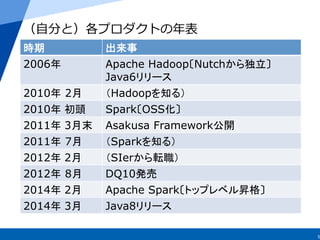
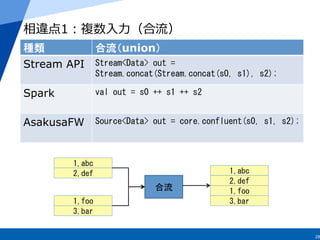
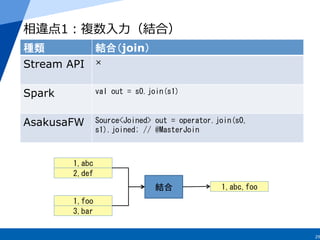
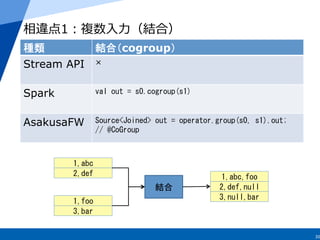
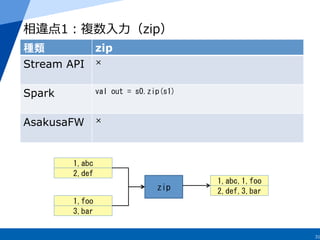
15
Java8 Stream API
MyOperatorの例例
public
class
MyOperator
{
public
boolean
f(Data
data)
{
return
data.getValue()
%
2
==
0;
}
public
Data
m(Data
data)
{
return
new
Data(data.getValue()
+
1);
}
}
19
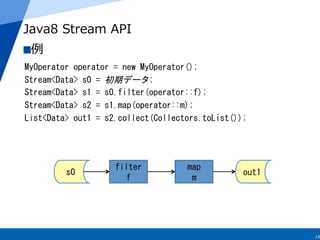
Java8 Stream API
例例
MyOperator
operator
=
new
MyOperator();
Stream<Data>
s0
=
初期データ;
Stream<Data>
s1
=
s0.filter(operator::f);
Stream<Data>
s2
=
s1.map(operator::m);
List<Data>
out1
=
s2.collect(Collectors.toList());
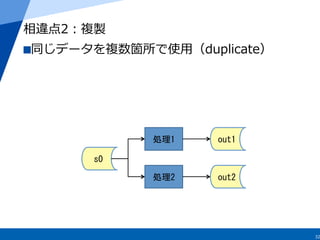
s0
filter
f
map
m
out1
20.
20
Scala
例例
val
operator
=
new
MyOperator
val
s0
:
Stream[Data]
=
初期データ
val
s1
=
s0.filter(operator.f)
val
s2
=
s1.map(operator.m)
val
out1
=
s2.toSeq
s0
filter
f
map
m
out1
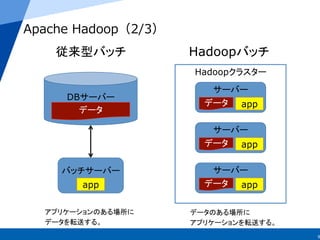
22
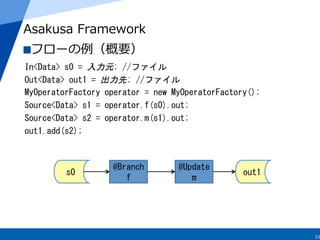
Apache Spark
例例
val
sc
=
new
SparkContext(…)
val
operator
=
new
MyOperator
val
s0
:
RDD[Data]
=
sc.初期データ
val
s1
=
s0.filter(operator.f)
val
s2
=
s1.map(operator.m)
s2.saveAsTextFile(”ファイル名”)
※MyOperatorは通常のScalaと全く同じ
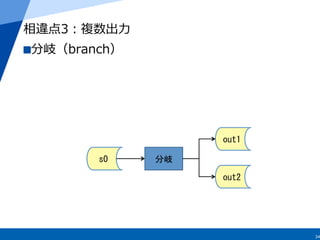
s0
filter
f
map
m
out1















![20
Scala
例例
val
operator
=
new
MyOperator
val
s0
:
Stream[Data]
=
初期データ
val
s1
=
s0.filter(operator.f)
val
s2
=
s1.map(operator.m)
val
out1
=
s2.toSeq
s0
filter
f
map
m
out1](https://image.slidesharecdn.com/stream-spark-asakusafw-151128125119-lva1-app6891/85/Java8-Stream-API-Apache-Spark-Asakusa-Framework-20-320.jpg)

![22
Apache Spark
例例
val
sc
=
new
SparkContext(…)
val
operator
=
new
MyOperator
val
s0
:
RDD[Data]
=
sc.初期データ
val
s1
=
s0.filter(operator.f)
val
s2
=
s1.map(operator.m)
s2.saveAsTextFile(”ファイル名”)
※MyOperatorは通常のScalaと全く同じ
s0
filter
f
map
m
out1](https://image.slidesharecdn.com/stream-spark-asakusafw-151128125119-lva1-app6891/85/Java8-Stream-API-Apache-Spark-Asakusa-Framework-22-320.jpg)








































![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)





































![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)


