Download as ODP, PPTX






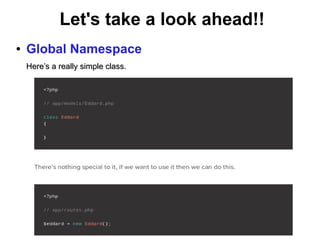







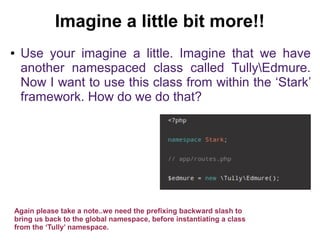
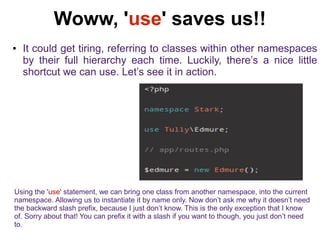
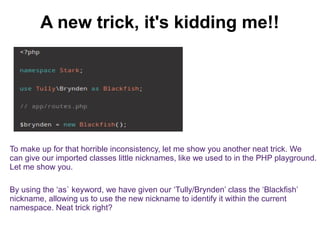





The document discusses namespaces in programming, particularly in PHP, explaining their purpose in uniquely identifying classes, preventing name conflicts, and organizing code. It provides examples of how to implement namespaces, including instantiation and usage shortcuts, as well as implications for shared libraries and code organization. Overall, it highlights the benefits and limitations of employing namespaces in software development.



































































