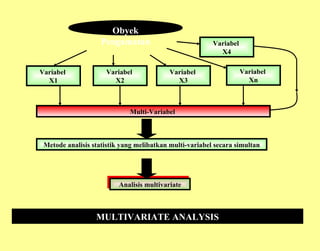
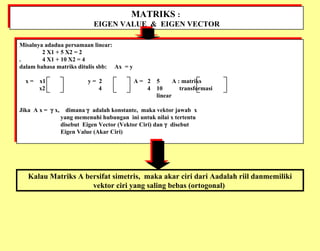
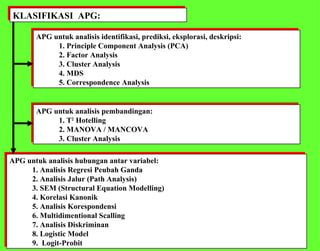
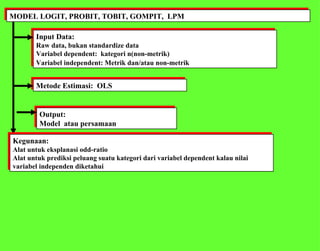
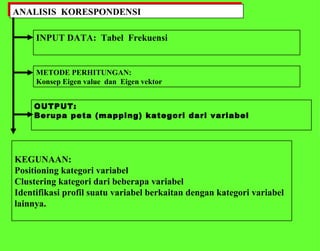
Dokumen ini membahas analisis multivariat yang melibatkan beberapa variabel untuk memahami hubungan antara variabel tersebut, termasuk teknik seperti analisis jalur, analisis regresi, dan analisis faktor. Metode yang digunakan mencakup berbagai pendekatan statistik kompleks, termasuk teori matriks dan pemodelan struktural. Selain itu, dokumen ini menjelaskan aplikasi dan kegunaan dari berbagai teknik analisis dalam menjelaskan dan memprediksi data.