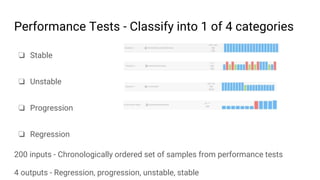
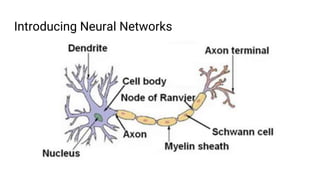
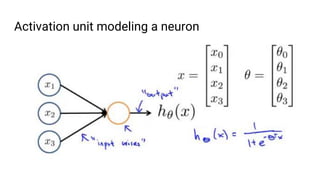
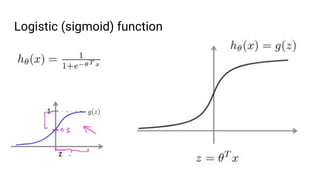
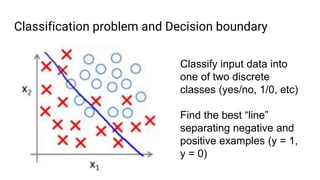
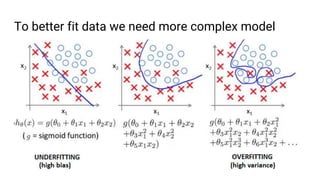
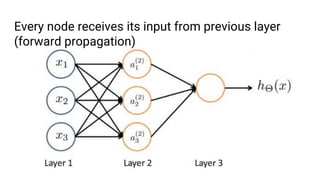
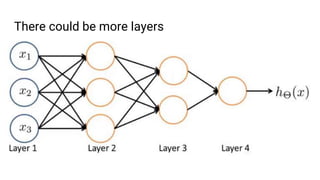
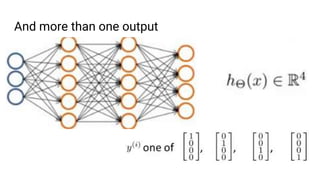
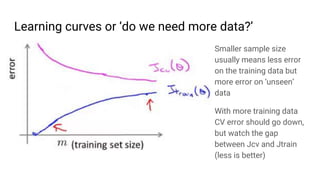
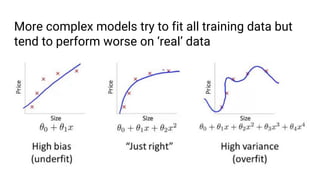
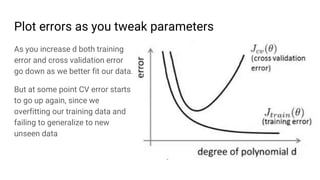
The document discusses the application of machine learning, specifically for classifying performance test results in Unity, using .NET. It covers fundamental concepts of machine learning, types of learning algorithms, and details the process of building and training neural networks for classification problems. Key elements include the structure of neural networks, the importance of data division for validation, and performance metrics such as precision and recall.