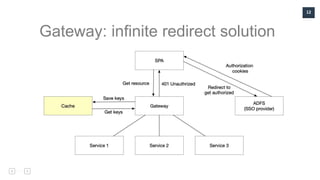
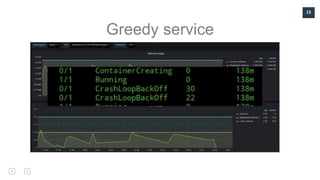
.NET Core in Production discusses challenges and solutions faced during the development of a financial solution using microservices. The speaker, Leonid Molotiievskyi, shares experiences related to scaling, issues with DevOps, and the importance of monitoring and smart technology decisions. Key lessons include adapting to scaling needs from the start and fostering collaboration with DevOps teams to resolve problems.











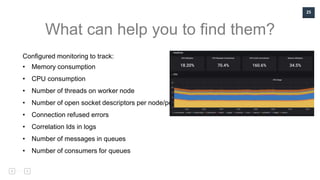
![21
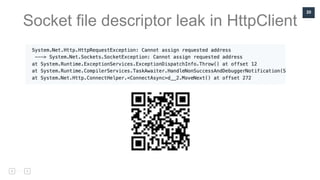
Docker: no space left on the device
level=info msg="[8] System error: write
/sys/fs/cgroup/docker/01f5670fbee1f6687f58f3a943b1e1bdaec26
30197fa4da1b19cc3db7e3d3883/cgroup.procs: no space left on
device"](https://image.slidesharecdn.com/leonidmolotiievskyi-dotnetissuesinproduction-191029082920/85/NET-Fest-2019-DotNet-Core-in-production-21-320.jpg)