Downloaded 219 times




![Cypher Syntax - Refresher
MATCH (n:Label)-[r:LINKED]->(m)
WHERE n.prop = "..."
RETURN n, r, m](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-4-320.jpg)

![The 1.9 global scan
O(n)
n = # of nodes
START pl = node(*)
MATCH (pl)-[:played]->(stats)
WHERE pl.name = "Wayne Rooney"
RETURN stats
150ms w/ 30k nodes, 120k rels](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-7-320.jpg)
![The 2.0 global scan
MATCH (pl)-[:played]->(stats)
WHERE pl.name = "Wayne Rooney"
RETURN stats
130ms w/ 30k nodes, 120k rels
O(n)
n = # of nodes](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-8-320.jpg)


![O(k)
k = # of nodes with that labelLabel scan
MATCH (pl:Player)-[:played]->(stats)
WHERE pl.name = "Wayne Rooney"
RETURN stats
80ms w/ 30k nodes, 120k rels (~900 :Player nodes)](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-11-320.jpg)

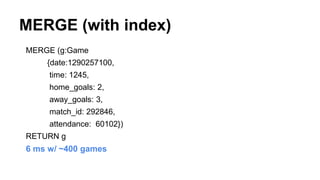
![O(log k)
k = # of nodes with that labelIndex lookup
MATCH (pl:Player)-[:played]->(stats)
WHERE pl.name = "Wayne Rooney"
RETURN stats
6ms w/ 30k nodes, 120k rels (~900 :Player nodes)](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-13-320.jpg)


![Subtle Cartesian Products
MATCH (p:Person)-[:KNOWS]->(c)
WHERE p.name="Tom Hanks"
WITH c
MATCH (k:Keyword)
RETURN c, k](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-17-320.jpg)


![Directions on patterns
MATCH (p:Person)-[:ACTED_IN]-(m)
WHERE p.name = "Tom Hanks"
RETURN m](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-20-320.jpg)
![Parameterize your queries
MATCH (p:Person)-[:ACTED_IN]-(m)
WHERE p.name = {name}
RETURN m](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-21-320.jpg)
![Fast predicates first
Bad:
MATCH (t:Team)-[:played_in]->(g)
WHERE NOT (t)-[:home_team]->(g)
AND g.away_goals > g.home_goals
RETURN t, COUNT(g)](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-22-320.jpg)
![Better:
MATCH (t:Team)-[:played_in]->(g)
WHERE g.away_goals > g.home_goals
AND NOT (t)-[:home_team]->()
RETURN t, COUNT(g)
Fast predicates first](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-23-320.jpg)






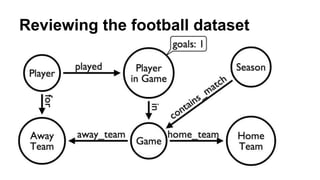
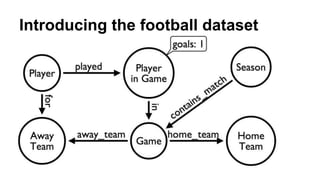
![Football Optimization
MATCH (game)<-[:contains_match]-(season:Season),
(team)<-[:away_team]-(game),
(stats)-[:in]->(game),
(team)<-[:for]-(stats)<-[:played]-(player)
WHERE season.name = "2012-2013"
RETURN player.name,
COLLECT(DISTINCT team.name),
SUM(stats.goals) as goals
ORDER BY goals DESC
LIMIT 103137 ms w/ ~900 players, ~20 teams, ~400 games](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-32-320.jpg)
![Football Optimization
==> ColumnFilter(symKeys=["player.name", " INTERNAL_AGGREGATEe91b055b-a943-4ddd-9fe8-e746407c504a", "
INTERNAL_AGGREGATE240cfcd2-24d9-48a2-8ca9-fb0286f3d323"], returnItemNames=["player.name", "COLLECT(DISTINCT
team.name)", "goals"], _rows=10, _db_hits=0)
==> Top(orderBy=["SortItem(Cached( INTERNAL_AGGREGATE240cfcd2-24d9-48a2-8ca9-fb0286f3d323 of type Number),false)"],
limit="Literal(10)", _rows=10, _db_hits=0)
==> EagerAggregation(keys=["Cached(player.name of type Any)"], aggregates=["( INTERNAL_AGGREGATEe91b055b-a943-4ddd-9fe8-
e746407c504a,Distinct(Collect(Property(team,name(0))),Property(team,name(0))))", "( INTERNAL_AGGREGATE240cfcd2-24d9-48a2-
8ca9-fb0286f3d323,Sum(Property(stats,goals(13))))"], _rows=503, _db_hits=10899)
==> Extract(symKeys=["stats", " UNNAMED12", " UNNAMED108", "season", " UNNAMED55", "player", "team", " UNNAMED124", "
UNNAMED85", "game"], exprKeys=["player.name"], _rows=5192, _db_hits=5192)
==> PatternMatch(g="(player)-[' UNNAMED124']-(stats)", _rows=5192, _db_hits=0)
==> Filter(pred="Property(season,name(0)) == Literal(2012-2013)", _rows=5192, _db_hits=15542)
==> TraversalMatcher(trail="(season)-[ UNNAMED12:contains_match WHERE true AND true]->(game)<-[ UNNAMED85:in WHERE
true AND true]-(stats)-[ UNNAMED108:for WHERE true AND true]->(team)<-[ UNNAMED55:away_team WHERE true AND true]-
(game)", _rows=15542, _db_hits=1620462)](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-33-320.jpg)
![Break out the match statements
MATCH (game)<-[:contains_match]-(season:Season)
MATCH (team)<-[:away_team]-(game)
MATCH (stats)-[:in]->(game)
MATCH (team)<-[:for]-(stats)<-[:played]-(player)
WHERE season.name = "2012-2013"
RETURN player.name,
COLLECT(DISTINCT team.name),
SUM(stats.goals) as goals
ORDER BY goals DESC
LIMIT 10200 ms w/ ~900 players, ~20 teams, ~400 games](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-34-320.jpg)

![Exploring cardinalities
MATCH (game)<-[:contains_match]-(season:Season)
RETURN COUNT(DISTINCT game), COUNT(DISTINCT season)
1140 games, 3 seasons
MATCH (team)<-[:away_team]-(game:Game)
RETURN COUNT(DISTINCT team), COUNT(DISTINCT game)
25 teams, 1140 games](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-36-320.jpg)
![Exploring cardinalities
MATCH (stats)-[:in]->(game:Game)
RETURN COUNT(DISTINCT stats), COUNT(DISTINCT game)
31117 stats, 1140 games
MATCH (stats)<-[:played]-(player:Player)
RETURN COUNT(DISTINCT stats), COUNT(DISTINCT player)
31117 stats, 880 players](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-37-320.jpg)
![Look for teams first
MATCH (team)<-[:away_team]-(game:Game)
MATCH (game)<-[:contains_match]-(season)
WHERE season.name = "2012-2013"
MATCH (stats)-[:in]->(game)
MATCH (team)<-[:for]-(stats)<-[:played]-(player)
RETURN player.name,
COLLECT(DISTINCT team.name),
SUM(stats.goals) as goals
ORDER BY goals DESC
LIMIT 10162 ms w/ ~900 players, ~20 teams, ~400 games](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-38-320.jpg)
![==> ColumnFilter(symKeys=["player.name", " INTERNAL_AGGREGATEbb08f36b-a70d-46b3-9297-b0c7ec85c969", "
INTERNAL_AGGREGATE199af213-e3bd-400f-aba9-8ca2a9e153c5"], returnItemNames=["player.name", "COLLECT(DISTINCT
team.name)", "goals"], _rows=10, _db_hits=0)
==> Top(orderBy=["SortItem(Cached( INTERNAL_AGGREGATE199af213-e3bd-400f-aba9-8ca2a9e153c5 of type Number),false)"],
limit="Literal(10)", _rows=10, _db_hits=0)
==> EagerAggregation(keys=["Cached(player.name of type Any)"], aggregates=["( INTERNAL_AGGREGATEbb08f36b-a70d-46b3-9297-
b0c7ec85c969,Distinct(Collect(Property(team,name(0))),Property(team,name(0))))", "( INTERNAL_AGGREGATE199af213-e3bd-400f-
aba9-8ca2a9e153c5,Sum(Property(stats,goals(13))))"], _rows=503, _db_hits=10899)
==> Extract(symKeys=["stats", " UNNAMED12", " UNNAMED168", "season", " UNNAMED125", "player", "team", " UNNAMED152", "
UNNAMED51", "game"], exprKeys=["player.name"], _rows=5192, _db_hits=5192)
==> PatternMatch(g="(stats)-[' UNNAMED152']-(team),(player)-[' UNNAMED168']-(stats)", _rows=5192, _db_hits=0)
==> PatternMatch(g="(stats)-[' UNNAMED125']-(game)", _rows=10394, _db_hits=0)
==> Filter(pred="Property(season,name(0)) == Literal(2012-2013)", _rows=380, _db_hits=380)
==> PatternMatch(g="(season)-[' UNNAMED51']-(game)", _rows=380, _db_hits=1140)
==> TraversalMatcher(trail="(game)-[ UNNAMED12:away_team WHERE true AND true]->(team)", _rows=1140,
_db_hits=1140)
Look for teams first](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-39-320.jpg)
![Filter games a bit earlier
MATCH (game)<-[:contains_match]-(season:Season)
WHERE season.name = "2012-2013"
MATCH (team)<-[:away_team]-(game)
MATCH (stats)-[:in]->(game)
MATCH (team)<-[:for]-(stats)<-[:played]-(player)
RETURN player.name,
COLLECT(DISTINCT team.name),
SUM(stats.goals) as goals
ORDER BY goals DESC
LIMIT 10148 ms w/ ~900 players, ~20 teams, ~400 games](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-40-320.jpg)
![Filter out stats with no goals
MATCH (game)<-[:contains_match]-(season:Season)
WHERE season.name = "2012-2013"
MATCH (team)<-[:away_team]-(game)
MATCH (stats)-[:in]->(game)WHERE stats.goals > 0
MATCH (team)<-[:for]-(stats)<-[:played]-(player)
RETURN player.name,
COLLECT(DISTINCT team.name),
SUM(stats.goals) as goals
ORDER BY goals DESC
LIMIT 10
59 ms w/ ~900 players, ~20 teams, ~400 games](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-41-320.jpg)
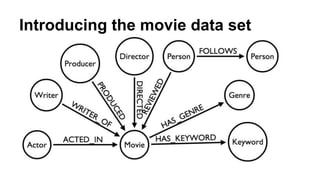
![Movie query optimization
MATCH (movie:Movie {title: {title} })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-42-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-43-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })MATCH (genre)<-[:HAS_GENRE]-
(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-44-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)MATCH (director)-[:DIRECTED]-
>(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-45-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)MATCH (actor)-[:ACTED_IN]-
>(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-46-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)MATCH (writer)-[:WRITER_OF]-
>(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-47-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)MATCH (actor)-[:ACTED_IN]-
>(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-48-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)MATCH
(movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-49-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)WITH DISTINCT movies as related,
count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writersORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors, movie,
collect(DISTINCT {related: {title: related.title}, weight: weight}) as related, genres,
directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-50-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESCWITH collect(DISTINCT {name: actor.name, weight:
actormoviesweight}) as actors,
movie, collect(DISTINCT {related: {title: related.title}, weight: weight}) as
related, genres, directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-51-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors,
movie, collect(DISTINCT {related: {title: related.title}, weight: weight}) as
related, genres, directors, writersMATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-
[:HAS_KEYWORD]-(movies)
WITH keyword.name as keyword, count(movies) as keyword_weight, movie, related, actors,
genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-52-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })
MATCH (genre)<-[:HAS_GENRE]-(movie)
MATCH (director)-[:DIRECTED]->(movie)
MATCH (actor)-[:ACTED_IN]->(movie)
MATCH (writer)-[:WRITER_OF]->(movie)
MATCH (actor)-[:ACTED_IN]->(actormovies)
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword) as weight,
count(DISTINCT actormovies) as actormoviesweight, movie, collect(DISTINCT genre.name) as
genres, collect(DISTINCT director.name) as directors, actor, collect(DISTINCT writer.name)
as writers
ORDER BY weight DESC, actormoviesweight DESC
WITH collect(DISTINCT {name: actor.name, weight: actormoviesweight}) as actors,
movie, collect(DISTINCT {related: {title: related.title}, weight: weight}) as
related, genres, directors, writers
MATCH (movie)-[:HAS_KEYWORD]->(keyword:Keyword)<-[:HAS_KEYWORD]-(movies)WITH keyword.name as keyword,
count(movies) as keyword_weight, movie, related,
actors, genres, directors, writers
ORDER BY keyword_weight
RETURN collect(DISTINCT keyword), movie, actors, related, genres, directors, writers](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-53-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight // 1 row per actor
ORDER BY actormoviesweight DESC
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie, genres,
directors, actors, writers // 1 row per related movie
ORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as related,
movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-54-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight // 1 row per actor
ORDER BY actormoviesweight DESC
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie, genres,
directors, actors, writers // 1 row per related movie
ORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as related,
movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-55-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)WITH movie, actor, length((actor)-[:ACTED_IN]-
>()) as actormoviesweight
ORDER BY actormoviesweight DESC // 1 row per actor
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie, genres,
directors, actors, writers // 1 row per related movie
ORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as related,
movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-56-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight
ORDER BY actormoviesweight DESC // 1 row per actorWITH movie, collect({name: actor.name, weight:
actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie, genres,
directors, actors, writers // 1 row per related movie
ORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as related,
movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-57-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight
ORDER BY actormoviesweight DESC // 1 row per actor
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row MATCH (movie)-[:HAS_GENRE]-
>(genre)
WITH movie, actors, collect(genre) as genres // 1 row MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie, genres,
directors, actors, writers // 1 row per related movie
ORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as related,
movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-58-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight
ORDER BY actormoviesweight DESC // 1 row per actor
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row MATCH (movie)-[:HAS_KEYWORD]-
>(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie,
genres, directors, actors, writers // 1 row per related movieORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as related,
movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-59-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight
ORDER BY actormoviesweight DESC // 1 row per actor
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie,
genres, directors, actors, writers // 1 row per related movie
ORDER BY keywords DESCWITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as
related, movie, actors, genres, directors, writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors, writers
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-60-320.jpg)
![Movie query optimization
MATCH (movie:Movie {title: 'The Matrix' })<-[:ACTED_IN]-(actor)
WITH movie, actor, length((actor)-[:ACTED_IN]->()) as actormoviesweight
ORDER BY actormoviesweight DESC // 1 row per actor
WITH movie, collect({name: actor.name, weight: actormoviesweight}) as actors // 1 row
MATCH (movie)-[:HAS_GENRE]->(genre)
WITH movie, actors, collect(genre) as genres // 1 row
MATCH (director)-[:DIRECTED]->(movie)
WITH movie, actors, genres, collect(director.name) as directors // 1 row
MATCH (writer)-[:WRITER_OF]->(movie)
WITH movie, actors, genres, directors, collect(writer.name) as writers // 1 row
MATCH (movie)-[:HAS_KEYWORD]->(keyword)<-[:HAS_KEYWORD]-(movies:Movie)
WITH DISTINCT movies as related, count(DISTINCT keyword.name) as keywords, movie,
genres, directors, actors, writers // 1 row per related movie
ORDER BY keywords DESC
WITH collect(DISTINCT { related: { title: related.title }, weight: keywords }) as
related, movie, actors, genres, directors, writers // 1 rowMATCH (movie)-[:HAS_KEYWORD]->(keyword)
RETURN collect(keyword.name) as keywords, related, movie, actors, genres, directors,
writers // 1 row
10x faster](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-61-320.jpg)

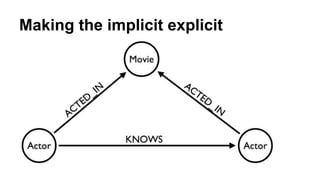

![Good:
MATCH (s:Season)-[:contains]->(g)
WHERE season.name = "2012-2013"
RETURN g
Refactor property to node](https://image.slidesharecdn.com/optimizingcypher-140320144040-phpapp01/85/Optimizing-Cypher-Queries-in-Neo4j-68-320.jpg)




The document discusses optimizing Cypher queries in Neo4j, covering syntax, query patterns, and profiling techniques. It emphasizes strategies such as label indexing, avoiding cartesian products, and efficient use of match patterns to improve query performance. Analyzing both football and movie datasets, the document illustrates the impact of optimization on query execution times.







































![Neo4j -[:LOVES]-> Cypher](https://cdn.slidesharecdn.com/ss_thumbnails/geekoutpublish-120615074720-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[Webinar] RDBMS to Graph](https://cdn.slidesharecdn.com/ss_thumbnails/august2017rdbmstograph-170810130303-thumbnail.jpg?width=640&height=640&fit=bounds)





























![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)














