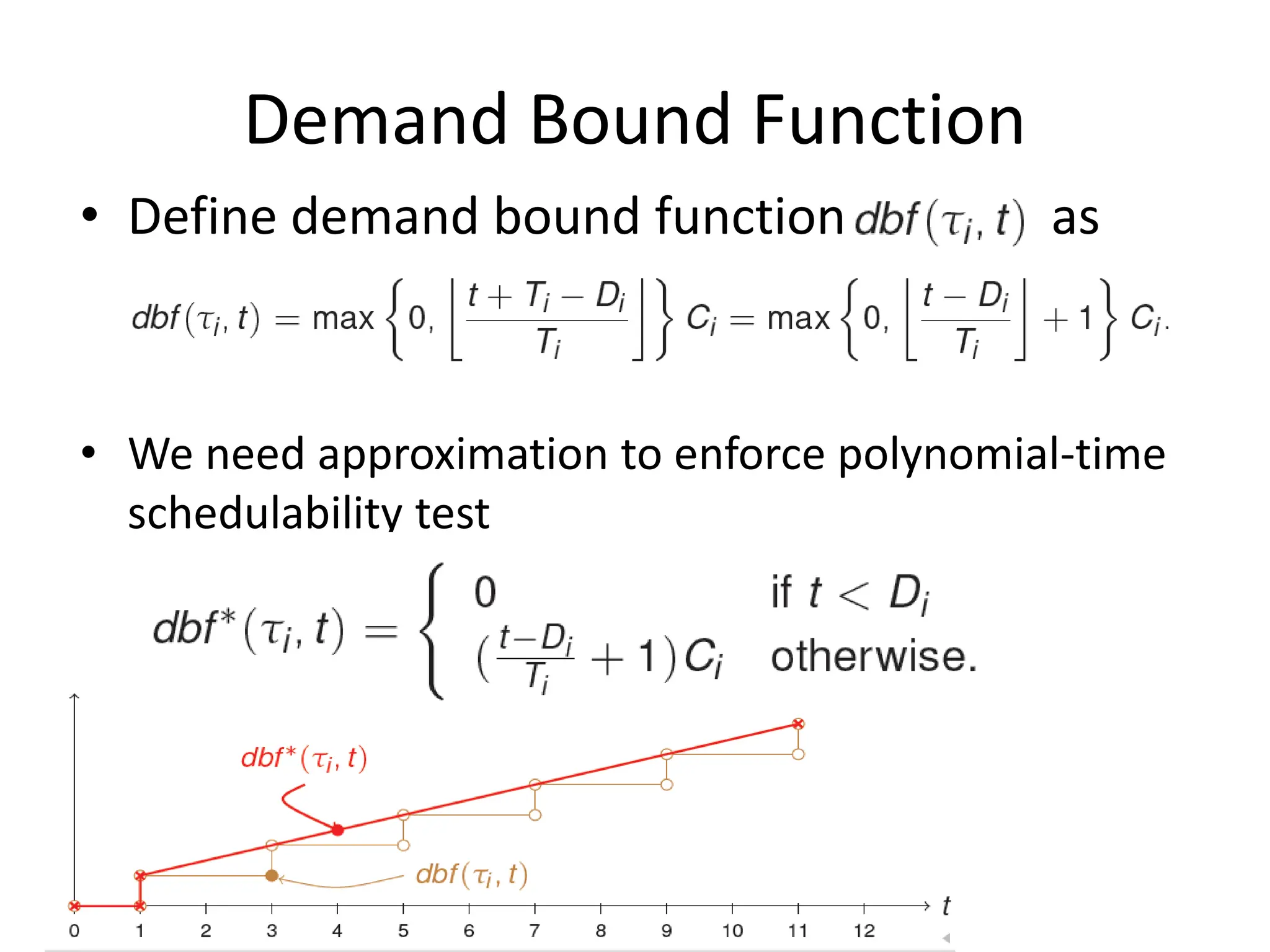
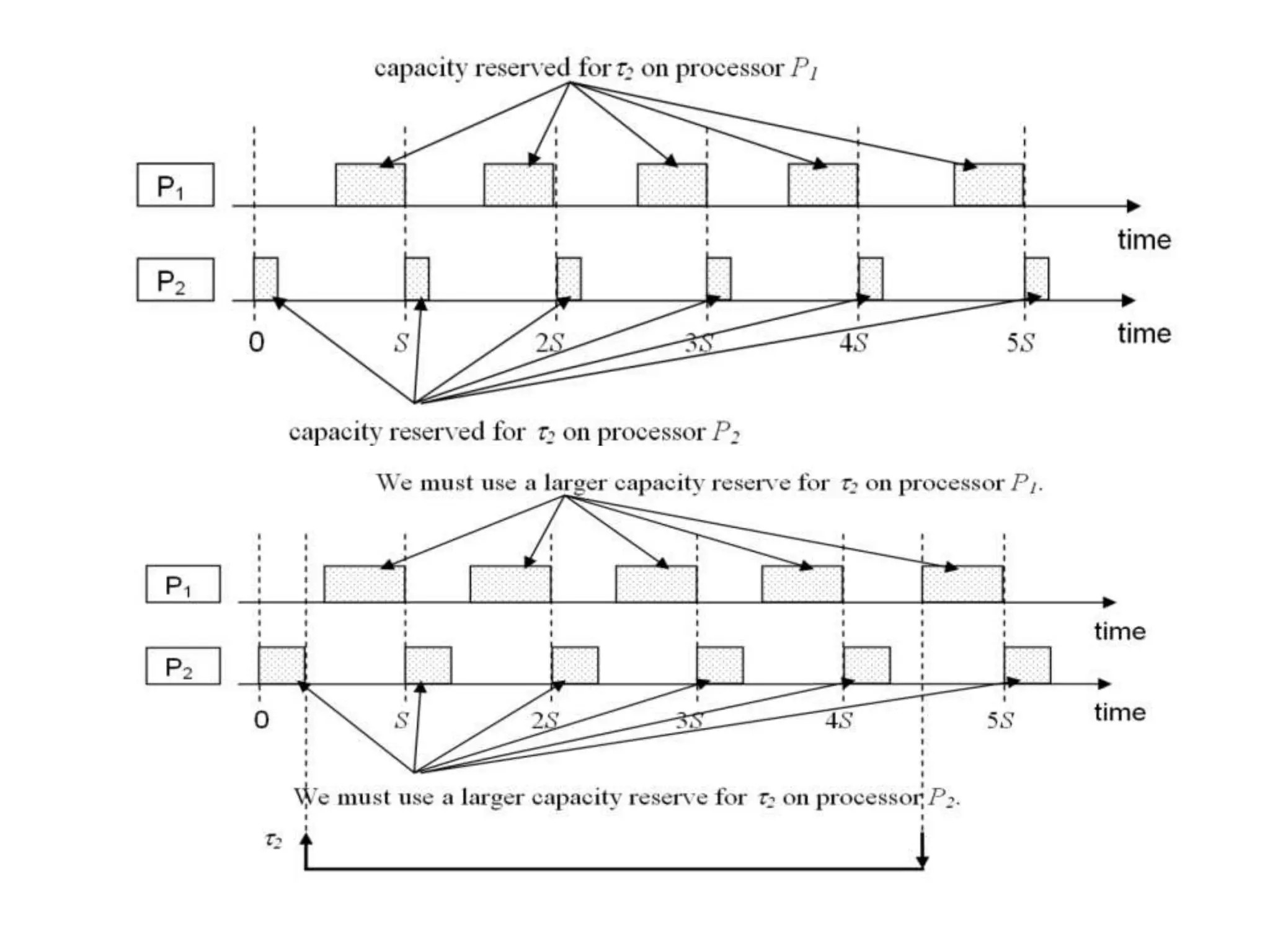
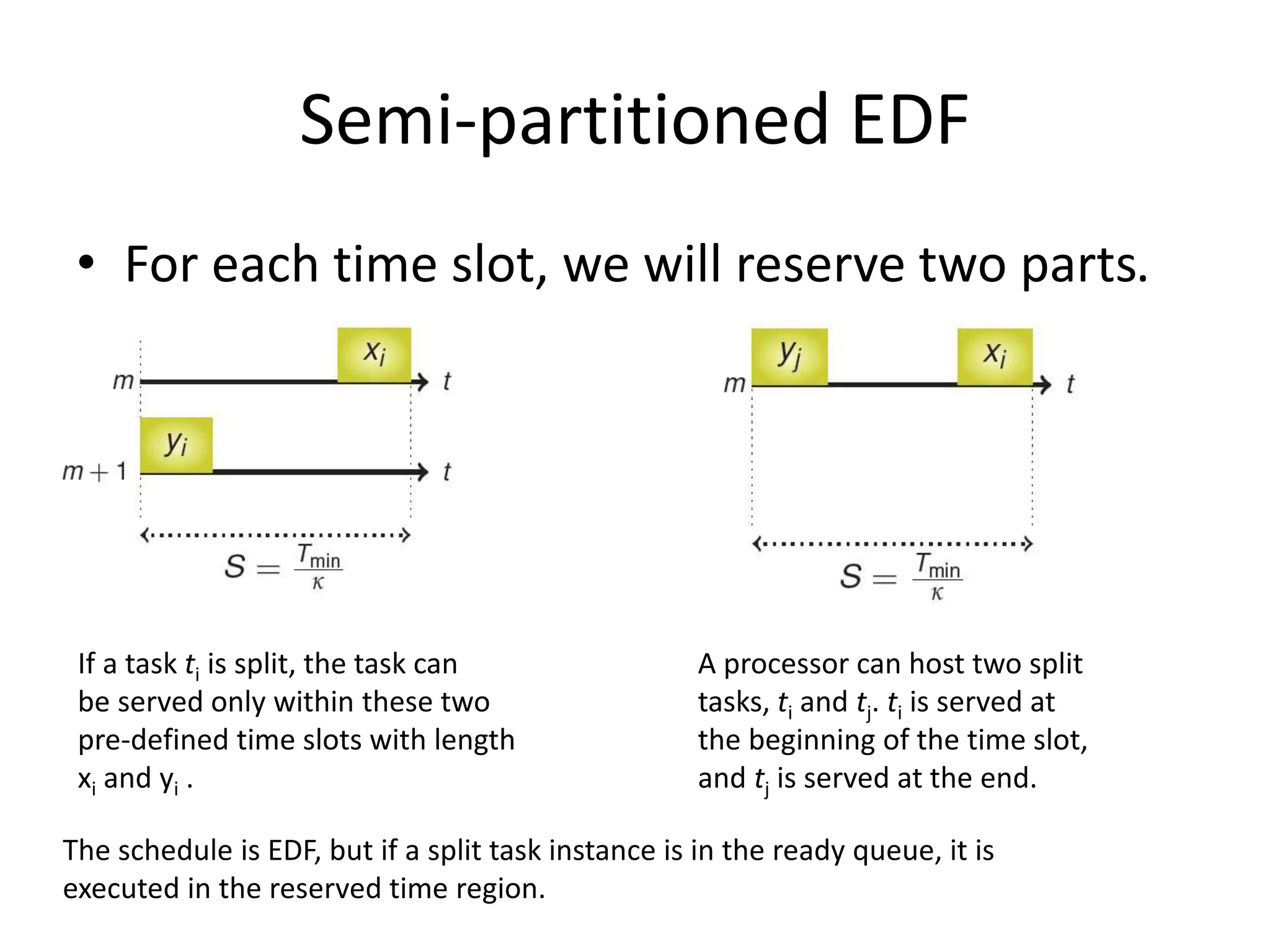
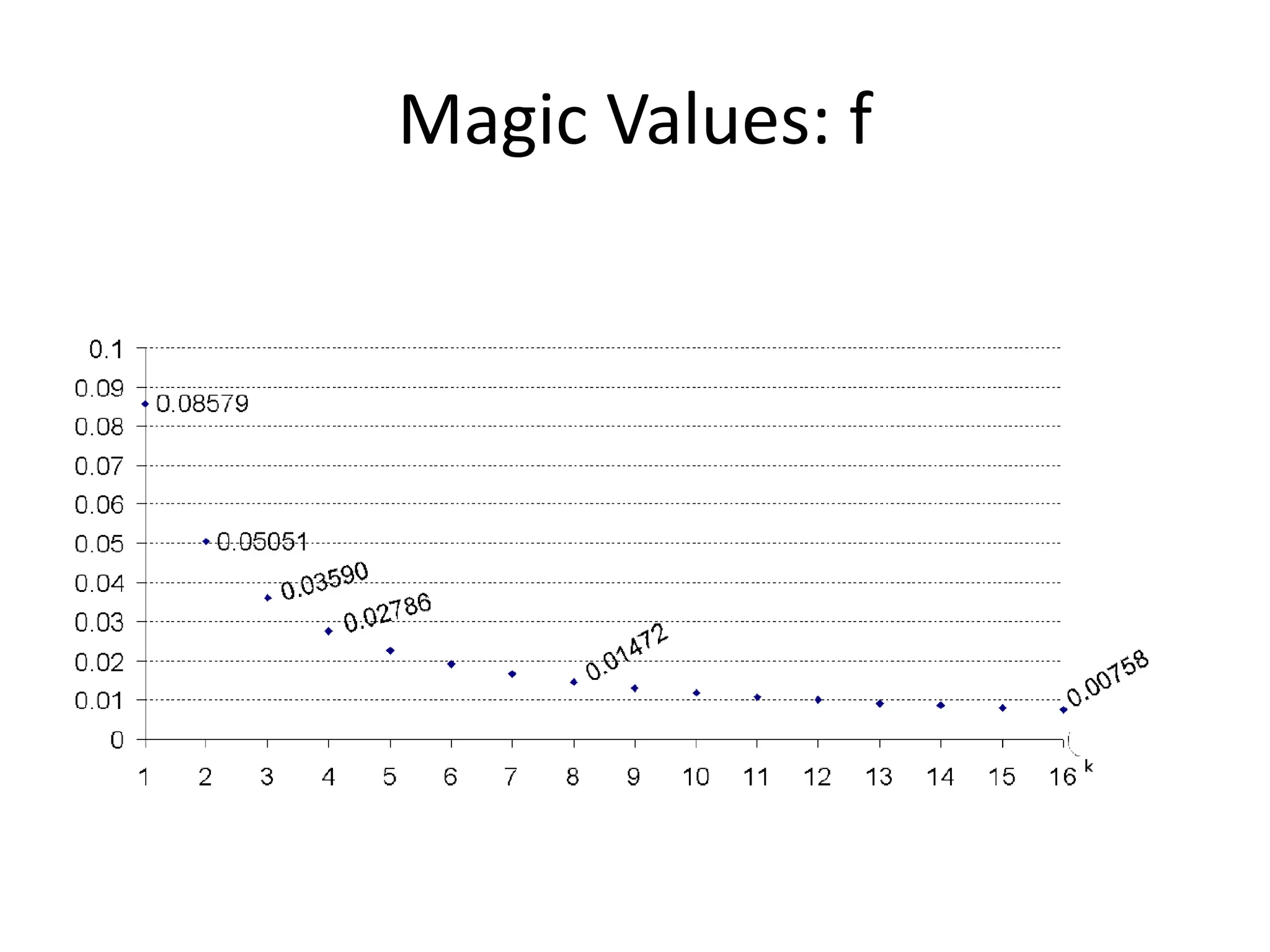
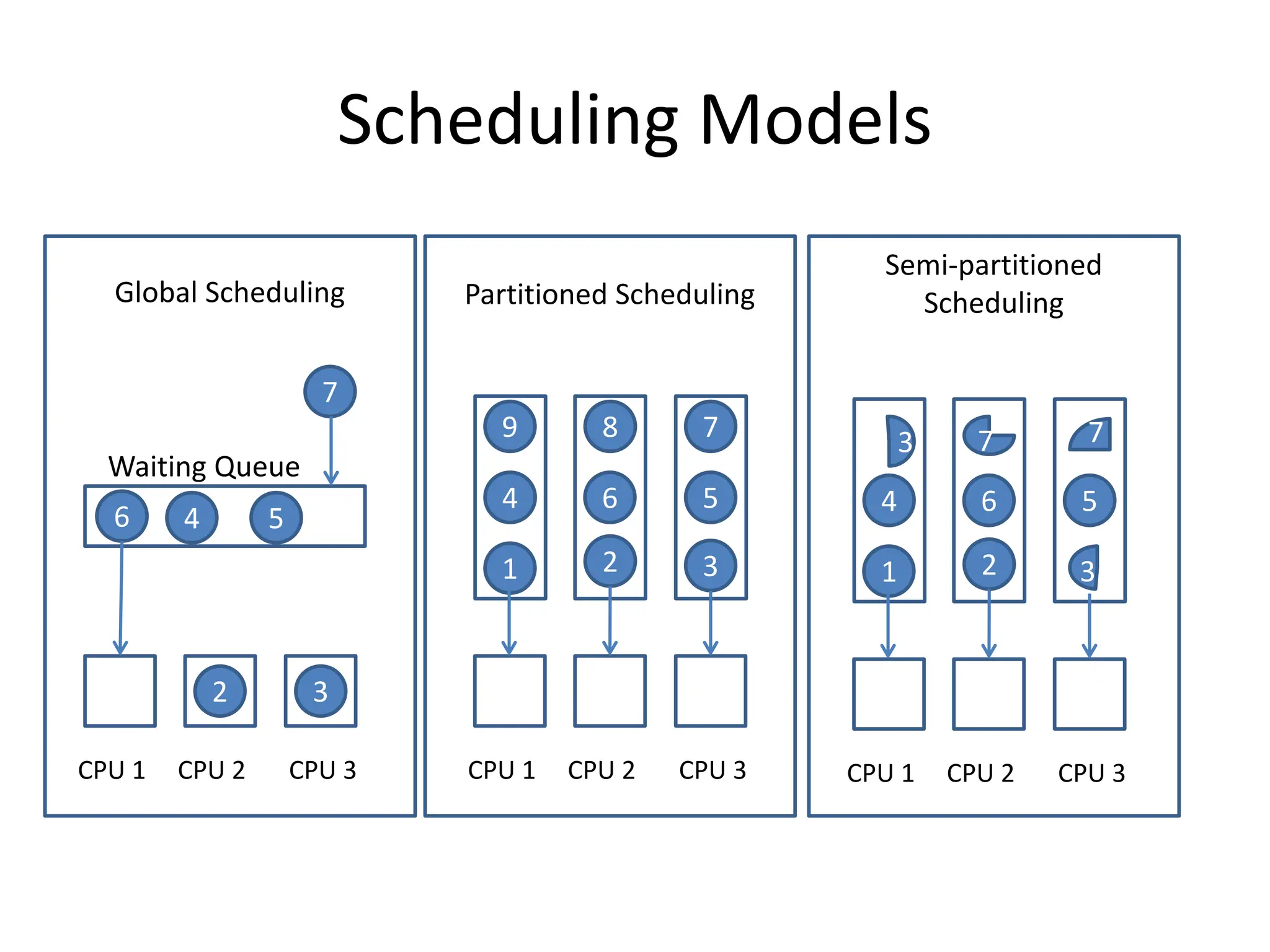
This document discusses different scheduling models for multiprocessor real-time systems, including global scheduling, partitioned scheduling, and semi-partitioned scheduling. Global scheduling uses a shared ready queue and allows tasks to migrate between processors, but can cause overhead from migration and scheduling anomalies. Partitioned scheduling assigns each task to a dedicated processor to avoid migration, but may underutilize processors. Semi-partitioned scheduling first partitions tasks then allows some to migrate to improve utilization.

















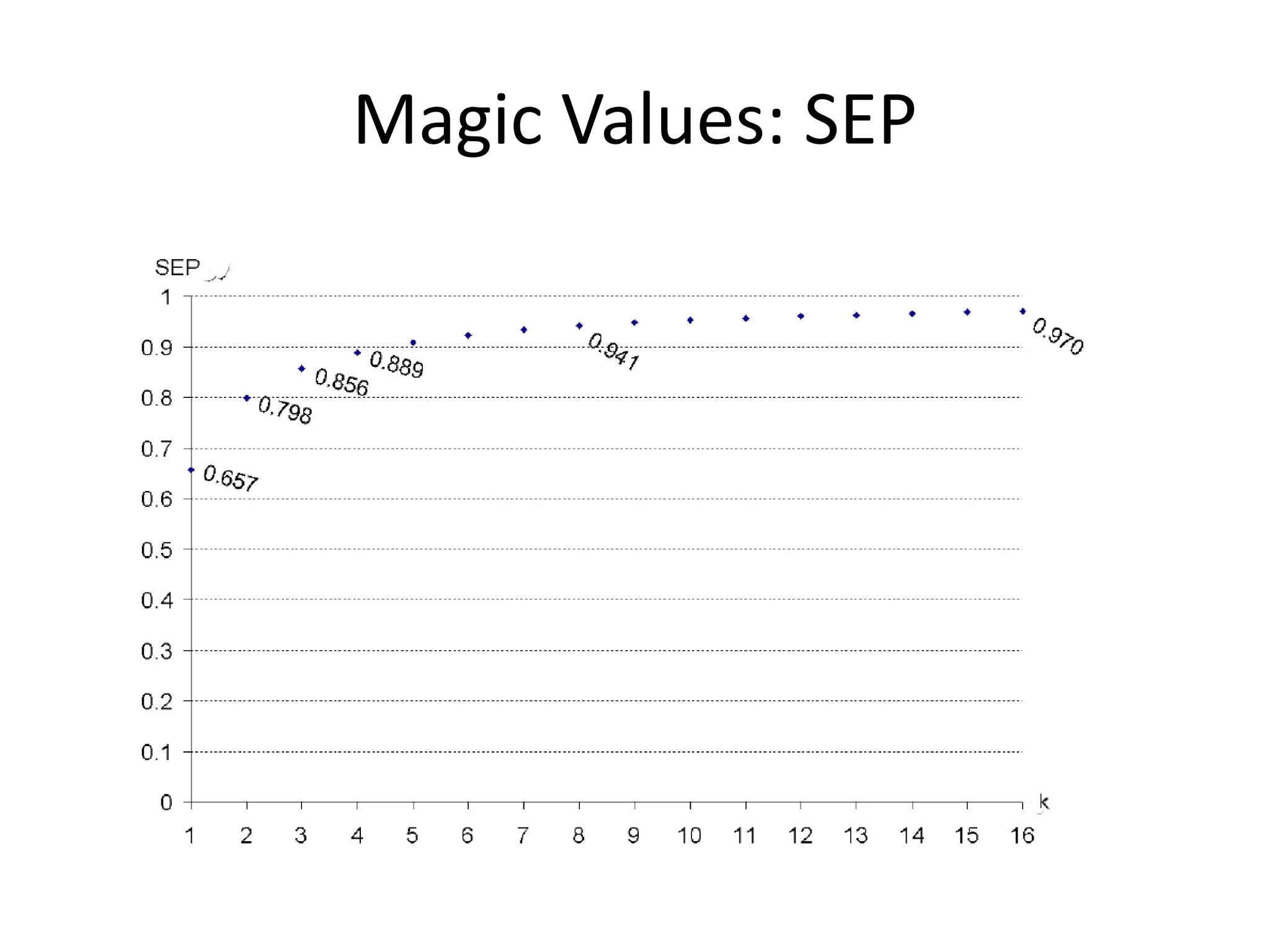
![Schedulability Test
Lopez [3] proves that the worst-case achievable utilization for
EDF scheduling and FF allocation (EDF-FF) takes the value
If all the tasks have an utilization factor C/T under a value α, where
m is the number of processors
where
1
( , )
1
EDF FF
wc
m
U m
1/
](https://image.slidesharecdn.com/11-240223093056-b82c5e33/75/multiprocessor-real_-time-scheduling-ppt-22-2048.jpg)