Download to read offline





















![Implementation concerns 2
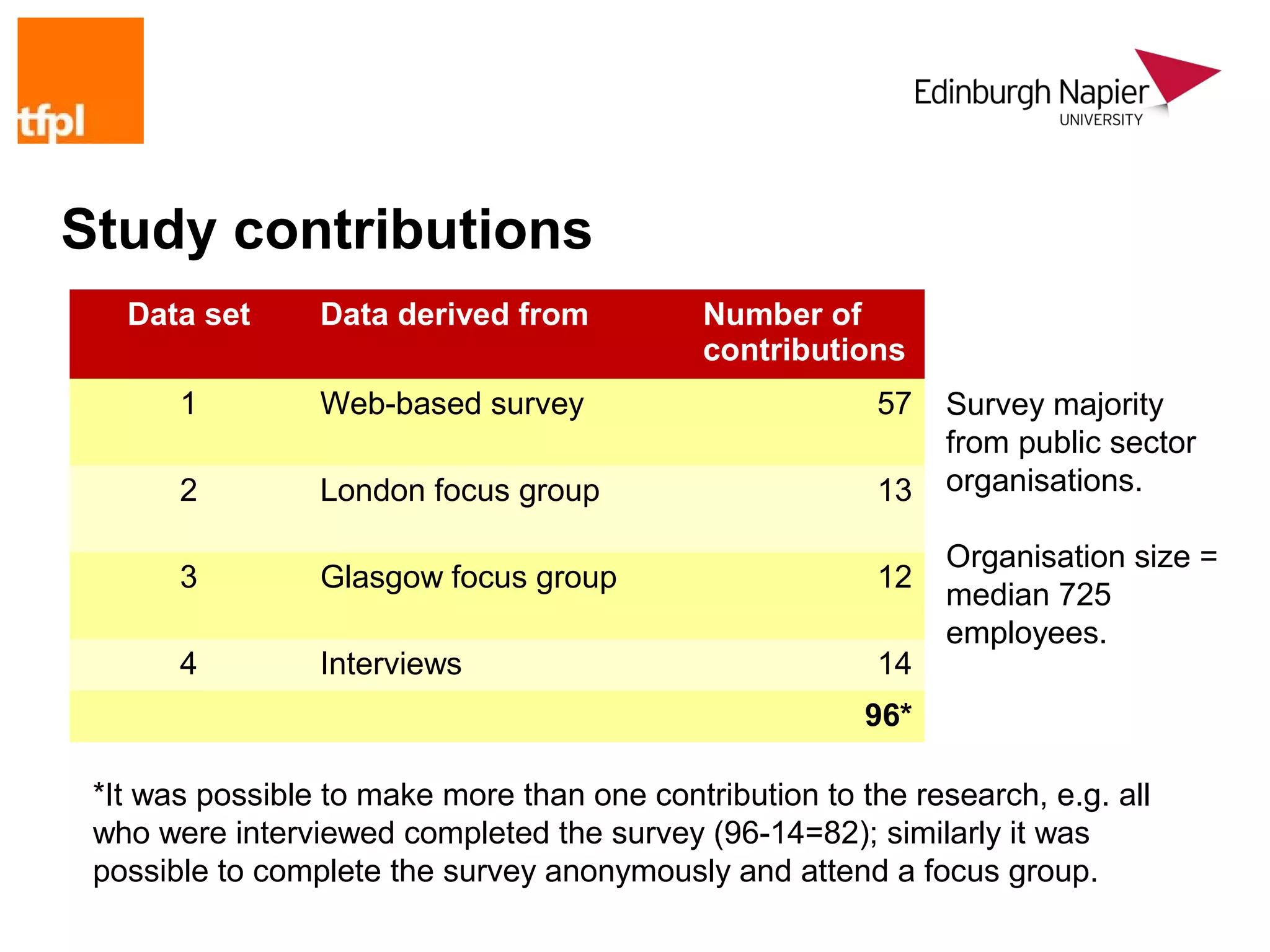
Biggest risk
Failure to capitalise on opportunities offered by social computing
tools due to poor implementation management
Respondents familiar with this risk from earlier experiences, e.g.
intranet developments from mid-90s onwards
This risk is not considered in the literature
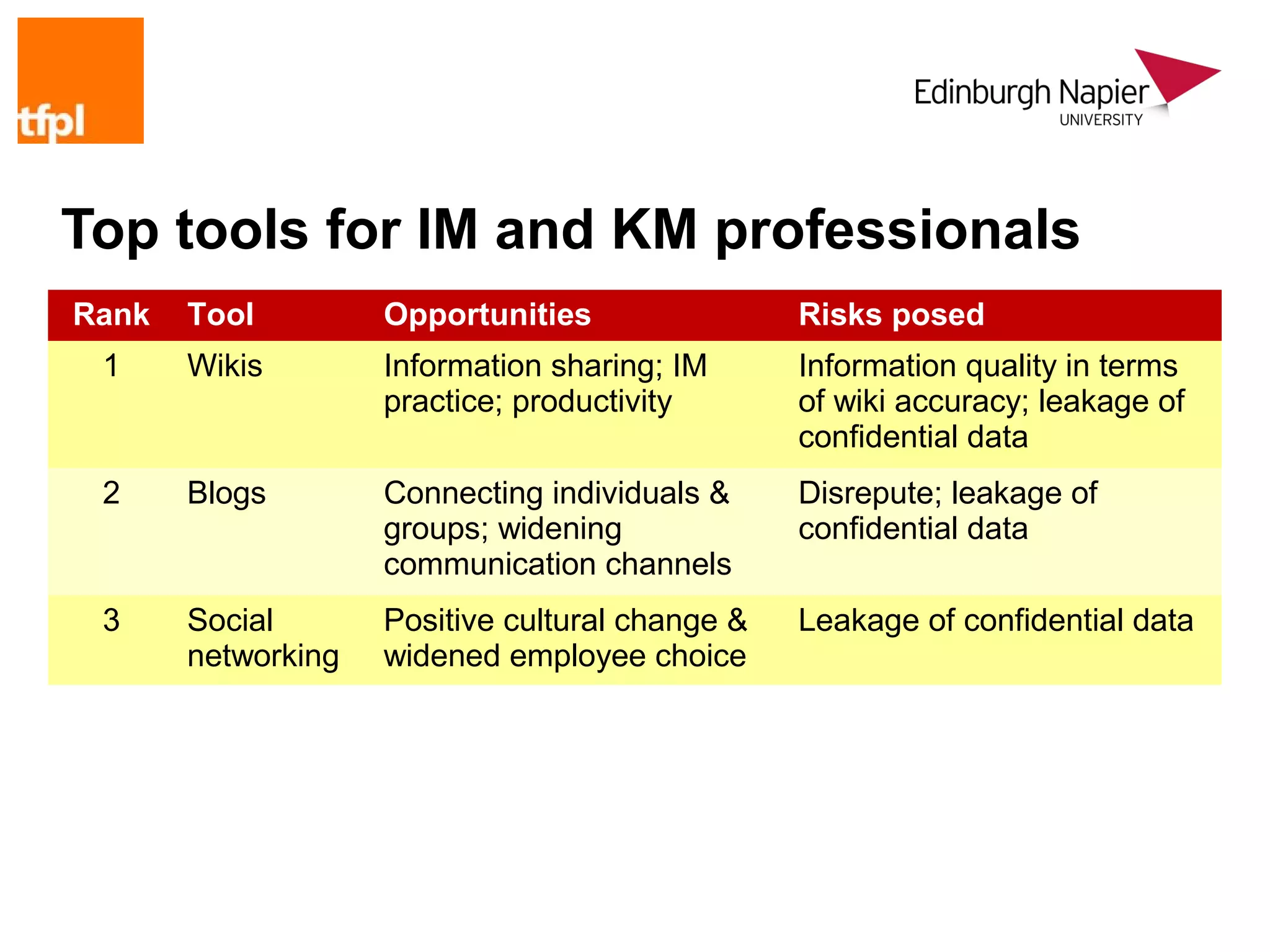
“Like most things it’s about cultural change. A tool (however clever)
can be used well/badly. Therefore usual considerations apply
around what purpose does it serve, selling it to the business,
understanding business benefits/risks, giving staff skills to use
[it/them] properly, providing standards and guidance around use,
encouraging good practice.”](https://image.slidesharecdn.com/2009halloppriskslamontreal-130109050250-phpapp01/75/Opportunity-and-risk-in-social-computing-environments-24-2048.jpg)




![Tool availability, usefulness & usage
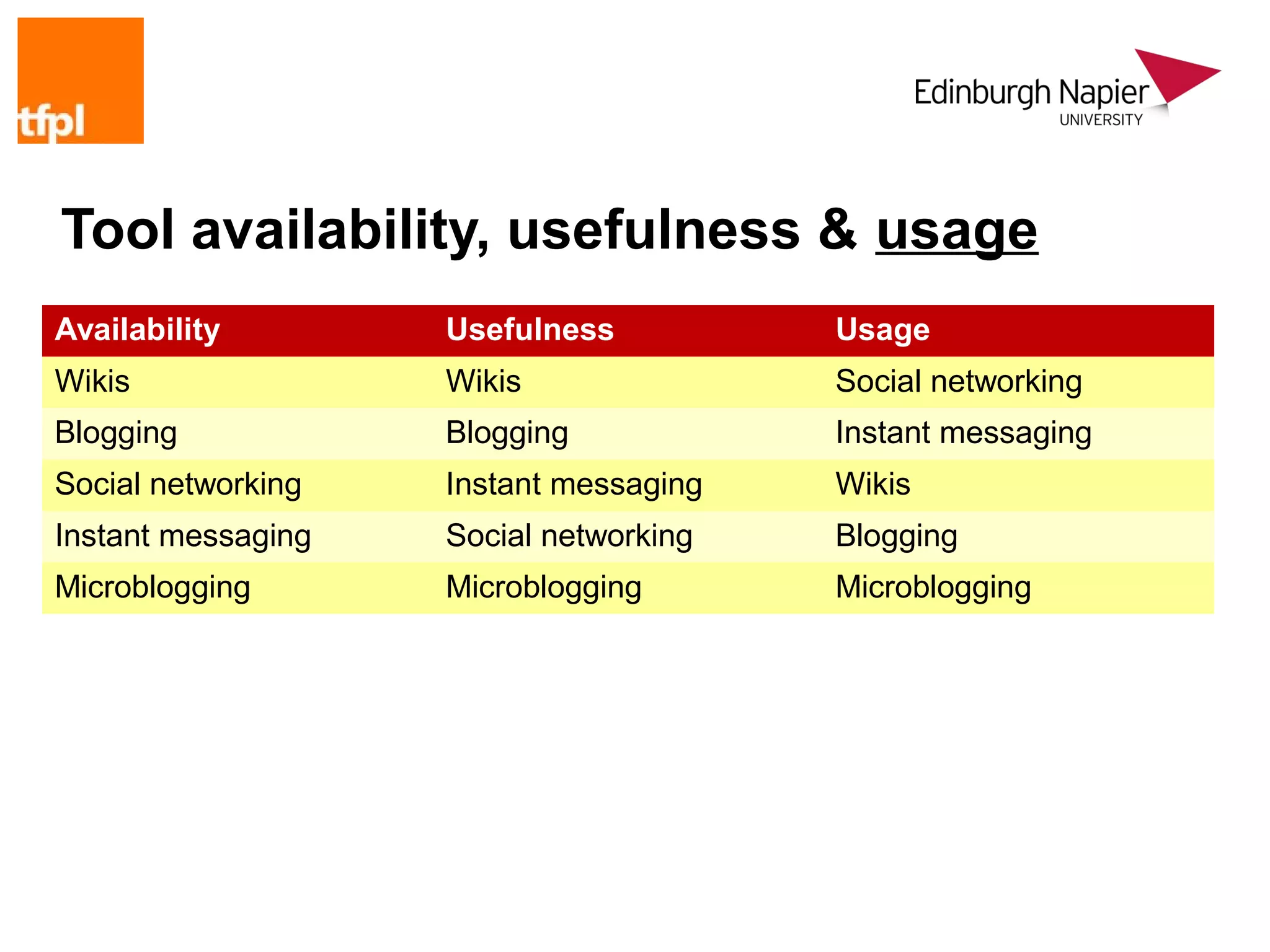
Availability Usefulness Usage
Wikis Wikis Social networking
Blogging Blogging Instant messaging
Social networking Instant messaging Wikis
Instant messaging Social networking Blogging
Microblogging Microblogging Microblogging
Ready availability of a tool does not guarantee popularity
Under-exploitation of most valuable tools?
“[All of the tools] support [collaboration] in different ways and are
limited mainly because of uptake rather than limitations of the tool
itself”
Microblogging barely on the radar, yet consider its offerings…](https://image.slidesharecdn.com/2009halloppriskslamontreal-130109050250-phpapp01/75/Opportunity-and-risk-in-social-computing-environments-31-2048.jpg)










The document outlines research conducted by the Centre for Social Informatics at Edinburgh Napier University on the opportunities and risks of social computing tools in organizational collaborative work. It addresses the varying levels of adoption and perceived benefits and concerns about social computing within information and knowledge management professionals. The study emphasizes the importance of effective implementation and management of these tools to capitalize on their potential advantages while mitigating associated risks.






















































































