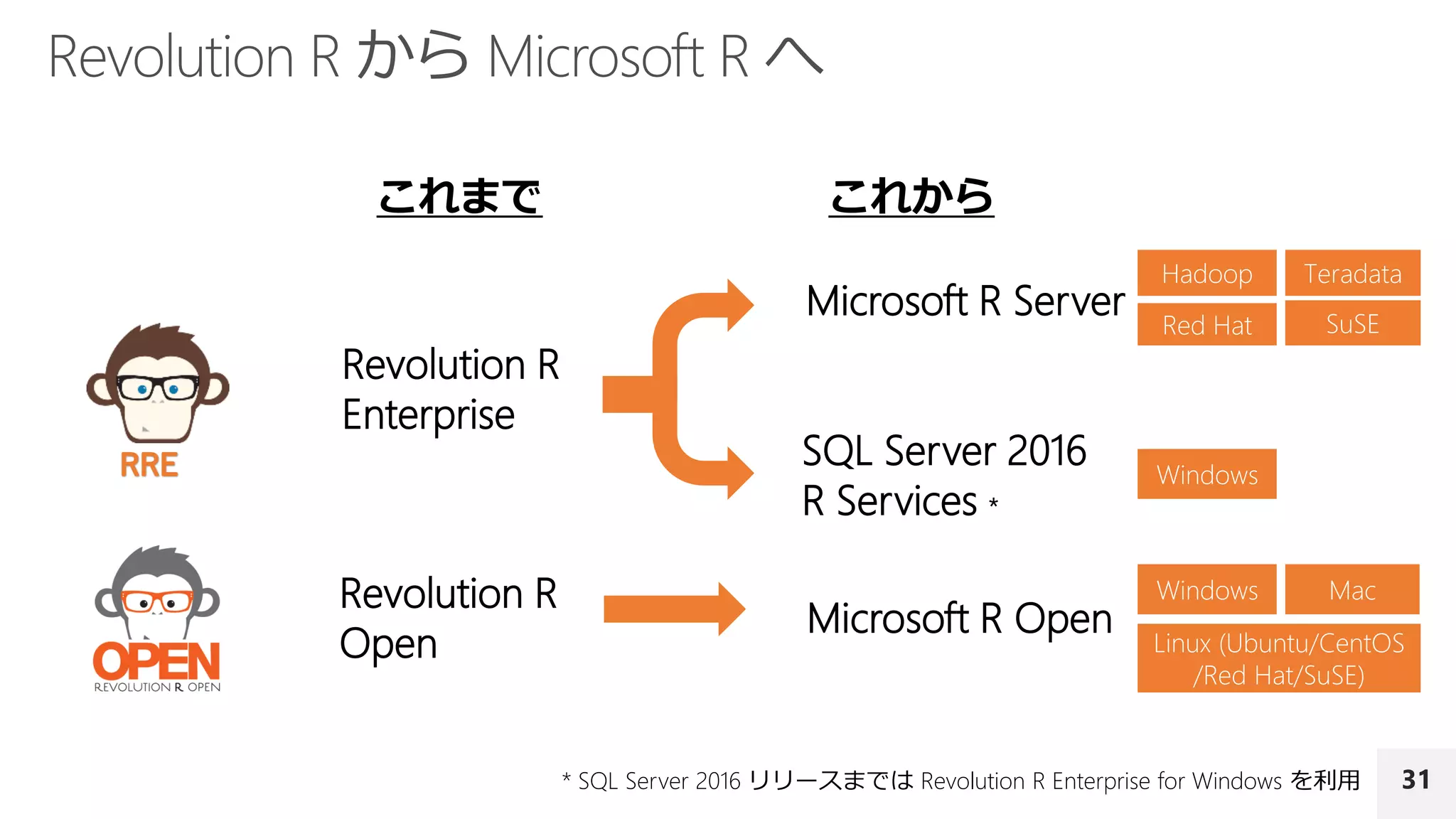
Revolution R
Enterprise
Revolution R
Open
MicrosoftR Server
SQL Server 2016
R Services *
Microsoft R Open
これまで これから
Windows
Hadoop
Red Hat SuSE
Teradata
Linux (Ubuntu/CentOS
/Red Hat/SuSE)
Windows Mac
* SQL Server 2016 リリースまでは Revolution R Enterprise for Windows を利用
33
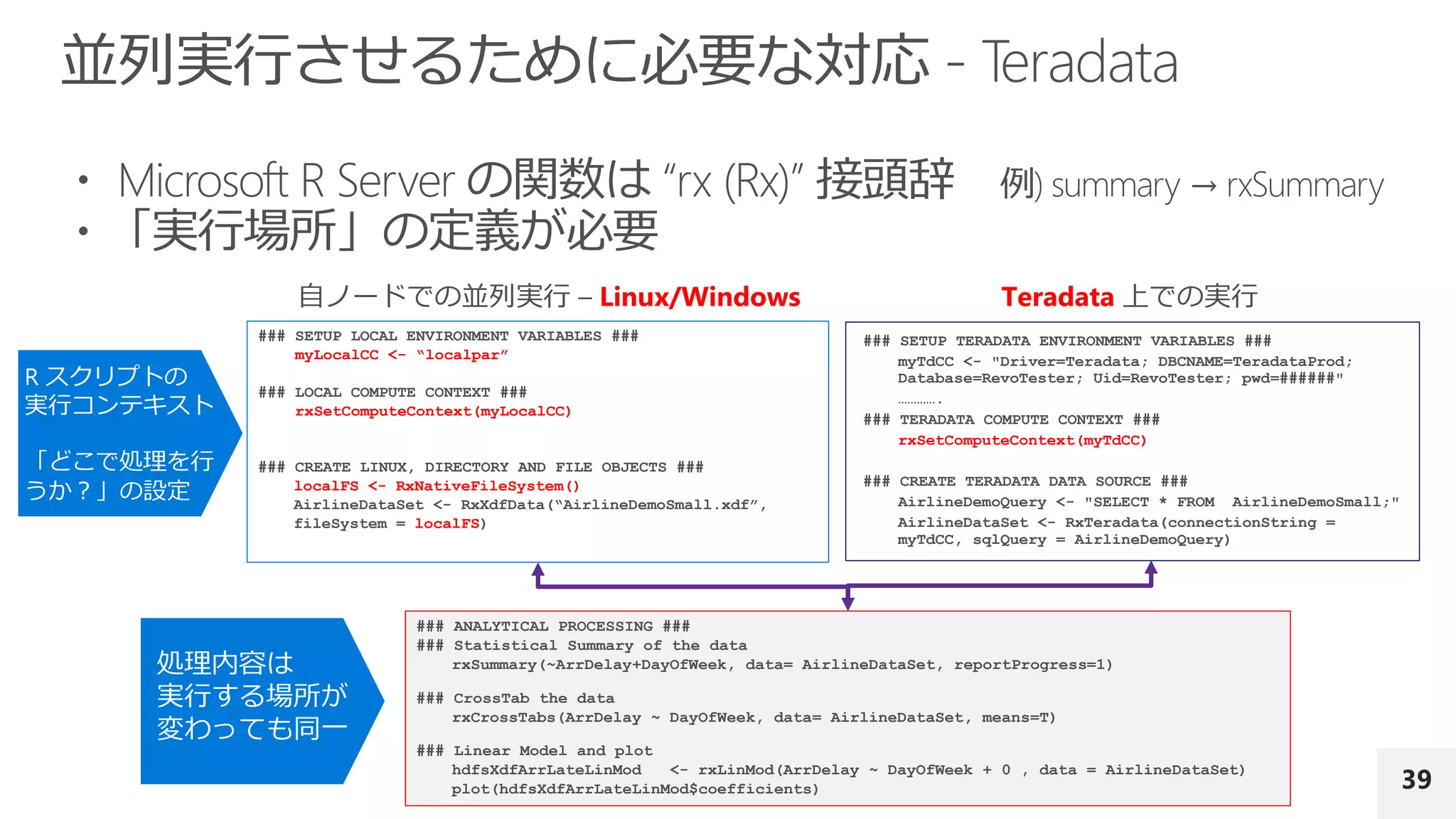
• Microsoft RServer for Red Hat Linux
• Microsoft R Server for SUSE Linux
• Microsoft R Server for Teradata DB
• Microsoft R Server for Hadoop on Red Hat
• RRE for Windows
(Microsoft SQL Server 2014 Enterprise Edition + SA の場合)
Microsoft R Server (MRS)


























































![[db tech showcase Tokyo 2017] E23: クラウド異種データベース(AWS)へのデータベース移行時の注意点 ~レプリケーション...](https://cdn.slidesharecdn.com/ss_thumbnails/e23-170912023826-thumbnail.jpg?width=640&height=640&fit=bounds)
![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180308-180308093647-thumbnail.jpg?width=640&height=640&fit=bounds)



![【ウェブ セミナー】AI / アナリティクスを支えるビッグデータ基盤 Azure Data Lake [概要編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinaradl20180215-180219043331-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] D35: 何を基準に選定すべきなのか!? ~ビッグデータ×IoT×AI時代のデータベースのアー...](https://cdn.slidesharecdn.com/ss_thumbnails/d35-170912024713-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] AzureでOSS DB/データ処理基盤のPaaSサービスを使ってみよう (Azure Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/20170907dbtechshowcaseazureossdb-170907082746-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2017] A32: Attunity Replicate + Kafka + Hadoop マルチデータ...](https://cdn.slidesharecdn.com/ss_thumbnails/attunityreplicatekafkahadoop-170911072451-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase OSS 2017] A24: マイクロソフトと OSS Database - Azure Database for M...](https://cdn.slidesharecdn.com/ss_thumbnails/uikouazurepostgresqlver1-170621081553-thumbnail.jpg?width=640&height=640&fit=bounds)



















































