Downloaded 18 times







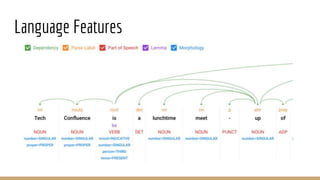






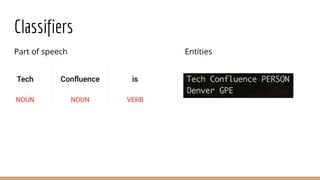




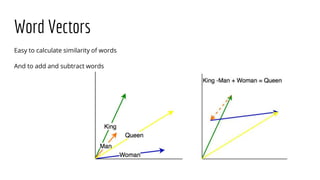





This document discusses natural language processing (NLP) and feature extraction. It explains that NLP can be used for applications like search, translation, and question answering. The document then discusses extracting features from text like paragraphs, sentences, words, parts of speech, entities, sentiment, topics, and assertions. Specific features discussed in more detail include frequency, relationships between words, language features, supervised machine learning, classifiers, encoding words, word vectors, and parse trees. Tools mentioned for NLP include Google Cloud NLP, Spacy, OpenNLP, and Stanford Core NLP.