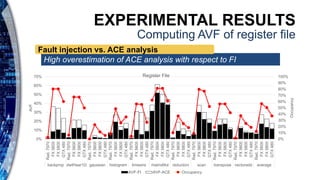
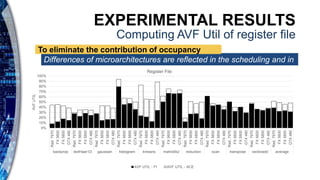
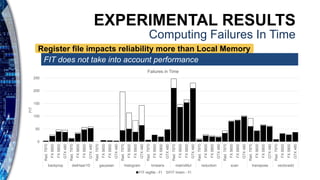
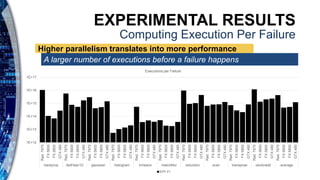
The document presents a reliability characterization framework for Nvidia and AMD GPUs, focusing on microarchitecture-level analysis to assess susceptibility to faults, particularly soft errors. It compares two reliability evaluation methodologies, ACE analysis and fault injection, and evaluates their impact on performance across different GPU architectures using benchmarks. Results indicate that reliability and performance analysis is crucial as GPUs are increasingly used in applications where fault tolerance is vital.



![• Reliability estimation framework for NVIDIA GPUs
⁃ GPGPU-Soda [Tan et al., JPC,2013] – microarchitecture-level ACE analysis
framework working on PTX assembly language
⁃ GUFI [Tselonis et al., ISPASS,2016] – microarchitecture-level fault injector
based on GPGPU-Sim
⁃ SASSIFI [Kumar et al., ISPASS, 2017] – very fast, fault injection by profiling
and debugging on real hardware
• Reliability estimation framework for AMD GPUs
⁃ [Farazmand et al., SELSE, 2012] - Evergreen AMD GPU fault injector
⁃ SIFI [Vallero et al., IOLTS, 2017] – Southern Islands microarchitecture-level
ACE analysis and fault injector framework
PREVIOUS WORKS
Reliability evaluation tools for NVIDIA and AMD
GPUs](https://image.slidesharecdn.com/presentation-long-180524093843/85/Multi-faceted-Microarchitecture-Level-Reliability-Characterization-for-NVIDIA-and-AMD-GPUs-5-320.jpg)

![THE GPU MICRO-ARCHITECTURE
An example for Southern Islands GPU
architecture
Branch Unit
Local Data Unit
Scalar Unit
SIMD
1
SIMD
2
SIMD
1
Local
Memory
Vector
Reg.
File
Scalar
Reg.
File
Front-end
Global memory
Compute unit (CU1) CU2 CU3
Ultra-thread dispatcher
Big area increases
susceptibility to soft-errors
Power consumption can be
saved by disabling the ECC
on these hardware
structures” [Fang et. al,
ISPASS 2014]
Soft-errors](https://image.slidesharecdn.com/presentation-long-180524093843/85/Multi-faceted-Microarchitecture-Level-Reliability-Characterization-for-NVIDIA-and-AMD-GPUs-8-320.jpg)
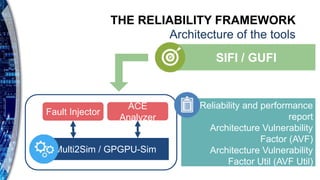
![THE FAULT INJECTION FRAMEWORK
Fault injection engine
Application
profiler
Computes time intervals in which kernels are executed and the output of
the golden simulation
Fault
generation
Generates the fault list - single bit flips uniformly distributed in time and
space
Fault profiler
Issues a simulation to profile if faults
are striking “Util” resources.
Marks simulations containing
these faults as “Util” injections
Parallel fault
injection
Performs “Util” injections
in parallel threads.
Non “Util” injections are always masked
and therefore not simulated
Error
Classification
Classifies errors based on the outcome of simulations and generates the
reliability report
describes the programming models and architectures of the
considered GPUs. Section III discusses the reliability
evaluation framework. Results are presented and discussed in
Section IV. Related works are reported in Section V, and
Section VI concludes the paper.
II. A. GPU ARCHITECTURES AND PROGRAMMING MODELS
In our study, we considered four GPU chips with different
architectures: AMD HD RadeonTM
7970 (Southern Islands
architecture), NVIDIA QuadroTM
FX 5600 (G80 architecture),
NVIDIA QuadroTM
FX5800 (GT200 architecture) and
NVIDIA GeforceTM
GTX 480 (Fermi architecture). We
performed our analysis using a set of 10 benchmarks coded
using the OpenCL programming language for the AMD
Southern Islands chip and the CUDA programming language
for the NVIDIA chips. OpenCL [13] and CUDA [14] are the
most widespread GPGPU programming languages and both
represent abstractions of the physical hardware. Both languages
rely on similar concepts and explore the Single Instruction
Multiple Data (SIMD) paradigm. Throughout the paper, we use
the OpenCL and AMD terminology. Readers more familiar
with CUDA can refer to Fig. 1 and Fig. 2 where
CUDA/NVIDIA terminology is reported in parentheses next to
the OpenCL/AMD terms.
From the hardware standpoint (Fig. 1), a GPU typically
consists of several compute units (CU) sharing a global
memory and managed by a dispatcher. Each CU contains
multiple processing elements (PEs), each one including a set of
functional units (e.g., integer unit, floating point unit, etc.) and
a register file (typically a portion of a global register file split
and assigned to the different PEs). The CU also includes a local
memory and a scheduler that distributes and coordinates the
work of the different PEs. The PEs are grouped into SIMD
Units. All PEs in a SIMD Unit share the instruction
fetch/dispatch logic and execute the same instruction
concurrently.
Fig. 1. A generic GPU architecture. Nomenclature follows the
OpenCL/AMD model with equivalent CUDA/NVIDIA terms in
parentheses (when different).
Fig. 2 graphically represents the OpenCL/CUDA
programming model that can be mapped on the GPU
architecture of Fig. 1. Parallel portions of the application are
executed in parallel on the PEs of a SIMD Unit (Fig. 1)
constitutes a wavefront. Work-items are also aggregated in
work-groups. Each work-group is independent from the others.
Work-items belonging to the same work-group can be
synchronized and can communicate with each other through a
common memory space named local memory. Every time a
work-group must be executed it is assigned to a compute unit
(CU). The availability of multiple CUs enables the
accommodation of a large number of work-groups. Finally, a
set of work-groups that are concurrently scheduled to run on a
GPU constitute a ND-Range. The ND-Range provides a global
memory shared by all the work-groups. Communication among
different work-groups is not allowed.
Fig. 2. The OpenCL/CUDA programming model for AMD and NVIDIA
GPUs.
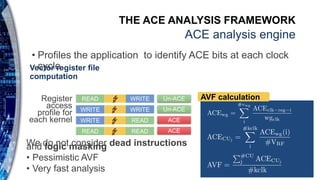
III. RELIABILITY EVALUATION FRAMEWORK
This section introduces the framework we developed to
analyze reliability and performance of different GPU
architectures and workloads. The framework includes two tools
named GUFI and SIFI. GUFI, previously presented in [8] has
been developed to perform reliability analysis on NVIDIA
GPUs. It is based on the GPGPU-Sim (v3.2.2) [33] micro
architectural simulator and is able to perform complex fault-
injection campaigns supporting both the SASS and PTX
assembly languages. GUFI has been extended for the purposes
of our study to perform ACE-based analysis. Similarly, to
GUFI, SIFI is a fault injection and ACE analysis tool
developed to characterize AMD GPUs [31]. SIFI is built on top
of the Mult2Sim (v4.2) microarchitectural simulator and
supports the Southern Island assembly language [28]. For both
tools, reliability is analyzed looking at the low-level assembly
code running on the real hardware. Therefore, for NVIDIA
GPUs, the SASS assembly is used instead of the PTX. This
gives access to the real architectural registers and, therefore,
allows for a fair comparison of NVIDIA and AMD chips.
This study focuses on soft-errors, i.e., bit-flips of a memory
element mainly caused by radiations, thermal cycling,
transistor variability and erratic fluctuation of voltage.
Global memory (Global memory)
Compute Unit
(Streaming
Multiprocessor)
Ultra-Threaded Dispatcher (Thread Block Scheduler)
Wavefront(Warp)
scheduler
Local Memory (Shared memory)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
PE
(TP)
Register
File
Functional
Units
Register
File
SIMD Unit (SFU) SIMD Unit (SFU)
Private memory
(Local memory)
__kernel func {
…
…
}
Work-Item (Thread)
Work-item
Wavefront (Warp)
Work-item
Work-item
Work-item
...
Wavefront Wavefront
Wavefront Wavefront
Local memory (Shared memory)
Work-group (Block)
Global memory (Global memory)
NDRange (Grid)
Work-group Work-group
Work-group Work-group...
...
... ...
Comment [
CU1
WI0
R0 R1 Rn
WI1
WG0
WG1](https://image.slidesharecdn.com/presentation-long-180524093843/85/Multi-faceted-Microarchitecture-Level-Reliability-Characterization-for-NVIDIA-and-AMD-GPUs-9-320.jpg)
![EXPERIMENTAL RESULTS
Experimental
setup
CHIP FX FX 5800 GTX
480
HD 7970
Technology 90nm 55nm 28 nm 28 nm
λ FIT/bit* 1E-3 0.72E-3 0.52E- 0.32E-3
Vendor NVIDIA NVIDIA NVIDIA AMD
Architecture G80 GT200 Fermi Southern
Islands
Vector
File
64KB 64KB 128KB 256 KB
Local Memory 16KB 16KB 64KB 64 KB
SIMD Units 1 2 4 4
(1) Backprop, (2) DWTHaar1D, (3) Gaussian, (4) Histogram, (5)Kmeans,
(6)MatrixMultiplication, (7) Reduction, (8) Scan (9) MatrixTranspose, (10) VectorAdd
10 benchmarks from AMD-APP SDK, CUDA SDK, RODINIA
Statistical fault sampling
e = 3% error margin
t = 95% confidence level
p = 0.5
N = structure size
2K injections per
structure* [Ibe et al. T-ED, 2010]](https://image.slidesharecdn.com/presentation-long-180524093843/85/Multi-faceted-Microarchitecture-Level-Reliability-Characterization-for-NVIDIA-and-AMD-GPUs-11-320.jpg)