Download as PDF, PPTX



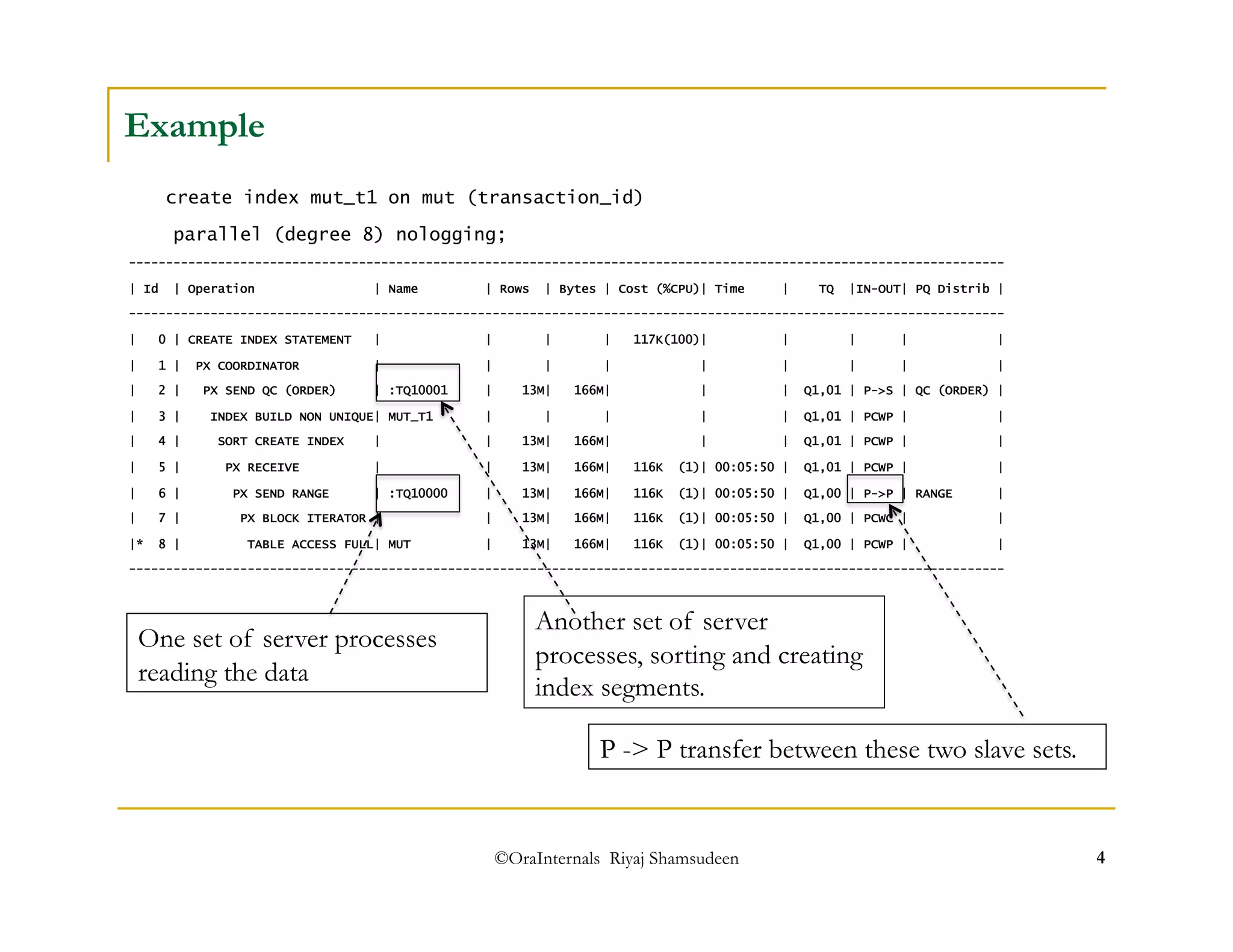



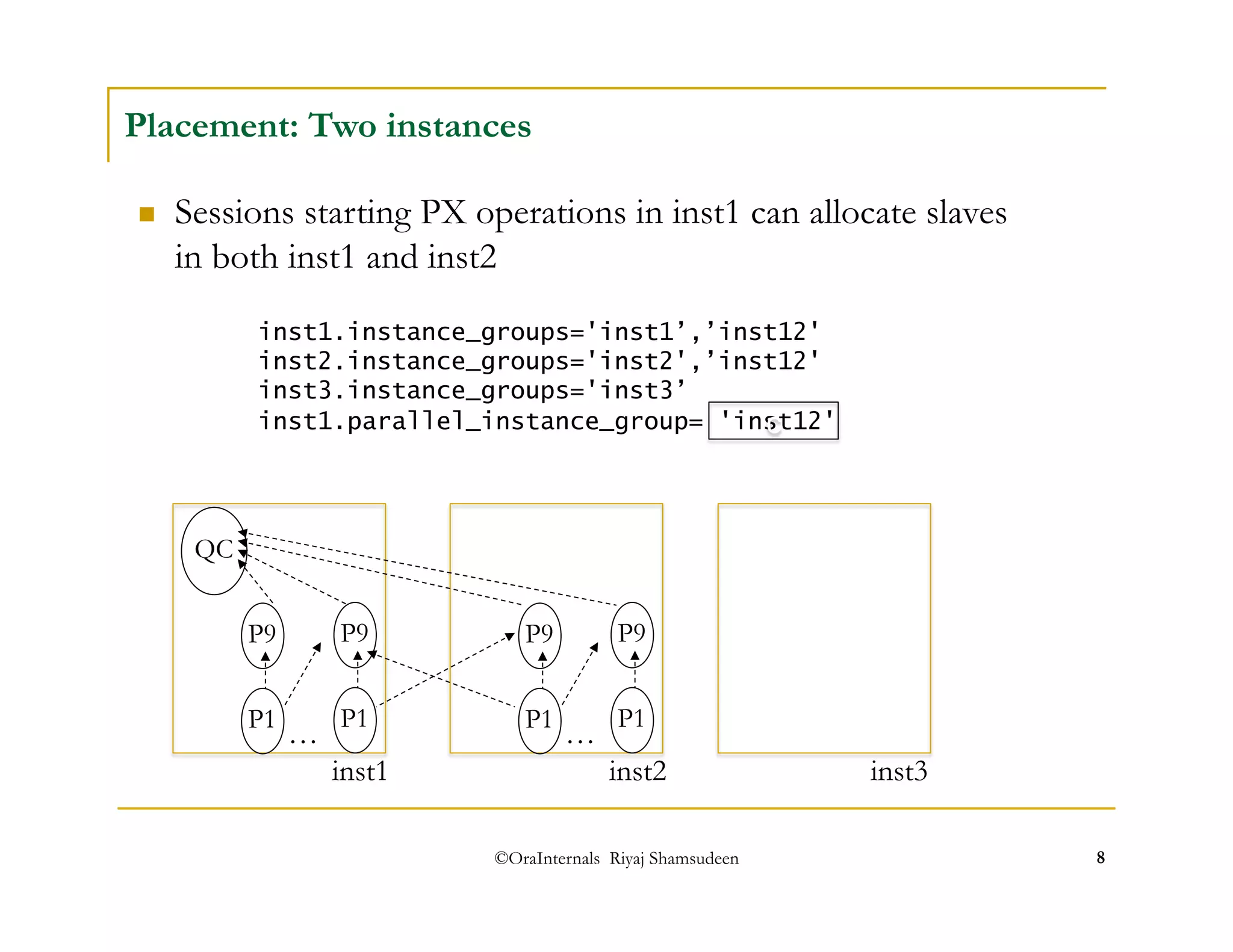
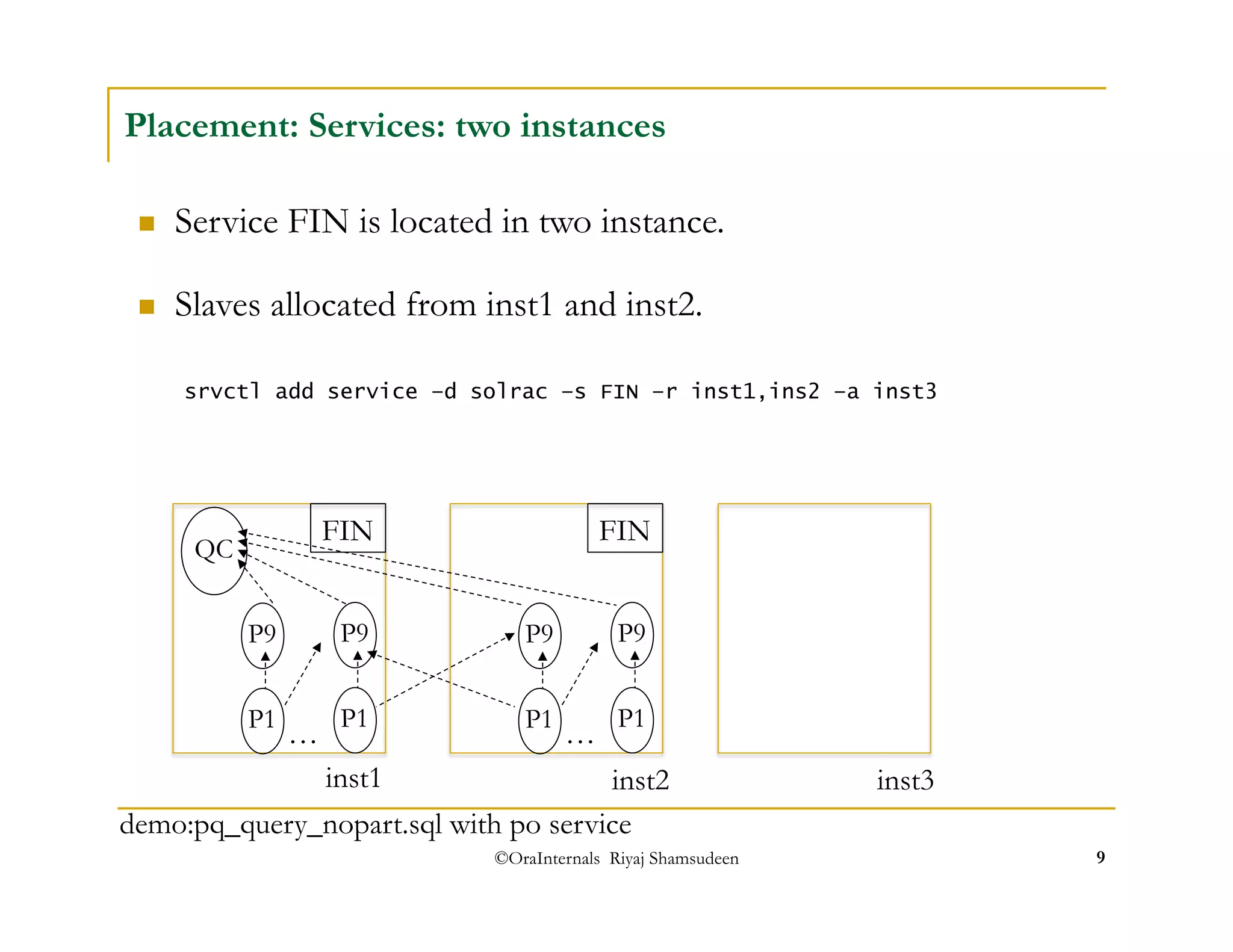
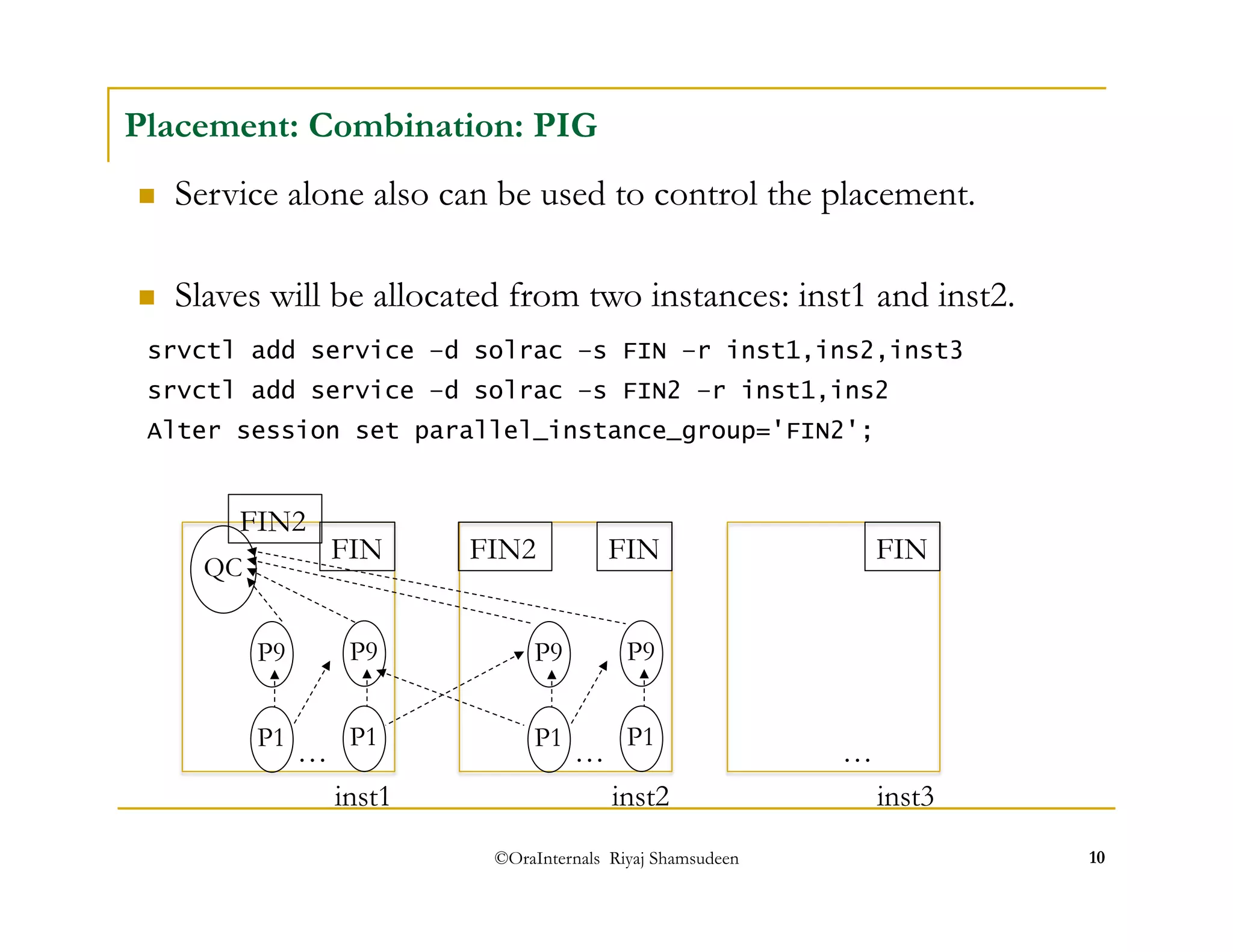


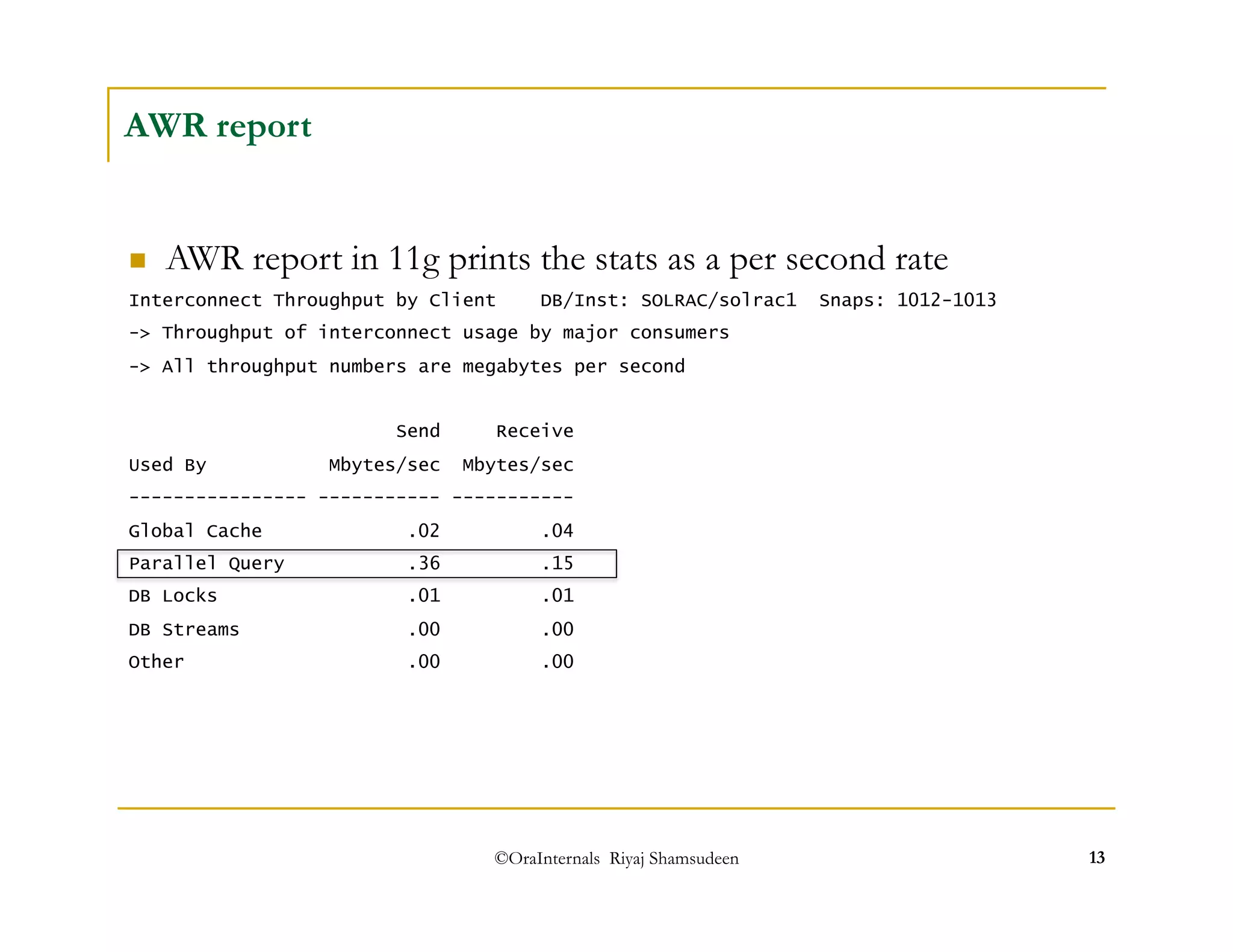











The document discusses administering parallel execution in Oracle databases. It describes how parallel query uses slave processes to perform work across instances, and how the placement of slaves can be controlled using services or parallel instance groups. It provides an example execution plan showing how slaves perform different tasks like scanning and sorting. It also covers best practices, new features in Oracle 11g like parallel statement queueing, and how parallel DML works.























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


