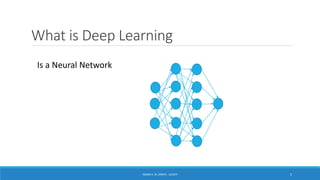
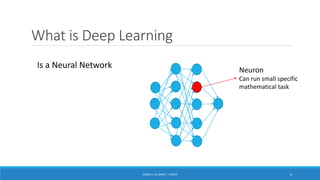
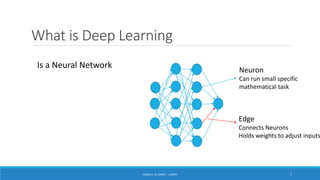
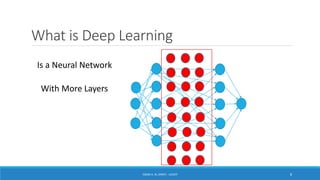
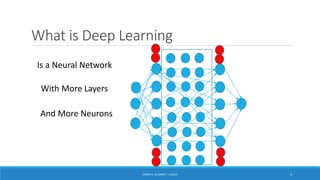
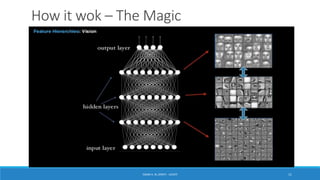
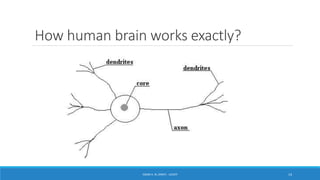
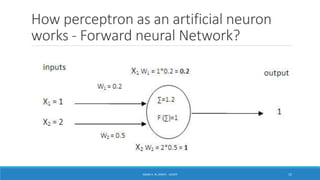
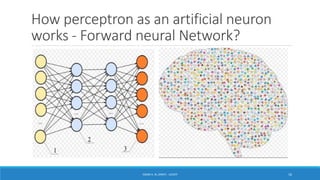
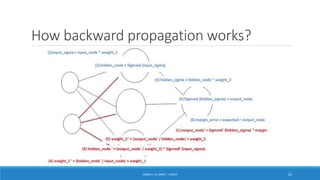
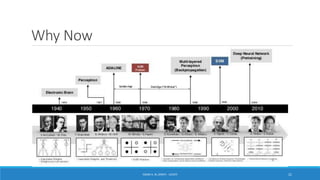
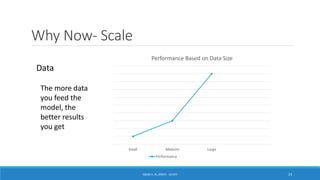
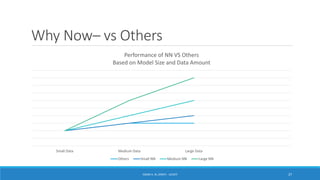
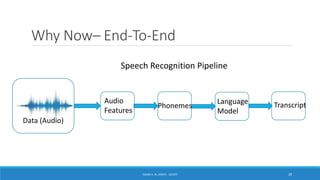
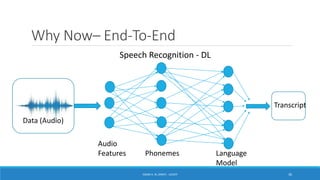
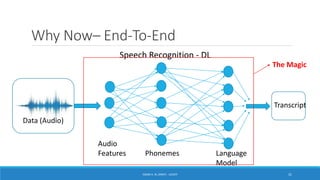
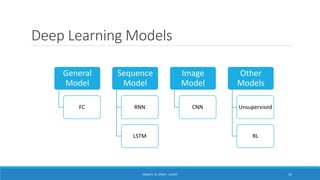
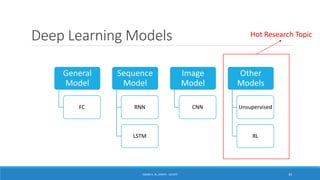
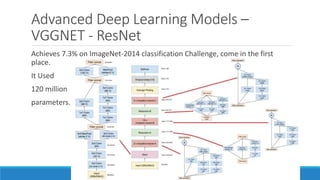
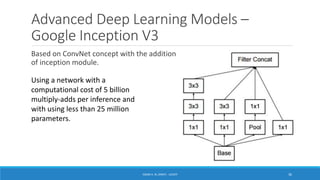
Deep learning is a machine learning method that uses neural networks with many layers to perform complex tasks like object detection and image classification. It allows AI systems to train on large labeled or unlabeled datasets to learn patterns and make predictions. Deep learning has advanced significantly due to growth in data availability and computational power via GPUs. Neural networks can now be trained end-to-end on raw data like images and audio, rather than requiring feature engineering. Popular deep learning models include convolutional neural networks for computer vision and recurrent neural networks for natural language processing. Deep learning is being applied across many domains including speech recognition, image captioning, and video generation.