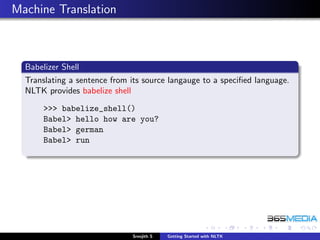
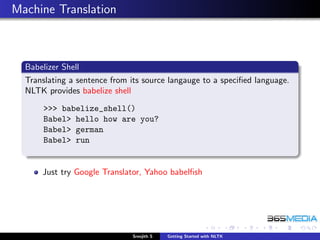
The document provides an overview of the Natural Language Toolkit (NLTK). It discusses that NLTK is a Python library for natural language processing that includes corpora, tokenizers, stemmers, part-of-speech taggers, parsers, and other tools. The document outlines the modules in NLTK and their functionality, such as the nltk.corpus module for corpora, nltk.tokenize and nltk.stem for tokenizers and stemmers, and nltk.tag for part-of-speech tagging. It also provides instructions on installing NLTK and downloading its data.
























































![Let us start the game
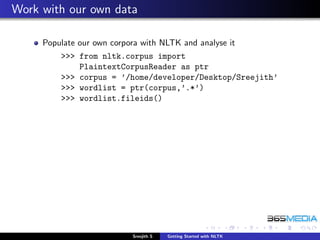
To access data for working out the example in the book
Start python interpreter
Some basic work outs from the book
Concordance
>>> from nltk.book import *
>>> text1.concordance("monstrous")
Similar
>>> text1.similar("monstrous")
Dispersion plot - Positional information
>>> text4.dispersion_plot(["citizens",
"democracy", "freedom", "duties", "America"])
>>> text4.dispersion_plot(["and",
"to", "of", "with", "the"])
What is it !!! Why ???
Sreejith S Getting Started with NLTK](https://image.slidesharecdn.com/nltk-130211051746-phpapp02/85/Introduction-to-NLTK-56-320.jpg)























![Normalizing Text
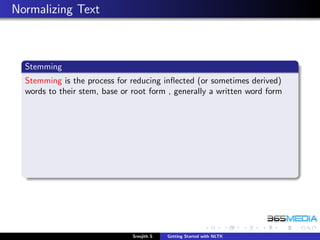
Stemming
Stemming is the process for reducing inflected (or sometimes derived)
words to their stem, base or root form , generally a written word form
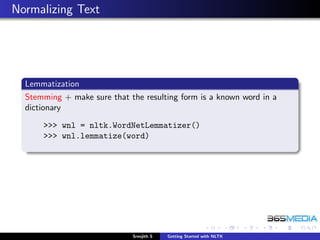
>>> porter = nltk.PorterStemmer()
>>> word = ’running’
>>> porter.stem(word)
>>> lancaster = nltk.LancasterStemmer()
>>> lancaster.stem(tok[2])
Sreejith S Getting Started with NLTK](https://image.slidesharecdn.com/nltk-130211051746-phpapp02/85/Introduction-to-NLTK-84-320.jpg)




![Parsing
Sentence Parsing
Analyzing sentence structures and create a Parse Tree
>>> sentence = [("the", "DT"), ("little", "JJ"),
("yellow", "JJ"),("dog", "NN"), ("barked", "VBD"),
("at", "IN"), ("the", "DT"), ("cat", "NN")]
>>> grammar = "NP: {<DT>?<JJ>*<NN>}"
>>> cp = nltk.RegexpParser(grammar)
>>> result = cp.parse(sentence)
>>> print result
>>> result.draw()
Sreejith S Getting Started with NLTK](https://image.slidesharecdn.com/nltk-130211051746-phpapp02/85/Introduction-to-NLTK-93-320.jpg)