Download to read offline










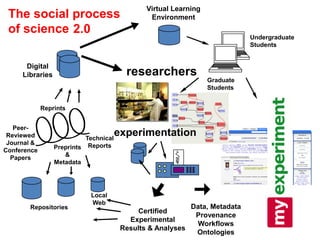

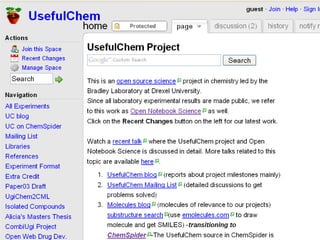













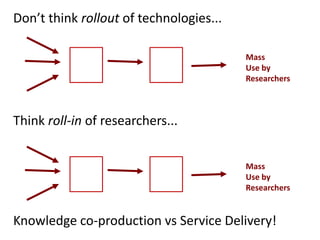
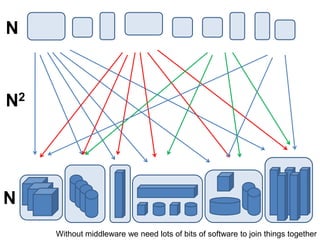
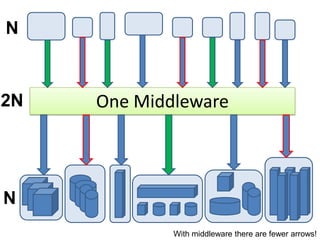
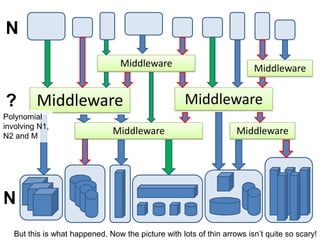



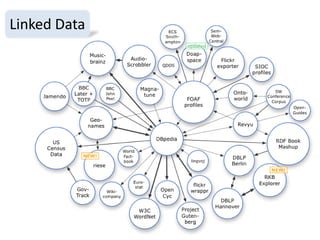


1. The document discusses the challenges of widespread adoption of e-research technologies by everyday researchers. While early adopters found success, most researchers are not using the infrastructure services that have been created. 2. It argues that repositories and other e-research tools need to focus on the needs and perspectives of researchers. Researchers work with data, so tools should emphasize data sharing and metadata. They should also support collaboration and open participation in the scientific process. 3. For technologies to truly enable new forms of research, their use needs to become integrated into the everyday work of all researchers, not just a specialized few. Systems must be easy to use, empower researchers' autonomy, and intersect seamlessly with digital and physical

















































































