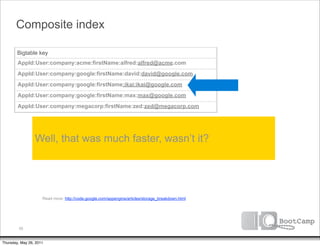
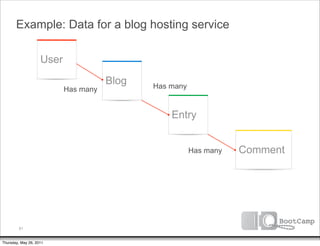
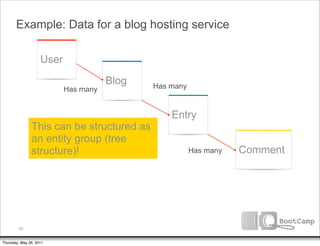
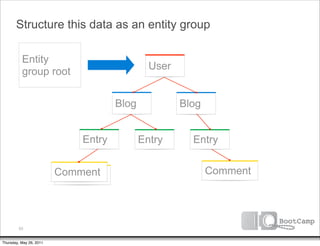
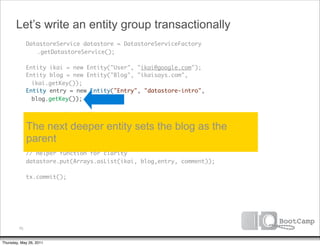
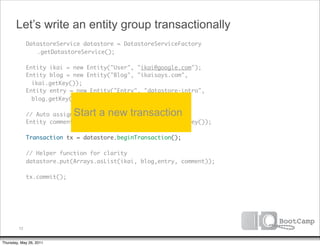
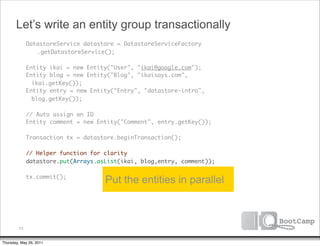
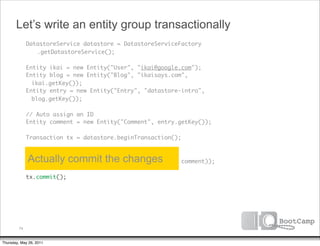
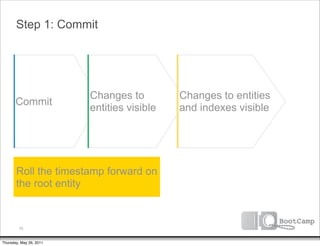
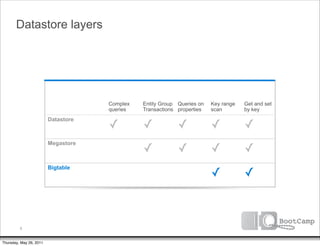
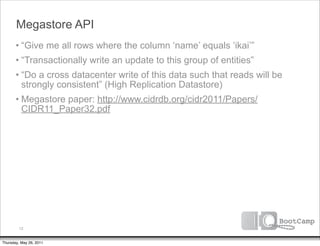
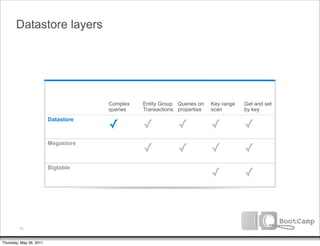
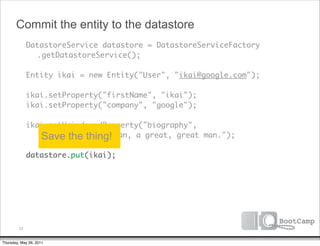
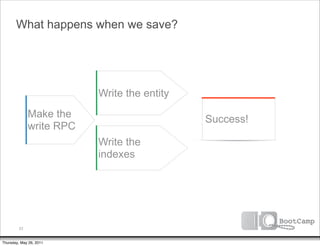
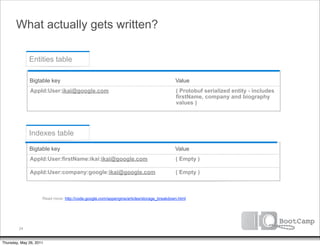
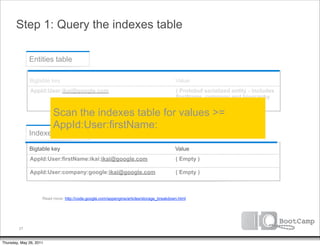
The document discusses a talk given by Ikai Lan about the App Engine Datastore. The talk aimed to provide an understanding of how the datastore works under the hood and conceptual background for a persistence coding lab. It covered topics like the underlying Bigtable infrastructure, indexing and queries, entity groups, and different layers of the datastore including Bigtable, Megastore, and the App Engine Datastore API. It provided examples of saving an entity using the low-level Java API and performing queries on properties using the built-in indexes. Complex queries can be resolved through a zig zag merge join strategy across multiple indexes.


























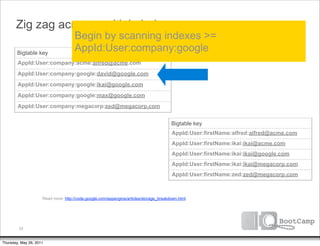


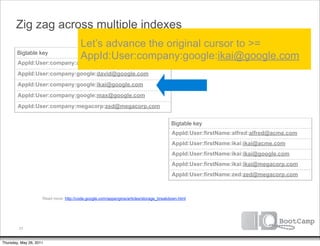
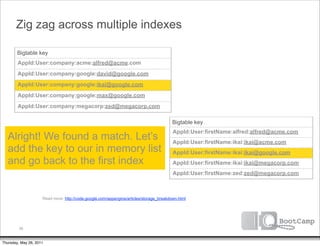
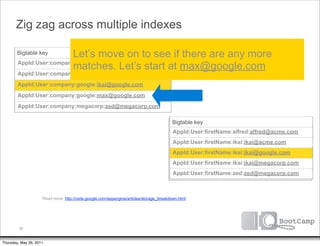
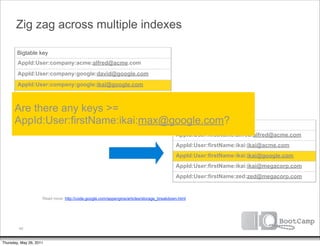
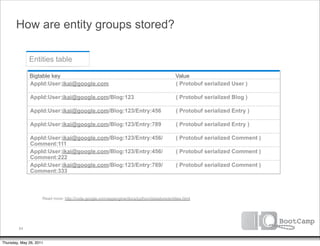
![Zig zag across multiple indexes
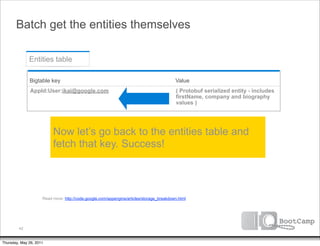
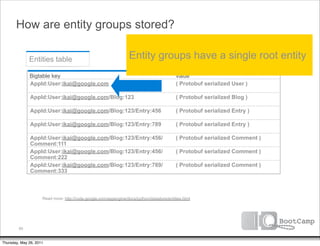
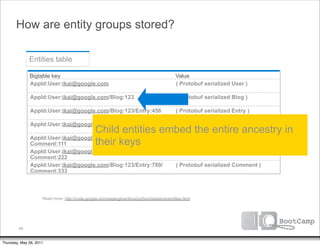
Bigtable key
AppId:User:company:acme:alfred@acme.com
AppId:User:company:google:david@google.com
AppId:User:company:google:ikai@google.com
AppId:User:company:google:max@google.com
AppId:User:company:megacorp:zed@megacorp.com
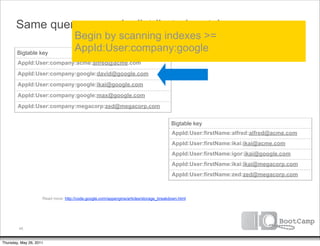
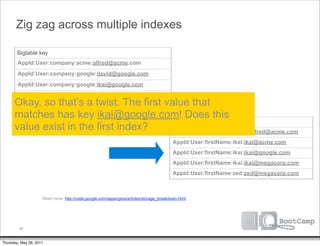
No. We’re at the end of our Bigtable key
index scans. Let’s do a batch AppId:User:firstName:alfred:alfred@acme.com
key of our list of keys: AppId:User:firstName:ikai:ikai@acme.com
AppId:User:firstName:ikai:ikai@google.com
[ ‘ikai@google.com’ ]
AppId:User:firstName:ikai:ikai@megacorp.com
AppId:User:firstName:zed:zed@megacorp.com
Read more: http://code.google.com/appengine/articles/storage_breakdown.html
41
Thursday, May 26, 2011](https://image.slidesharecdn.com/ikaicloudplatformintroducingthedatastore-110526140154-phpapp02/85/Introducing-the-App-Engine-datastore-42-320.jpg)