Downloaded 95 times






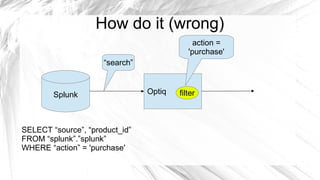
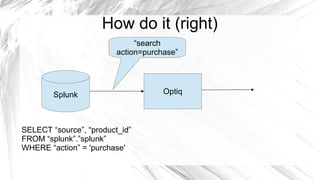

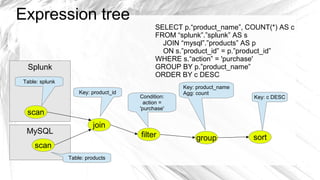
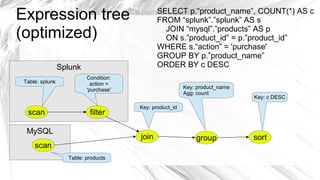



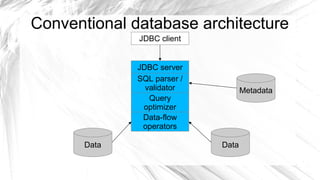
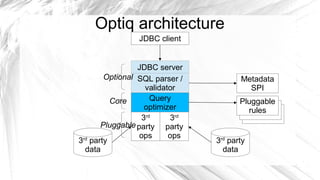








Optiq is a smart JDBC driver framework designed to query data from diverse sources, specifically optimized for use with systems like Splunk and MySQL. It allows for complex queries including joins across multiple data sources without the traditional constraints of conventional database architecture. The roadmap includes integration with various data sources and tools to enhance efficiency and usability.































































































