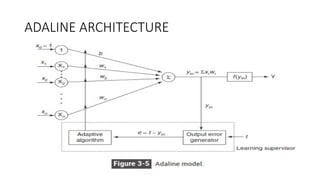
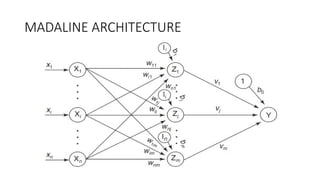
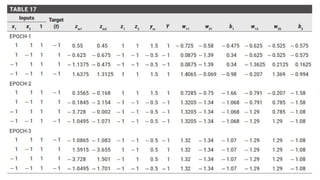
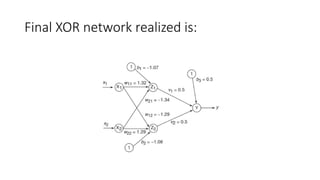
The document outlines the architecture and training process of the MADALINE model, which consists of multiple adaptive linear neurons (adalines) operating in parallel with a single output unit. It describes the adjustment of weights during training and the fixed nature of weights connecting the layers, emphasizing that the training duration for MADALINE is significantly longer than that for ADALINE. Additionally, the document touches on implementing XOR logic using the MADALINE structure and the application of the majority vote rule in certain configurations.