This document provides an overview of support vector machines and kernel methods for machine learning.
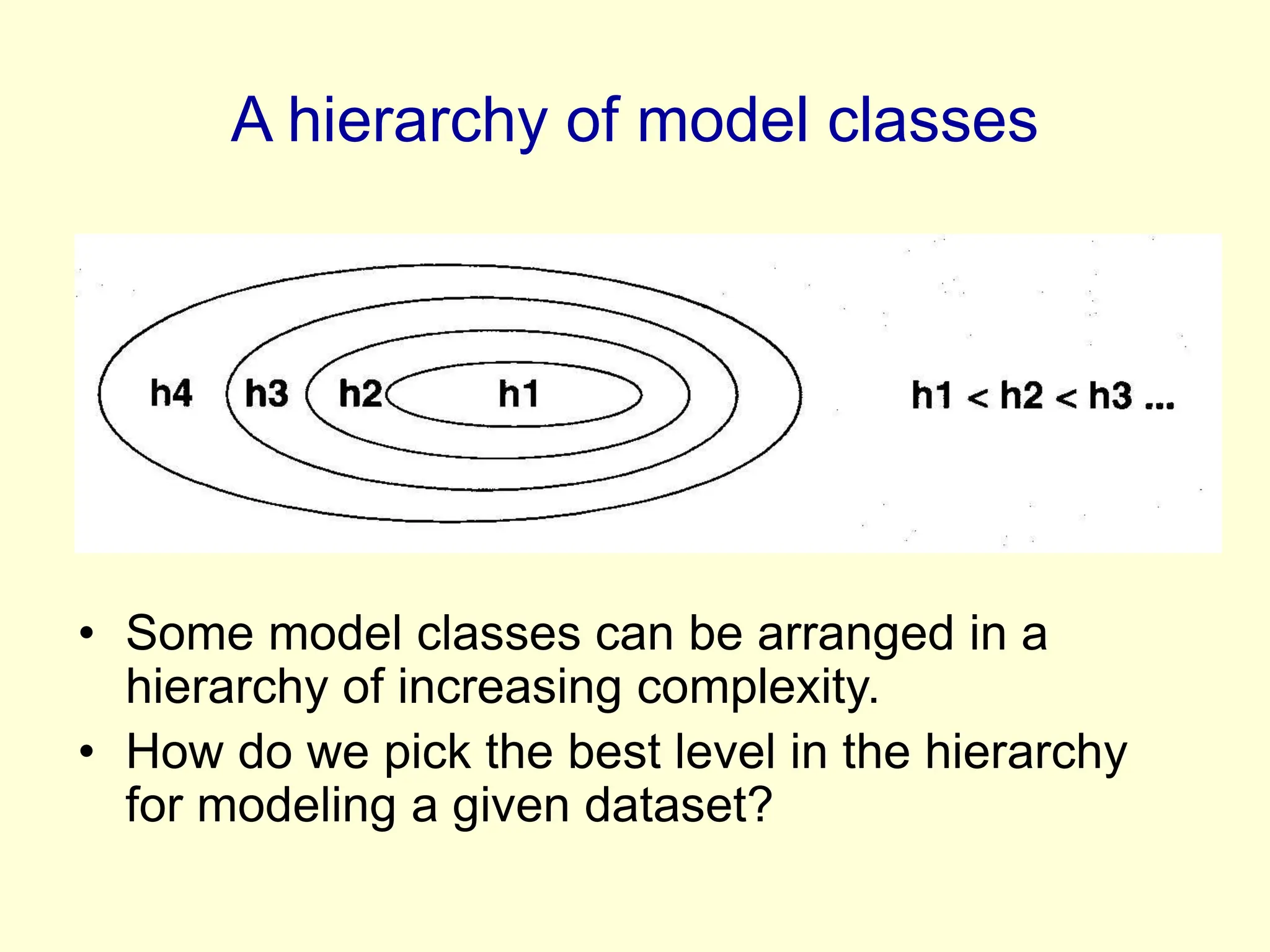
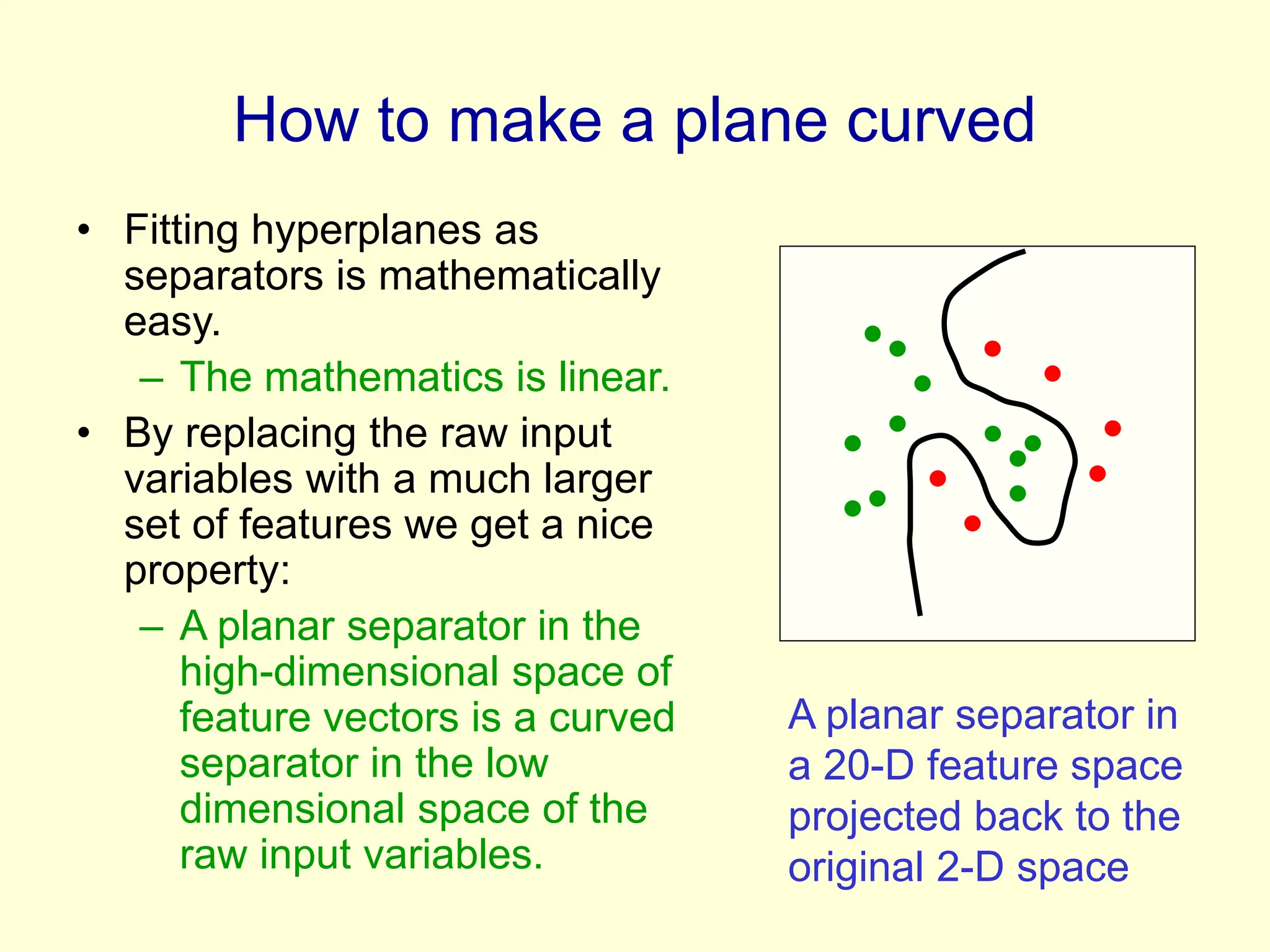
It discusses how preprocessing input data with nonlinear features can make classification problems linearly separable in high-dimensional space. However, directly using all possible features risks overfitting.
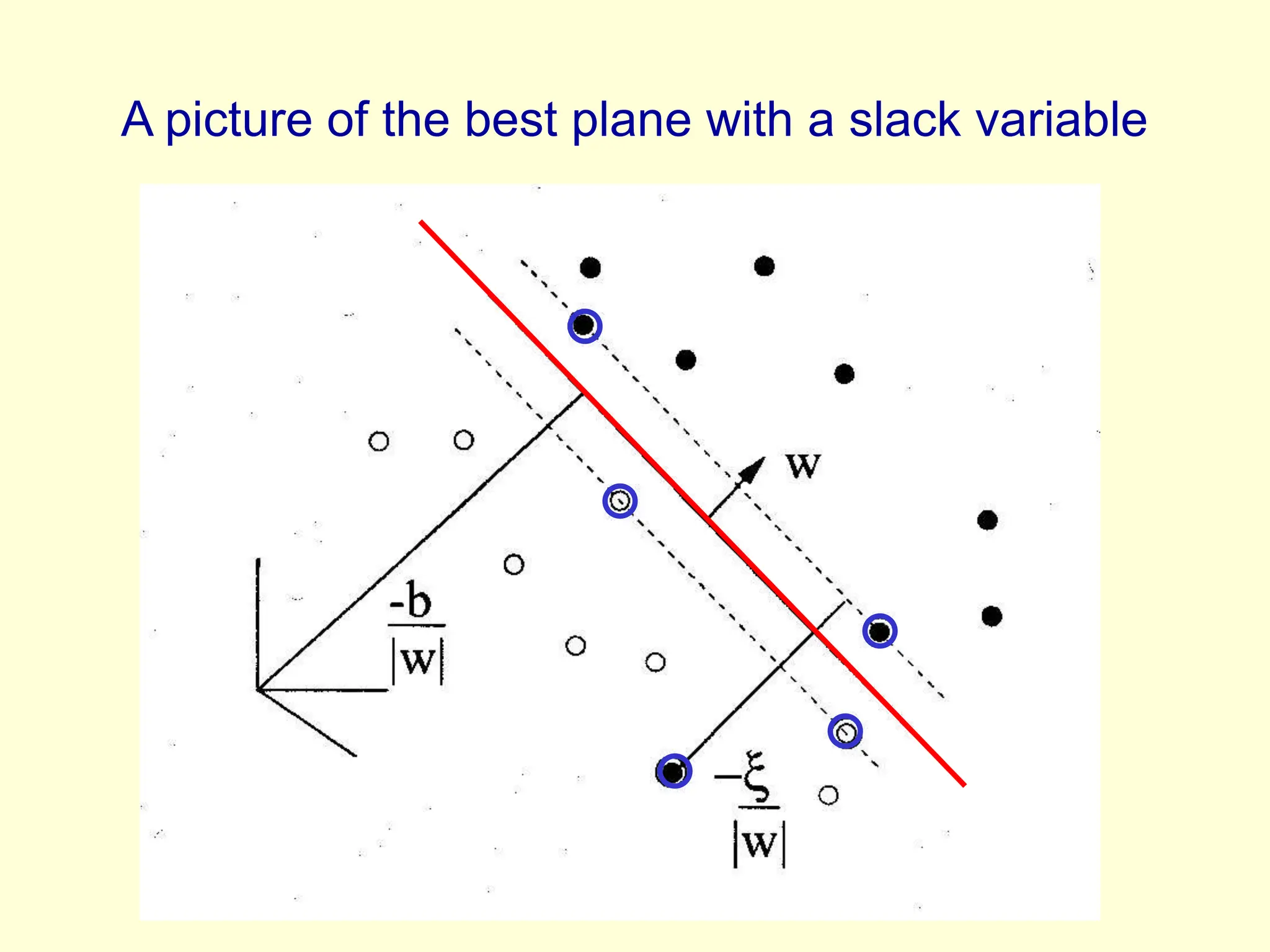
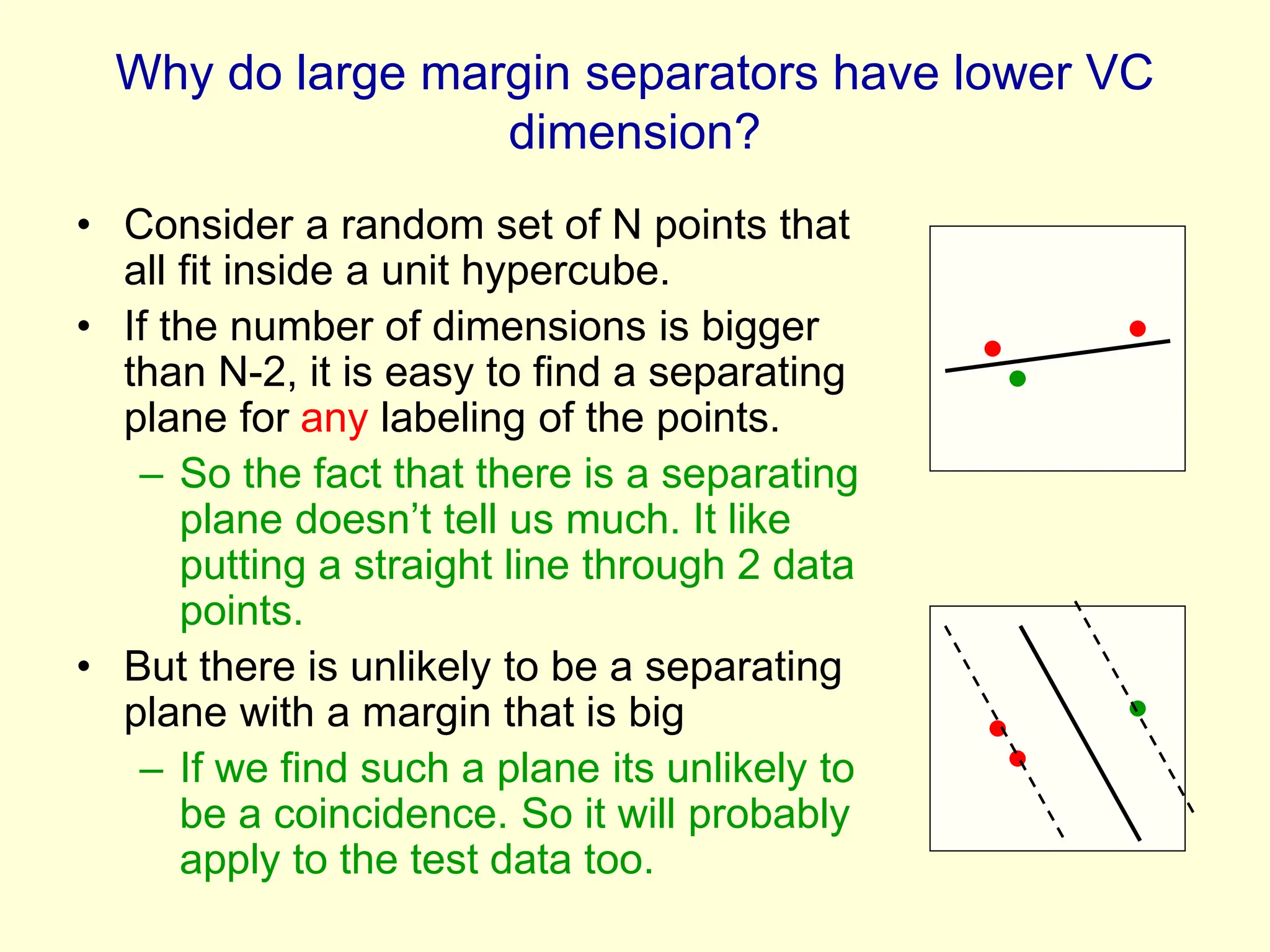
Support vector machines find a maximum-margin separating hyperplane in feature space to minimize overfitting. They use only a subset of training points, called support vectors, to define the decision boundary.
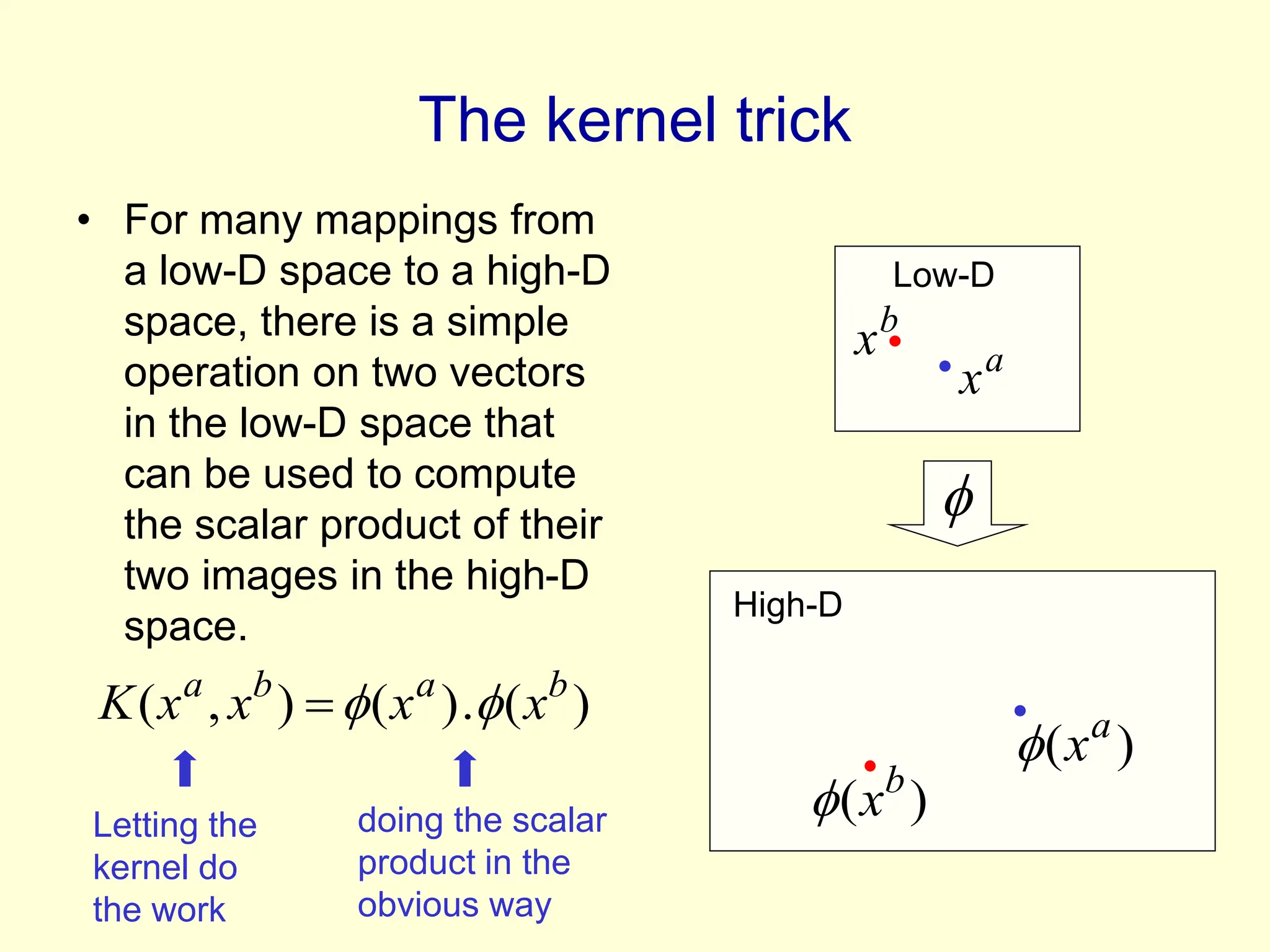
The kernel trick allows support vector machines to implicitly operate in very high-dimensional feature spaces without explicitly computing the feature vectors. All computations can be done using kernel functions that evaluate scalar products in feature space. This makes support vector machines computationally feasible even for huge feature spaces