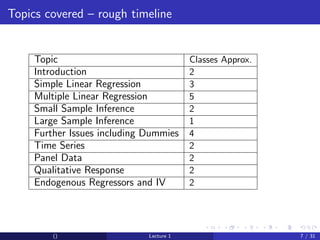
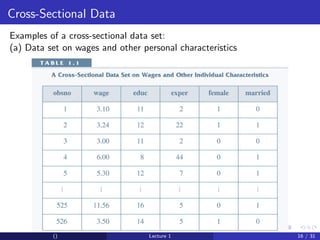
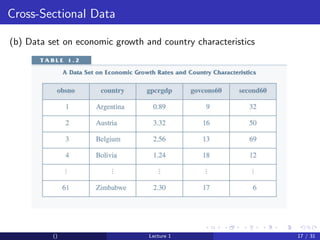
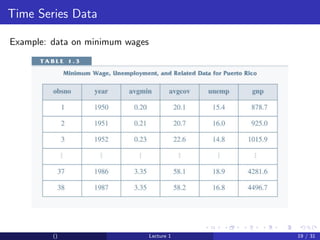
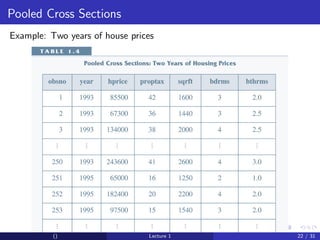
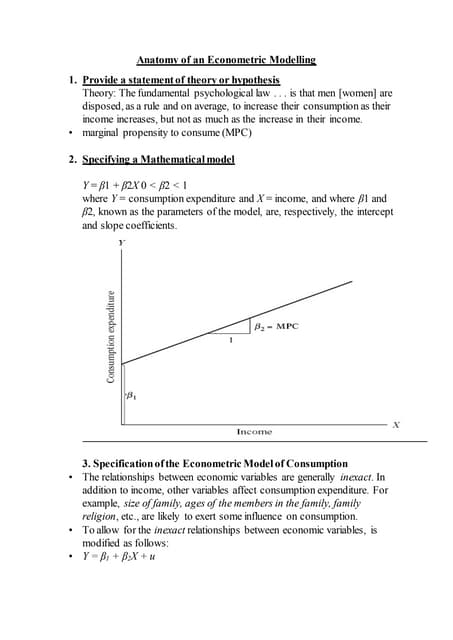
This document provides an overview and outline of an introductory econometrics course. It discusses the course objectives, which are to develop a working knowledge of econometrics and its applications. The course will cover topics like simple regression, multiple regression, and time series analysis. Students will learn to conduct their own empirical research using econometric software. The assessment will include assignments, midterms, and a final exam.