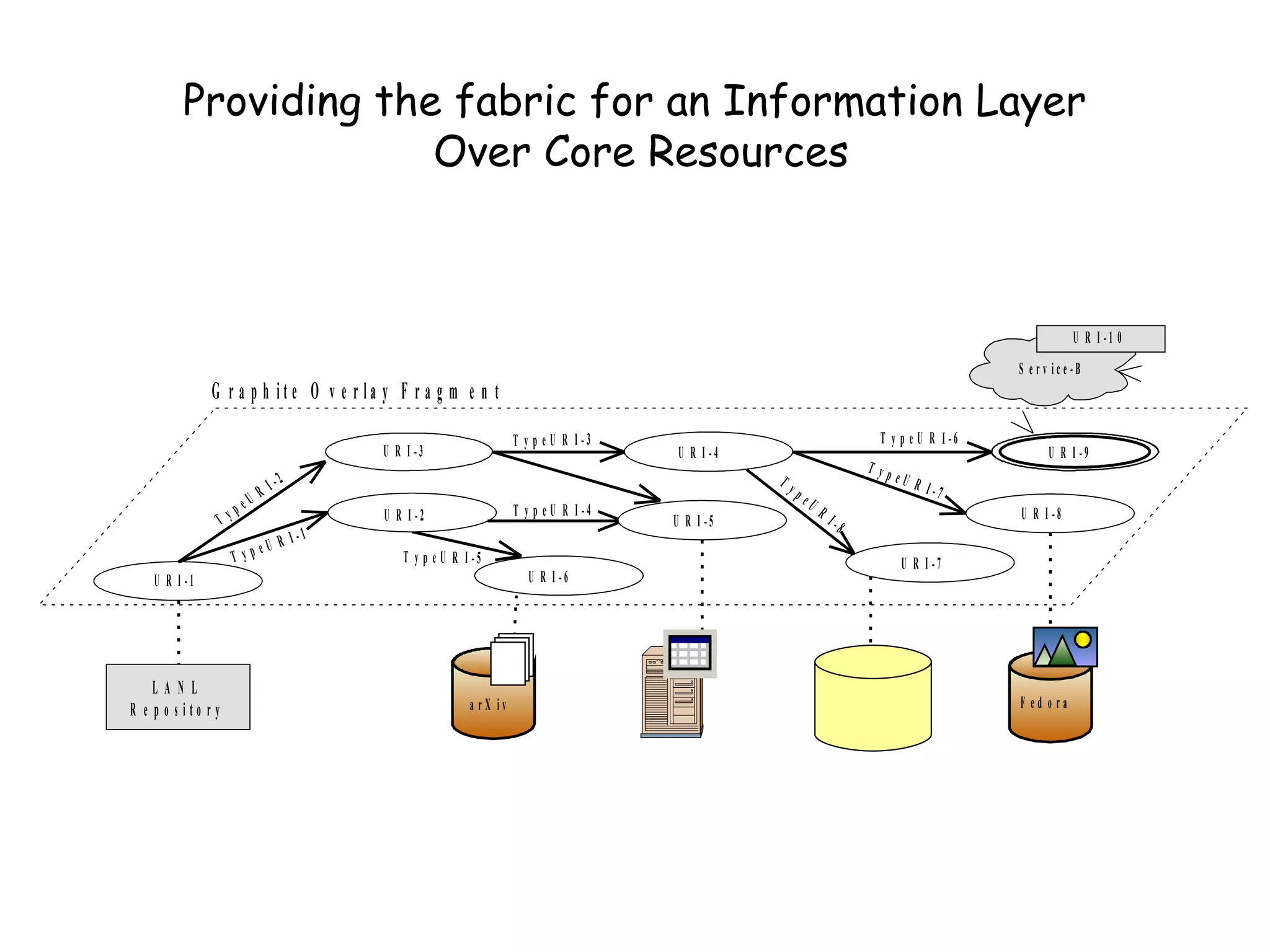
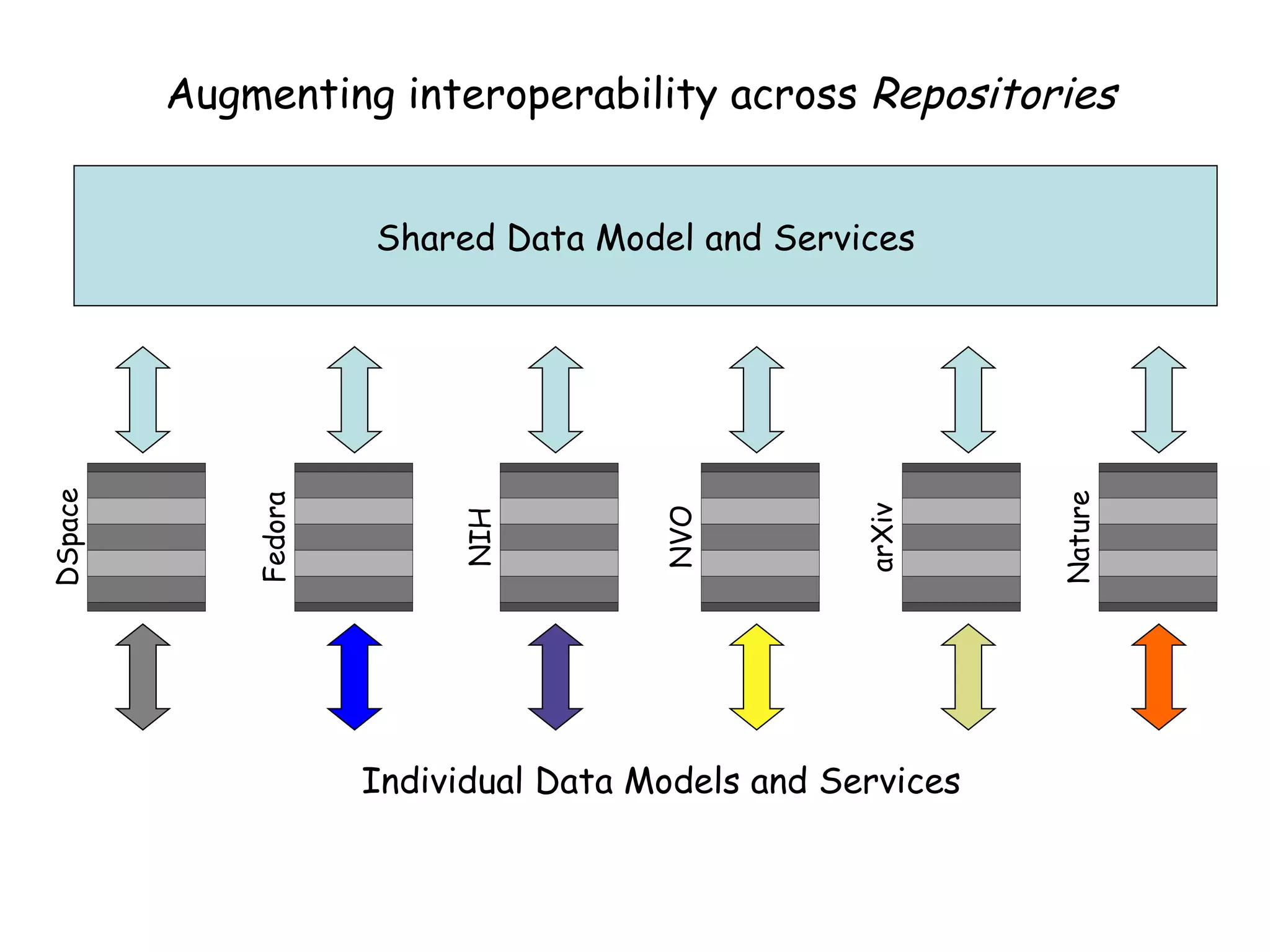
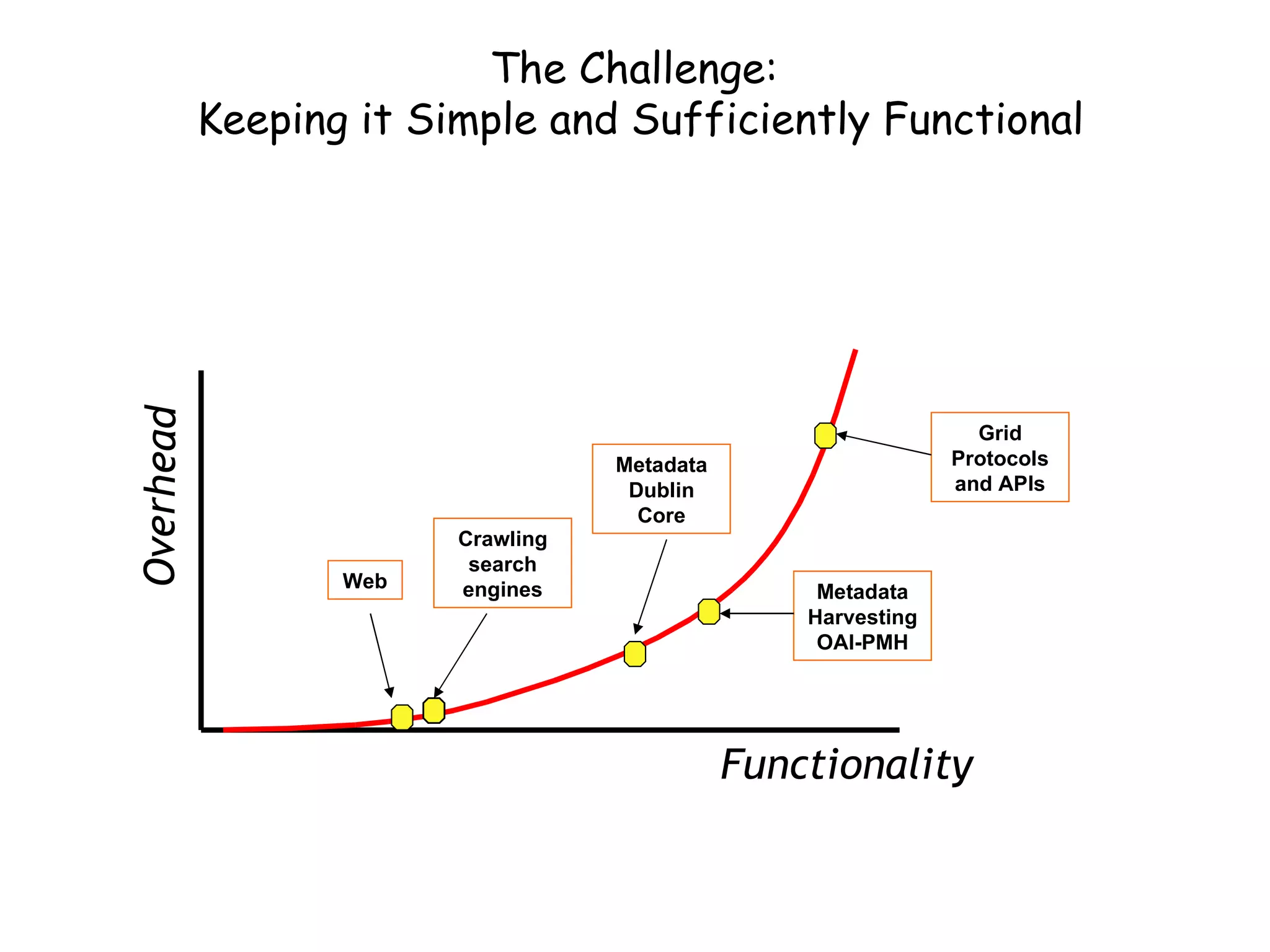
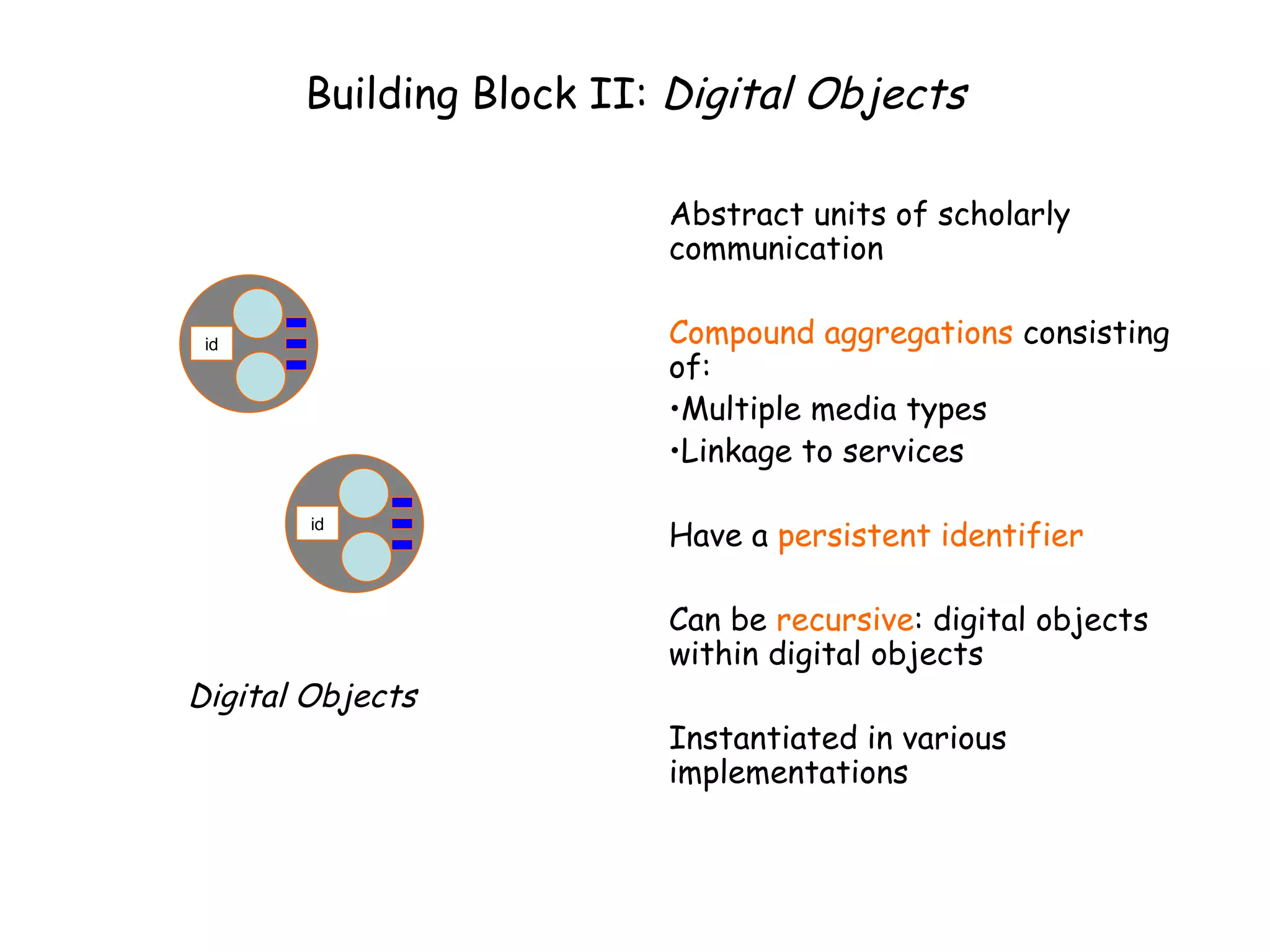
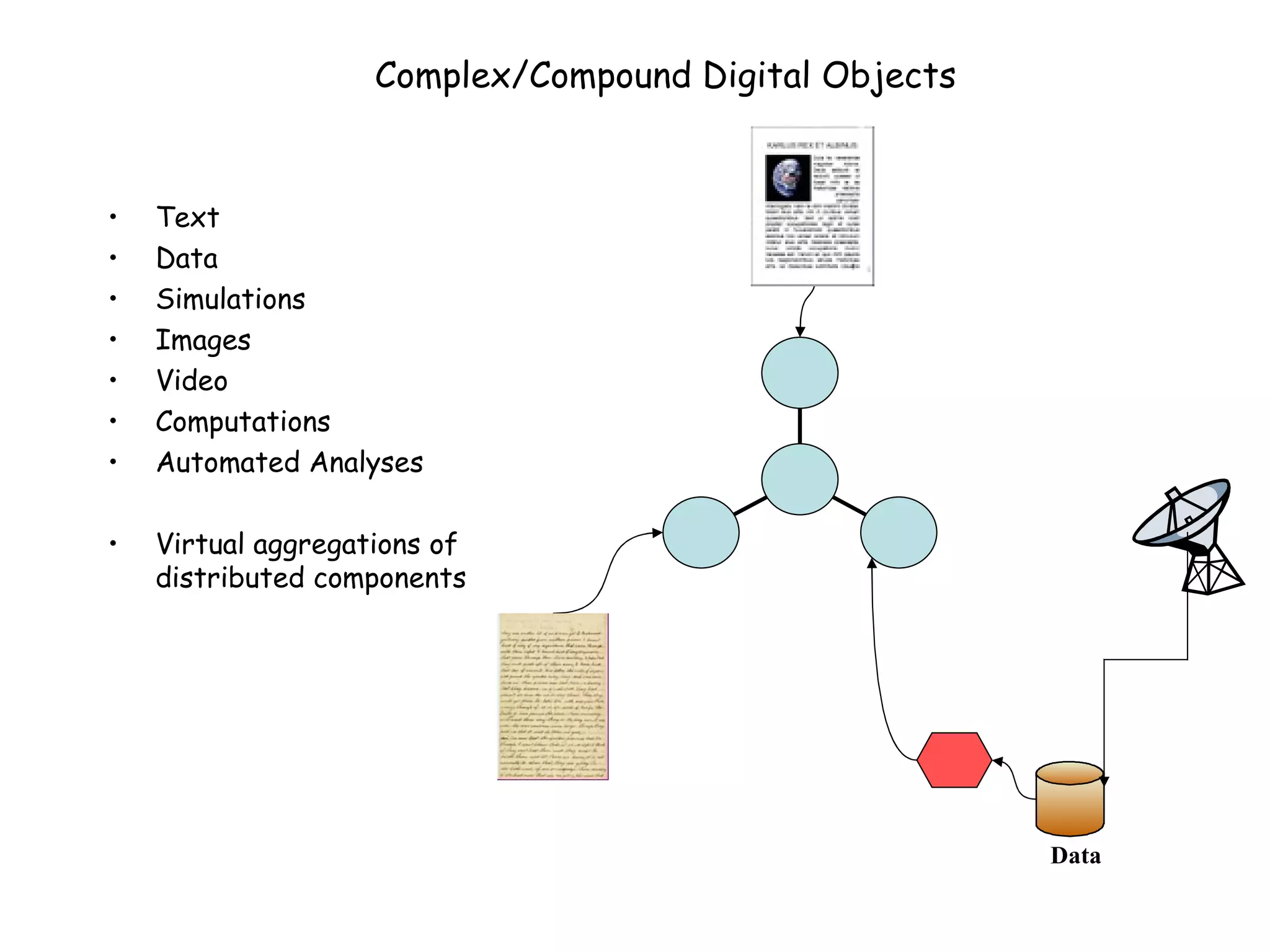
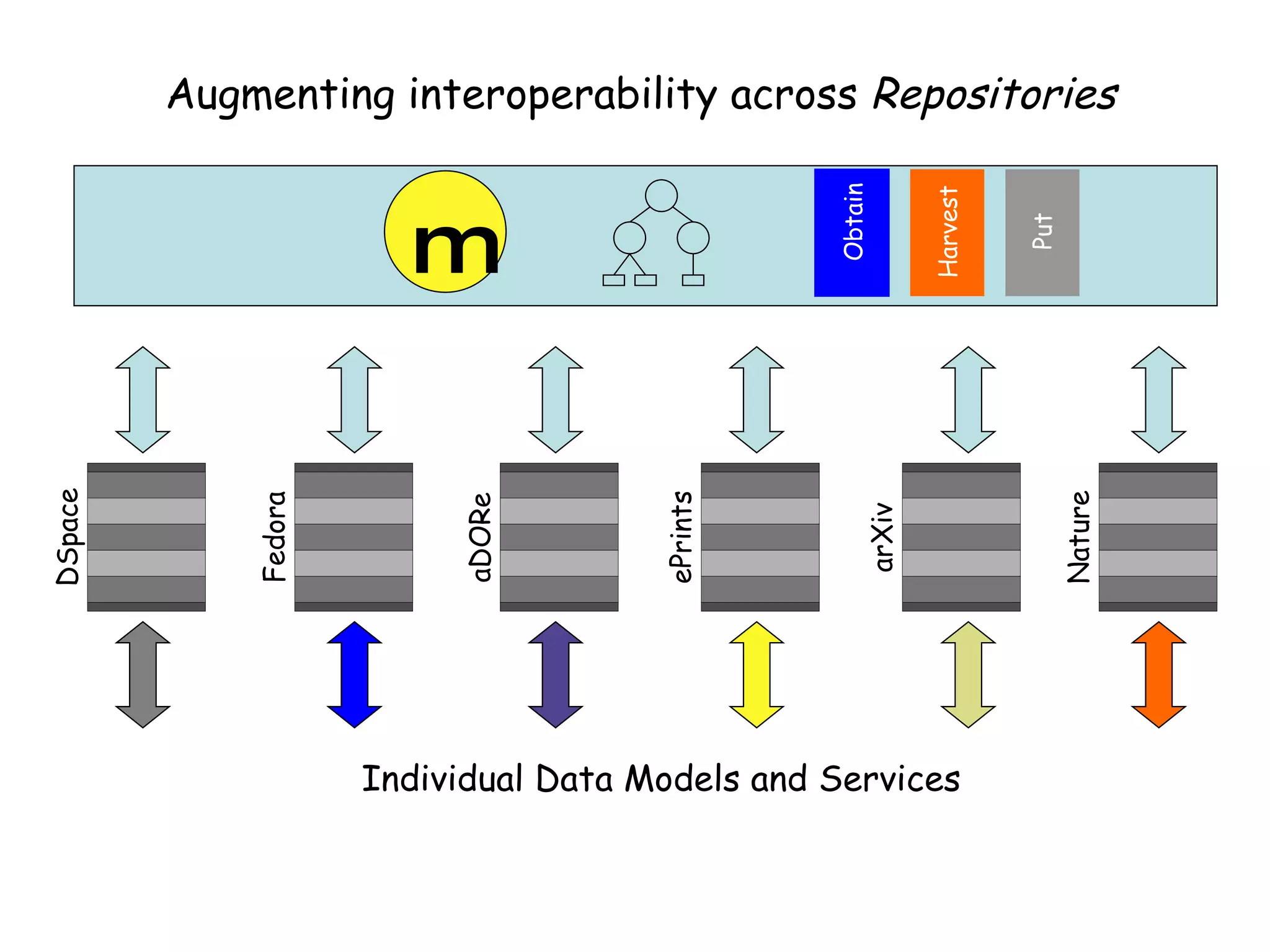
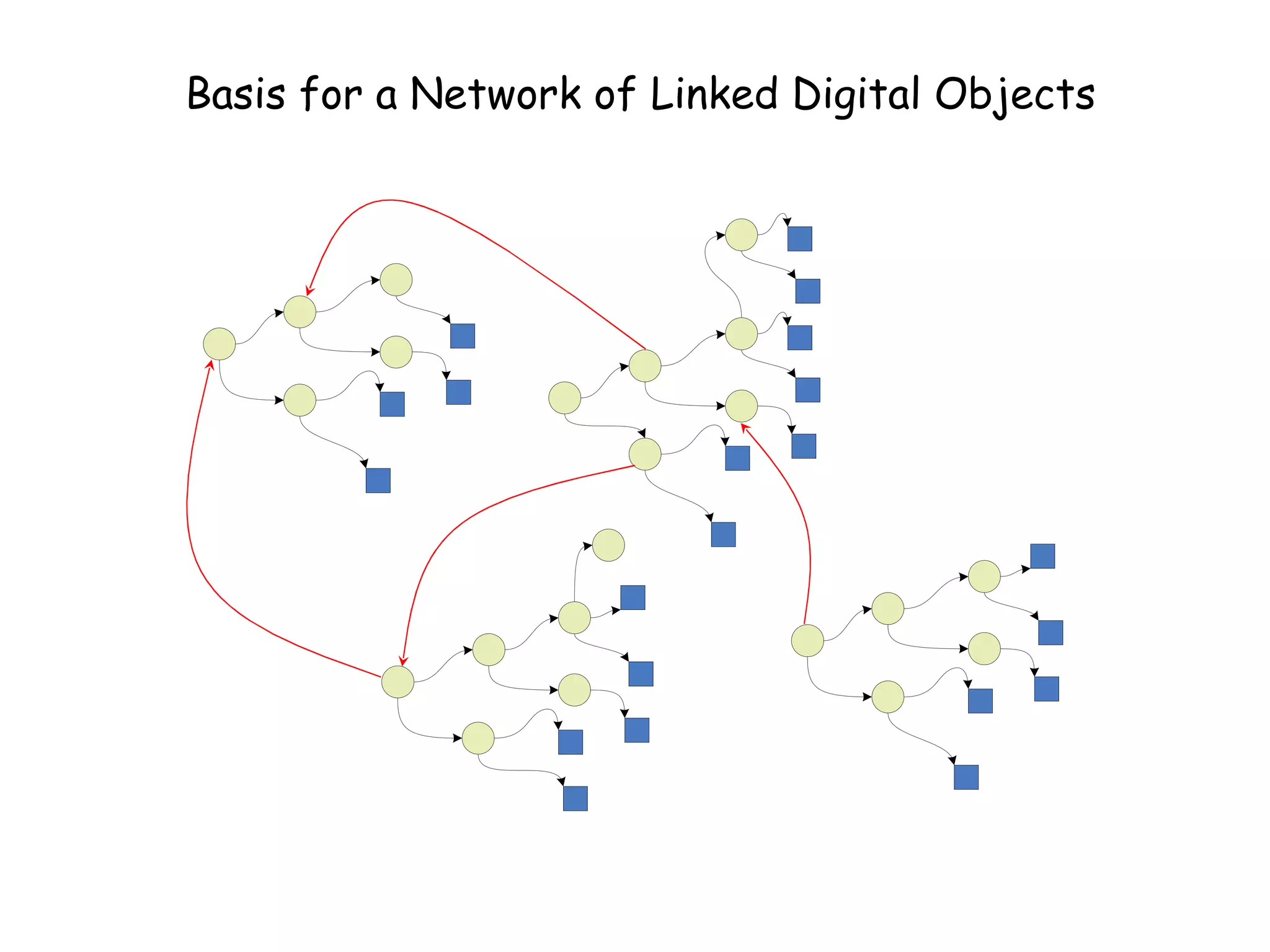
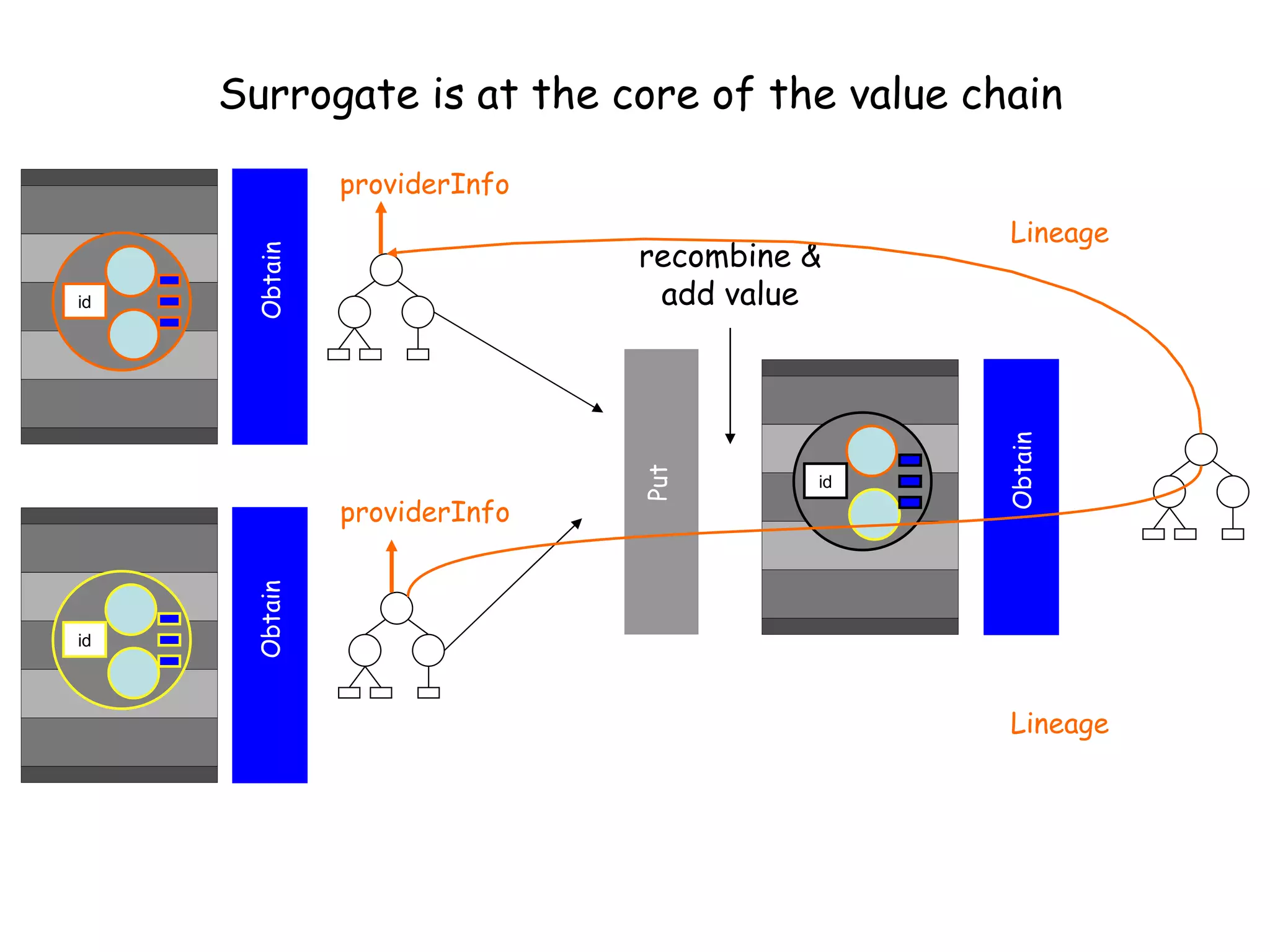
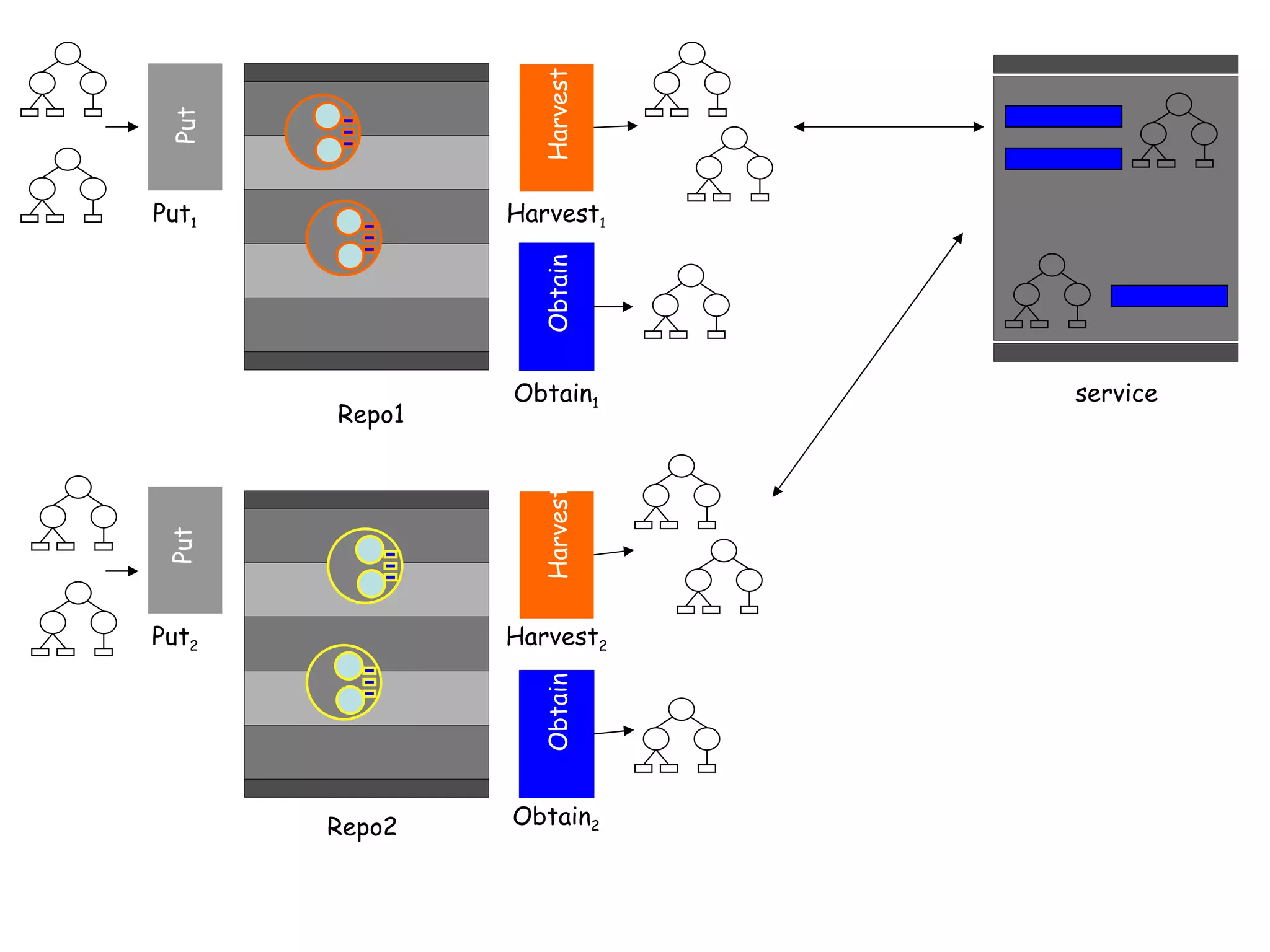
This document discusses infrastructure to support new models of scholarly publication by enabling interoperability across repositories through common data modeling and services. It proposes building blocks like repositories, digital objects, a common data model, serialization formats, and core services. This would allow components like publications and data to move across repositories and workflows, facilitating reuse and new value-added services that expose the scholarly communication process.
![Open Archives Initiative Object Reuse and Exchange Infrastructure to Support New Models of Scholarly Publication Carl Lagoze Information Science Cornell University [email_address]](https://image.slidesharecdn.com/open-archives-initiative-object-reuse-and-exchange-17958/75/Open-Archives-Initiative-Object-Reuse-and-Exchange-1-2048.jpg)