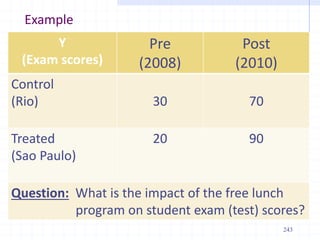
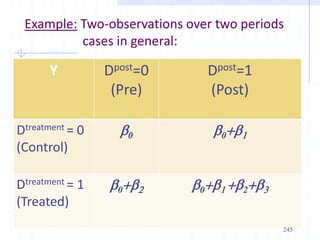
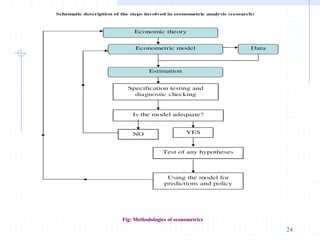
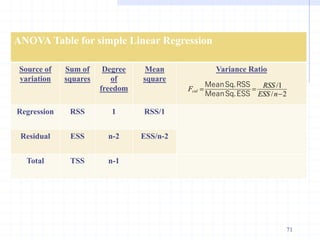
This document provides an introduction to econometrics. It defines econometrics as the integration of economic theory, statistics, and mathematics to empirically analyze economic phenomena. The chapter discusses the need, objectives, and goals of econometrics, including describing economic reality, testing hypotheses, and forecasting. It also compares economic models to econometric models, and outlines the methodology and desirable properties of econometric models. Finally, it discusses different types of data used in econometric analysis, including time series, cross-sectional, and pooled data.













































![2.3. The ordinary least squares (OLS) method of
estimation
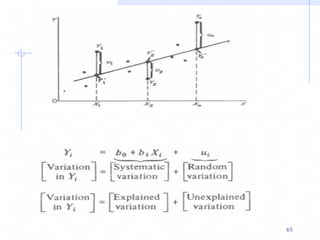
In the regression model Yi = a + bXi+ i , the values of
the parameters α and β are not known. When they
are estimated from a sample of size n, we obtain the
sample regression line given by:
where α and β are estimated by and respectively,
and is the estimated value of Y.
The dominating and powerful estimation method of
the parameters (or regression coefficients) α and β is
the method of least squares. The deviations between
the observed and estimated values of Y are called the
residuals, . [Note 1: Proof]
,...n
,
,i
X
β
α
Y i
i 2
1
ˆ
ˆ
ˆ
α
ˆ β
ˆ
Y
ˆ
ε
ˆ 47](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-47-320.jpg)
































![Proofing the Assumptions
E(𝜀𝑖) = 0
Var(𝜀𝑖) = E(𝜀𝑖 - E(𝜀𝑖))2 , but E(𝜀𝑖) = 0;
= E(𝜀𝑖 -0)2 = E(𝜀𝑖)2 = 𝜎2
Ui~ N(0, 𝜎2) --- from equation 1 and 2
Cov(𝑈𝑖, 𝑈𝑗) = E[(𝑈𝑖 –E(𝑈𝑖)][𝑈𝑗 – E(𝑈𝑗)]; since the E(𝑈𝑖) & E(𝑈𝑗)=0,
= E[(𝑈𝑖 – 0)(𝑈𝑗 – 0)]= E[(𝑈𝑖)(𝑈𝑗)] = E(𝑈𝑖) E(𝑈𝑗) = 0
Cov(𝑋𝑖, 𝑈𝑖) = 0; E(𝑋𝑖–E(𝑋𝑖))(𝑈𝑖– E(𝑈𝑖), but the E(𝑈𝑖) = 0; then E(𝑋𝑖– E(𝑥𝑖))(𝑈𝑖)
= E(𝑋𝑖𝑈𝑖 – 𝑈𝑖E(𝑥𝑖) = 𝑋𝑖E(𝑈𝑖) – 𝑥𝑖E(𝑈𝑖) = 𝑋𝑖(o) – xi(0) = 0
83](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-83-320.jpg)

![Consider the following equation:
Yi= b1 + b2X2i + b3X3i + . . . bkXki + i ,
For (k = 3), Yi= b1 + b2X2i + b3X3i + i
3.3. Estimation of parameters and SEs
2
3
2
2
3
2
2
3
2
3
2
3
2
2
)
(
[
]
][
[
]
][
[
]
)
(
][
[
ˆ
i
i
i
i
i
i
i
i
i
i
i
x
x
x
x
x
x
y
x
x
y
x
β
2
3
2
2
3
2
2
3
2
2
2
2
3
3
)
(
[
]
][
[
]
][
[
]
][
[
ˆ
i
i
i
i
i
i
i
i
i
i
i
x
x
x
x
x
x
y
x
x
y
x
β
85](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-85-320.jpg)












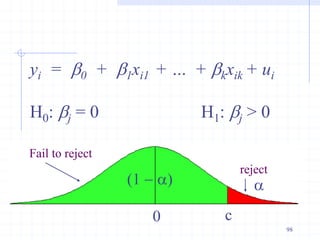








![Computing p-values and t tests with
statistical packages
Most computer packages will compute the
p-value for you, assuming a two-sided test
If you really want a one-sided alternative,
just divide the two-sided p-value by 2
Stata provides the t statistic, p-value, and
95% confidence interval for H0: bj = 0 for
you, in columns labeled “t”, “P > |t|” and
“[95% Conf. Interval]”, respectively
108](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-108-320.jpg)
![109
Given multiple regression stata output for income as dependent
variable and temperature, altitude, cities, wage, education,
ownership, and location as explanatory variables and _cons is a
constant term. Based on this, answer the questions that follow.
The following table is generated using the command..
regress income temperature altitude cities wage education
ownership location
_cons .388519 .2026306 1.92 0.058 -.0126417 .7896797
location -.0334028 .009427 -3.54 0.001 -.0520661 -.0147395
ownership .1559908 .0977688 1.60 0.113 -.0375684 .34955
education .0430756 .0125391 3.44 0.001 .0182511 .0679001
wage .1425848 .0795389 1.79 0.076 -.0148835 .300053
cities -.4307053 .0685673 -6.28 0.000 -.5664523 -.2949584
altitude .002892 .0815342 0.04 0.972 -.1585266 .1643105
temperature .0498639 .0681623 0.73 0.466 -.0850814 .1848092
income Coef. Std. Err. t P>|t| [95% Conf. Interval]](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-109-320.jpg)














![ Consider parametric estimation under MLR
Thus, b2 is indeterminate. It can also be shown that b3 is also
indeterminate. Therefore, in the presence of perfect MC, the
regression coefficients can not be estimated.
0
0
25
25
5
5
ˆ
)
5
(
)
5
(
5
5
ˆ
)
(
[
]
][
[
]
][
[
]
)
(
[
]
[
ˆ
2
2
3
2
3
2
3
2
3
3
2
3
3
2
2
3
3
2
3
2
3
3
3
3
2
3
3
2
2
3
2
2
3
2
2
3
2
3
2
3
2
2
x
x
x
x
y
x
x
y
x
x
x
x
x
x
x
y
x
x
y
x
x
x
x
x
x
x
y
x
x
y
x
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
i
b
b
b
124](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-124-320.jpg)

















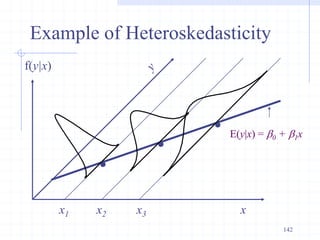




















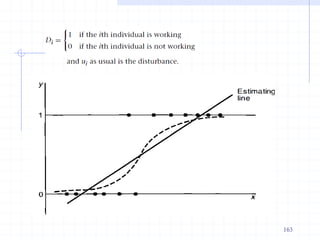


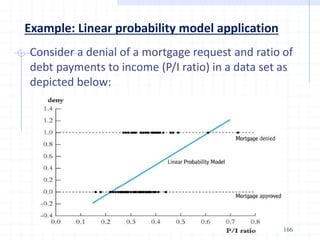









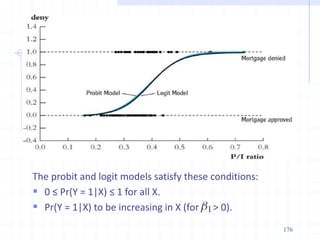


















![ The measured dependent variable of a decision maker are
assumed to be correlated with the latent variable through the
following threshold criterion
Example: A working mother can establish just as warm and
secure of a relationship with her child as a mother who does
not work. [1=Strongly disagree; 2=Disagree; 3=Agree and
4=Strongly agree].
195](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-195-320.jpg)













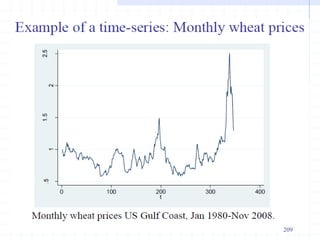
















![226
Types of the process
(a). Moving average (MA) process
This process only assumes a relation between
periods t and t-1 via the white noise residuals et.
A moving average process of order one [MA(1)]
can be characterized as one where
Yt = et + a1et-1, t = 1, 2,
with et being an iid sequence with mean 0 and
variance s2
This is a stationary, weakly dependent sequence as
variables 1 period apart are correlated, but 2
periods apart they are not](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-226-320.jpg)
![227
Autoregressive (AR) process
An autoregressive process of order one
[AR(1)] can be characterized as one where
Yt = yt-1 + et , t = 1, 2,…
with et being an iid sequence with mean 0
and variance se
2
For this process to be weakly dependent, it
must be the case that |r| < 1
An autoregressive process of order one
[AR(p)]
Yt = 1 yt-1 + 2 yt-2 +… p yp-1 + et](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-227-320.jpg)
![ Similarly, a moving average (MA) of order (q)]
can be given as
Yt = et + a1et-1 + a2et-2 + … + aqet-q
A combined an AR(p) and MA(q) process can
be combined to an ARMA(p,q) process:
Yt = 1 yt-1 + 2 yt-2 + et + a1et-1 + a2et-2 … + aqet-q
Using the lag operator:
LYt=Yt-1
L2Yt =L(L)Yt=L(Yt-1 )=Yt-2
LpYt =Yt-p
228](https://image.slidesharecdn.com/econometricschaptersall-240402122151-85f21854/85/Econometrics1-2-3-4-5-6-7-8_ChaptersALL-pdf-228-320.jpg)