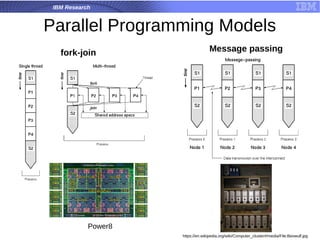
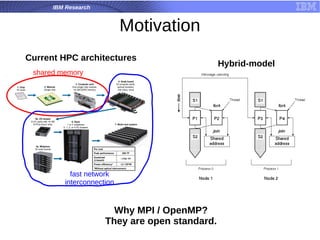
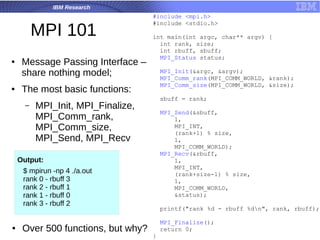
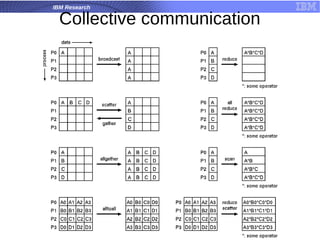
The document is a tutorial on hybrid parallel programming using MPI and OpenMP, covering essential functions, motivation for using these parallel programming standards, and performance examples. It introduces concepts such as message passing, collective communication, and the advantages of adaptive MPI (AMPI) for modern applications. The tutorial also discusses the features and limitations of MPI/OpenMP in high-performance computing contexts.









![IBM Research
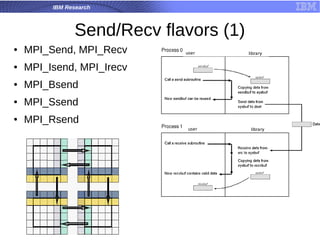
One-sided communication
Active target
MPI_Alloc_mem(sizeof(int)*size, MPI_INFO_NULL, &a);
MPI_Alloc_mem(sizeof(int)*size, MPI_INFO_NULL, &b);
MPI_Win_create(a, size, sizeof(int), MPI_INFO_NULL,
MPI_COMM_WORLD, &win);
for (i = 0; i < size; i++)
a[i] = rank * 100 + i;
printf("Process %d has the following:", rank);
for (i = 0; i < size; i++)
printf(" %d", a[i]);
printf("n");
MPI_Win_fence((MPI_MODE_NOPUT | MPI_MODE_NOPRECEDE), win);
for (i = 0; i < size; i++)
MPI_Get(&b[i], 1, MPI_INT, i, rank, 1, MPI_INT, win);
MPI_Win_fence(MPI_MODE_NOSUCCEED, win);
printf("Process %d obtained the following:", rank);
for (i = 0; i < size; i++)
printf(" %d", b[i]);
printf("n");
MPI_Win_free(&win);](https://image.slidesharecdn.com/ibm-eduardo-usp-workshop-150603110532-lva1-app6892/85/Programacao-paralela-hibrida-com-MPI-e-OpenMP-uma-abordagem-pratica-Eduardo-Rodrigues-IBM-Research-Brasil-14-320.jpg)
![IBM Research
Level of Thread Support
●
MPI_THREAD_SINGLE - Level 0: Only one thread will execute.
● MPI_THREAD_FUNNELED - Level 1: The process may be multi-threaded, but only
the main thread will make MPI calls - all MPI calls are funneled to the main thread.
●
MPI_THREAD_SERIALIZED - Level 2: The process may be multi-threaded, and
multiple threads may make MPI calls, but only one at a time. That is, calls are not
made concurrently from two distinct threads as all MPI calls are serialized.
● MPI_THREAD_MULTIPLE - Level 3: Multiple threads may call MPI with no
restrictions.
int MPI_Init_thread(int *argc, char *((*argv)[]),
int required, int *provided)](https://image.slidesharecdn.com/ibm-eduardo-usp-workshop-150603110532-lva1-app6892/85/Programacao-paralela-hibrida-com-MPI-e-OpenMP-uma-abordagem-pratica-Eduardo-Rodrigues-IBM-Research-Brasil-15-320.jpg)


![IBM Research
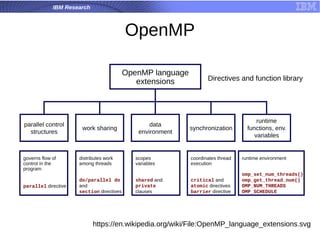
OpenMP 101
● Parallel loops
● Data environment
● Synchronization
● Reductions
#include <omp.h>
#include <stdio.h>
#define SX 4
#define SY 4
int main() {
int mat[SX][SY];
omp_set_nested(1);
printf(">>> %dn", omp_get_nested());
#pragma omp parallel for num_threads(2)
for (int i = 0; i < SX; i++) {
int outerId = omp_get_thread_num();
#pragma omp parallel for num_threads(2)
for (int j = 0; j < SY; j++) {
int innerId = omp_get_thread_num();
mat[i][j] = (outerId+1)*100 + innerId;
}
}
for (int i = 0; i < SX; i++) {
for (int j = 0; j < SX; j++) {
printf("%d ", mat[i][j]);
}
printf("n");
}
}](https://image.slidesharecdn.com/ibm-eduardo-usp-workshop-150603110532-lva1-app6892/85/Programacao-paralela-hibrida-com-MPI-e-OpenMP-uma-abordagem-pratica-Eduardo-Rodrigues-IBM-Research-Brasil-20-320.jpg)




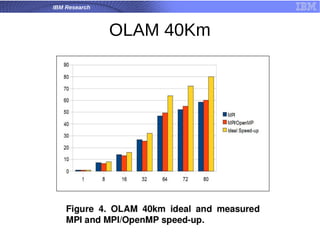
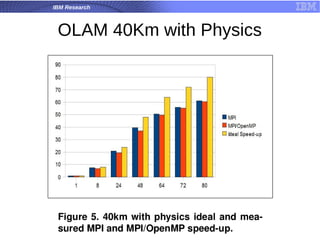
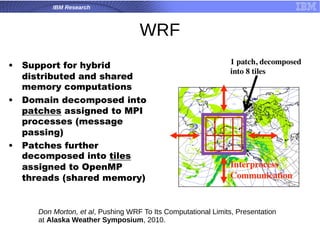
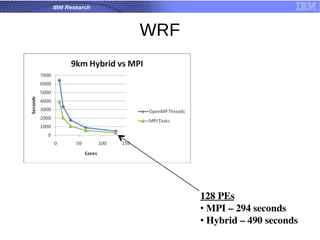























































![What is [Open] MPI?](https://cdn.slidesharecdn.com/ss_thumbnails/test-1230829557420508-1-thumbnail.jpg?width=640&height=640&fit=bounds)





































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



