Downloaded 16 times






![6 of 44
Who benefits?
Implementations:
Management-oriented approach
Key question: “Who done it?”
Solution: Try to preserve every line change and associate it with a
specific person foremost forensic tool [blaming game?!]
Problem: Large systems are quickly overwhelmed by the total volume
of micro-changes.
Development-oriented approach
Key question: “How do we create the next release?”
Solution: Managing macro-changes instead of micro-changes
Problem: Requires a different level of organization](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-6-320.jpg)




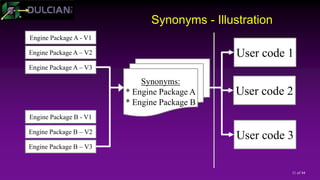






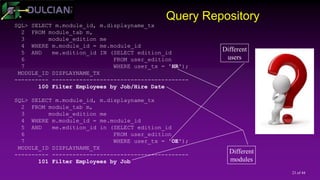
![20 of 44
Data Model
MODULE_TAB
module_id NUMBER [PK]
displayName_tx VARCHAR2(256)
module_tx VARCHAR2(50)
v1_label_tx VARCHAR2(100)
v1_type_tx VARCHAR2(50)
v1_required_yn VARCHAR2(1)
v1_lov_tx VARCHAR2(50)
v1_convert_tx VARCHAR2(50)
v2_label_tx VARCHAR2(100)
v2_type_tx VARCHAR2(50)
v2_required_yn VARCHAR2(1)
v2_lov_tx VARCHAR2(50)
v2_convert_tx VARCHAR2(50)
EDITION_TAB
edition_id NUMBER [PK]
name_tx VARCHAR2(50)
edition_rfk NUMBER
MODULE_EDITION
module_edition_id NUMBER [PK]
module_id NUMBER
edition_id NUMBER
0..* 0..*
0..1
0..*
USER_EDITION
user_edition_id NUMBER [PK]
user_tx NUMBER,
edition_id NUMBER
1
0..*](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-20-320.jpg)


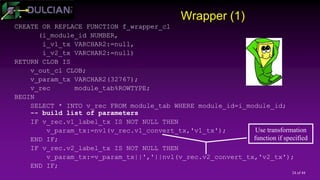
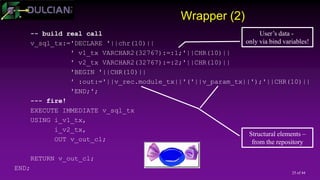



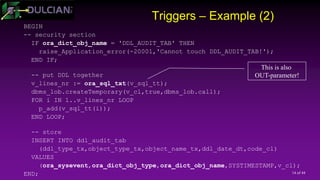
![29 of 44
What is EBR(1)?
Enabling editions:
Done for a specified user (when user created or via ALTER
USER)
Editionable objects are uniquely identified by name and edition
Multiple versions of the same object may exist at the same time
Different data dictionary views
Editions are shared across the database.
You need to have at least one edition (default =ORA$BASE)
Editions are linked in a chain (ORA$BASE – Edition 1 – Edition 2)
11g/12.1 - All other editions are children/[grand]children of ORA$BASE.
12.2 - You can drop all earlier editions (not just intermittent) and have a new
root.](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-29-320.jpg)
![30 of 44
What is EBR(2)?
One current edition in the session
… but you can change it with ALTER SESSION.
For the new session – the current edition is
… either the default [ALTER DATABASE DEFAULT EDITION…]
… or explicitly specified in the connection string.
Special editioning views and cross-edition triggers
Fire different code in Parent/Child edition
Synch data during transition period](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-30-320.jpg)


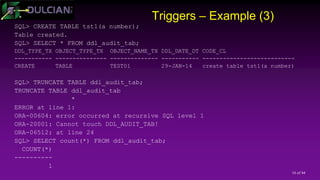
![33 of 44
Key Improvements in Oracle 12.1 (1)
Changed granularity of what can/cannot be editioned
11gR2: Editioned-enabled schema means that ALL
types/objects become editioned.
12c: You can edition-enable only some objects/types of objects:
ALTER USER user ENABLE EDITIONS [ FOR type [, type ]...
]](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-33-320.jpg)

![35 of 44
Other Improvements in Oracle 12c
New clauses for materialized views and virtual columns
=> more functionality
-- [ evaluation_edition_clause ]
EVALUATE USING { CURRENT EDITION | EDITION edition |
NULL EDITION }
-- [ unusable_before_clause ]
UNUSABLE BEFORE { CURRENT EDITION | EDITION edition }
-- [ unusable_beginning_clause ]
UNUSABLE BEGINNING WITH {CURRENT EDITION | EDITION
edition| NULL EDITION}](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-35-320.jpg)







![43 of 44
Summary
Fixing problems in existing systems is one of the main development
tasks in any organization.
… so, you have to think about code management from the very beginning.
Logical notion of “editions” helps thinking about code deployments
… whether you use EBR or not.
Some concepts are common:
Micro-managing your changes <> good code versioning
Performance problems are resolved only when they are deployed to PROD
and there are no side effects.
Successful code versioning leads to better overall system performance.
The best way to validate performance is to have old/new code coexist at the
same time [hint: EBR!]](https://image.slidesharecdn.com/2017415rosenblumpptcode-170405182159/85/Developer-s-Approach-to-Code-Management-43-320.jpg)


The document discusses code management challenges, emphasizing the lack of consensus on definitions and the importance of understanding how code transforms over time. It presents the developer-oriented approach focusing on macro changes, techniques like synonym manipulation, database triggers, and a localized repository-based solution for efficient versioning. Additionally, it addresses the implications of Oracle's edition-based redefinition (EBR) feature for managing code in production environments.
































































