
























































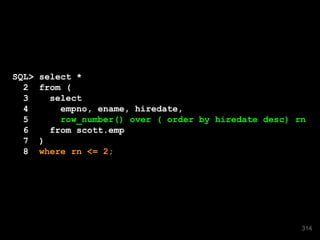
![[after DML and time passing]
SQL> select * from EMP
2 AS OF TIMESTAMP SYSDATE-365;
-----------------------------------------------------------------
| Id | Operation | Name | Rows |
-----------------------------------------------------------------
| 0 | SELECT STATEMENT | | 446 |
| 1 | VIEW | | 446 |
| 2 | UNION-ALL | | |
|* 3 | FILTER | | |
| 4 | PARTITION RANGE ITERATOR| | 445 |
|* 5 | TABLE ACCESS FULL | SYS_FBA_HIST_69539 | 445 |
|* 6 | FILTER | | |
|* 7 | HASH JOIN OUTER | | 1 |
|* 8 | TABLE ACCESS FULL | EMP | 1 |
|* 9 | TABLE ACCESS FULL | SYS_FBA_TCRV_69539 | 14 |
------------------------------------------------------------------
60](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-60-320.jpg)



















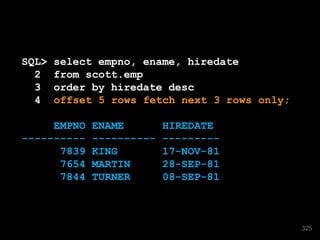
![SQL> alter table EMP add UPDATED_BY varchar2(10);
Table altered.
SQL> alter table EMP add UPDATED_PGM varchar2(10);
Table altered.
[etc]
[etc]
80](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-80-320.jpg)

































































































































































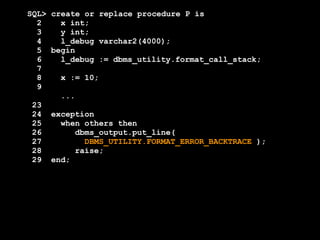






















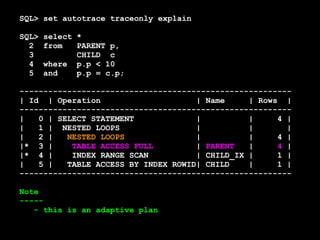
![SQL> create or replace
2 function my_initcap(p_string varchar2) return varchar2 is
3 l_string varchar2(1000) := p_string;
4 begin
5 if regexp_like(l_string,'(Mac[A-Z]|Mc[A-Z])') then
6 null;
7 elsif l_string like '''%' then
8 null;
9 else
10 l_string := initcap(l_string);
11 if l_string like '_''S%' then
12 null;
13 else
14 l_string := replace(l_string,'''S','''s');
15 end if;
16 end if;
17
18 return l_string;
19 end;
20 /
Function created.](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-272-320.jpg)







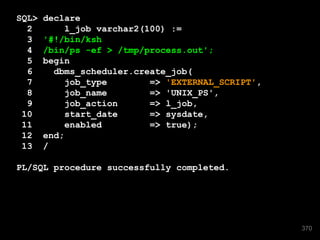
![SQL> select
2 case
3 when regexp_like(vendor,'(Mac[A-Z]|Mc[A-Z])') then vendor
4 when vendor like '''%' then vendor
5 when initcap(vendor) like '_''S%' then vendor
6 else replace(initcap(vendor),'''S','''s')
7 end ugh
8 from service_provider;
UGH
-------------------------------
Jones
Brown
Smith
McDonald
Johnson's](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-280-320.jpg)


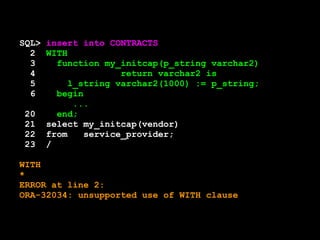
![SQL> WITH
2 function my_initcap(p_string varchar2)
3 return varchar2 is
4 l_string varchar2(1000) := p_string;
5 begin
6 if regexp_like(l_string,'(Mac[A-Z]|Mc[A-Z])') then
7 null;
8 elsif l_string like '''%' then
...
17
18 return l_string;
19 end;
20 select my_initcap(vendor)
21 from service_provider;
MY_INITCAP(VENDOR)
-----------------------------------------
Jones
Brown
Smith
McDonald
O'Brien
Johnson's](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-283-320.jpg)

![SQL> WITH
2 function is_scottish(p_string varchar2) return boolean is
3 begin
4 return regexp_like(p_string,'(Mac[A-Z]|Mc[A-Z])');
5 end;
6 function my_initcap(p_string varchar2) return varchar2 is
7 l_string varchar2(1000) := p_string;
8 begin
9 if is_scottish(l_string) then
10 null;
11 elsif l_string like '''%' then
12 null;
13 else
14 l_string := initcap(l_string);
15 if l_string like '_''S%' then
16 null;
17 else
18 l_string := replace(l_string,'''S','''s');
19 end if;
20 end if;
21
22 return l_string;
23 end;
24 select my_initcap(surname)
25 from names;
26 /](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-285-320.jpg)


![SQL> WITH
2 function my_initcap(p_string varchar2) return varchar2 is
3 l_string varchar2(1000) := p_string;
function my_initcap(p_string varchar2) return varchar2 is
*
ERROR at line 2:
ORA-06553: PLS-103: Encountered the symbol "end-of-file" when
expecting one of the following:
. ( * @ % & = - + ; < / > at in is mod remainder not rem
<an exponent (**)> <> or != or ~= >= <= <> and or like like2
like4 likec between || multiset member submultiset
SQL> begin
2 if regexp_like(l_string,'(Mac[A-Z]|Mc[A-Z])') then
3 null;
4 elsif l_string like '''%' then
5 null;
6 else
7 l_string := initcap(l_string);](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-288-320.jpg)












































































![# cat CDB12_j000_4559.trc
[snip]
ORA-12012: error on auto execute of job "SCOTT"."UNIX_PS"
ORA-27451: CREDENTIAL_NAME cannot be NULL
371](https://image.slidesharecdn.com/sep1412cfordevelopers-140930190413-phpapp01/85/OpenWorld-Sep14-12c-for_developers-371-320.jpg)














































This document discusses features of Oracle Database 12c related to auditing and tracking changes over time. It summarizes that Oracle 12c includes flashback data archive, which allows viewing or restoring data to a previous state. This feature can be used for auditing and tracking changes made to database tables. The document also discusses how Oracle 12c captures additional context metadata with each change, including user, host, and program used, allowing more detailed tracking of changes than prior releases.























































































