Download as KEY, PPTX

















![MongoDB is:
Application Document
Oriented
{ author: “steve”,
High date: new Date(),
text: “About MongoDB...”,
Performance tags: [“tech”, “database”]}
Fully
Consistent
Horizontally Scalable](https://image.slidesharecdn.com/mongoecommerceandtransactionsla-111209001510-phpapp02/75/MongoDB-E-commerce-and-Transactions-22-2048.jpg)



































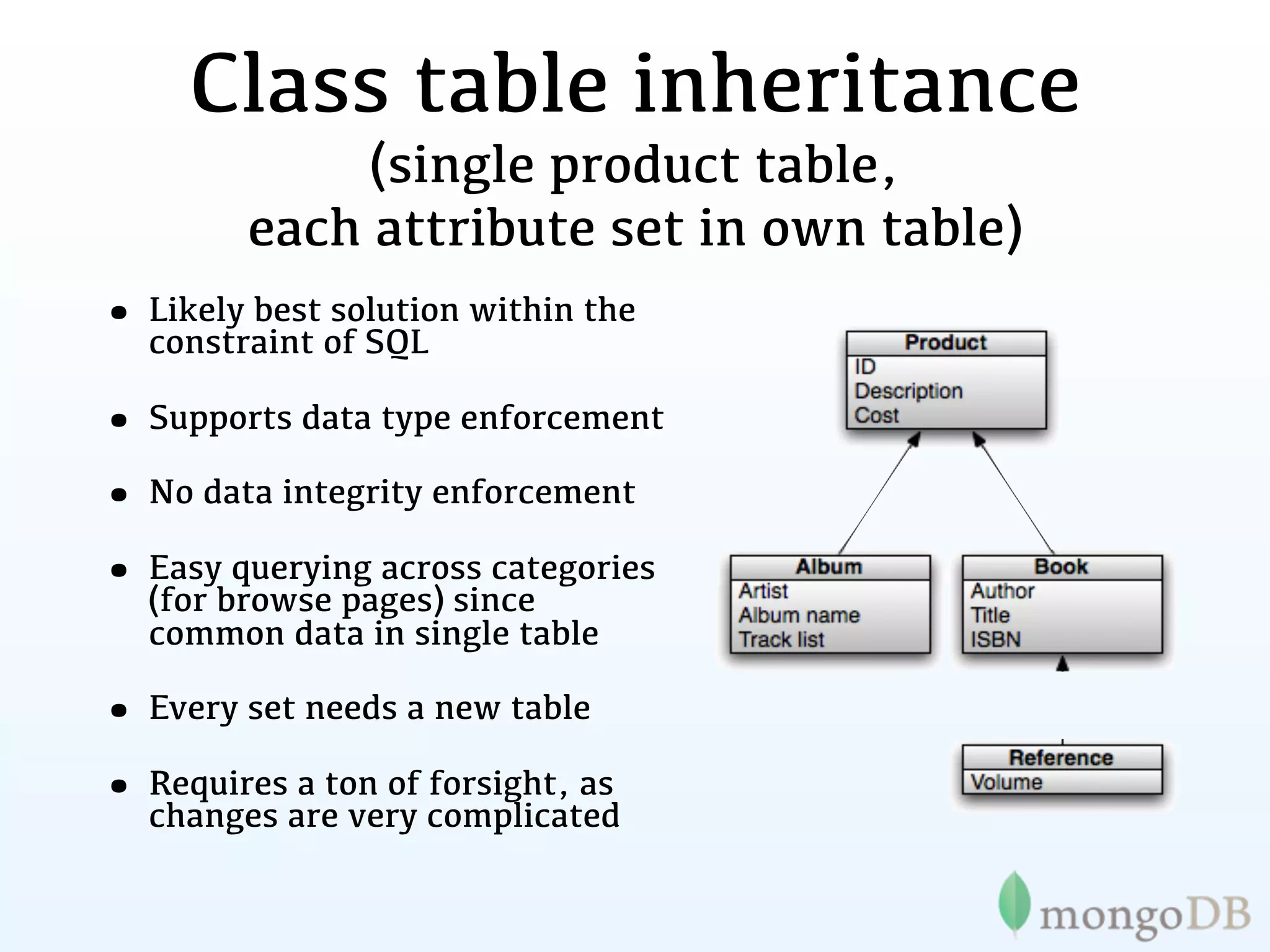






![pct_savings: 20 pct_savings: 8.5
}, },
details: { details: {
title: "Hoss", title: "The Matrix",
artist: "Lagwagon", director: [ "Andy Wachowski", "Larry Wa
genre: [ "Punk", "Hardcore", "Indie Rock" ], [ "Andy Wachowski", "Larry Wach
writer:
label: "Fat Wreck Chords", actor: [ "Keanu Reeves" , "Lawrence Fis
number_of_discs: 1, genre: [ "Science Fiction", "Action" ],
issue_date: "November 21, 1995", number_of_discs: 1,
format: "CD", issue_date: "May 15 2007",
alternate_formats: [ 'Vinyl', 'MP3' ],original_release_date: "1999",
tracks: [ disc_format: "DVD",
"Kids Don't Like To Share", rating: "R",
"Violins", alternate_formats: [ 'VHS', 'Bluray' ],
"Name Dropping", run_time: "136",
"Bombs Away", studio: "Warner Bros",
"Move The Car", language: "English",
"Sleep", format: [ "AC-3", "Closed-captioned", "
"Sick", aspect_ratio: "1.66:1"
"Rifle", },
"Weak", }
"Black Eye",
"Bro Dependent",
"Razor Burn",
"Shaving Your Head",
"Ride The Snake",
],](https://image.slidesharecdn.com/mongoecommerceandtransactionsla-111209001510-phpapp02/75/MongoDB-E-commerce-and-Transactions-69-2048.jpg)

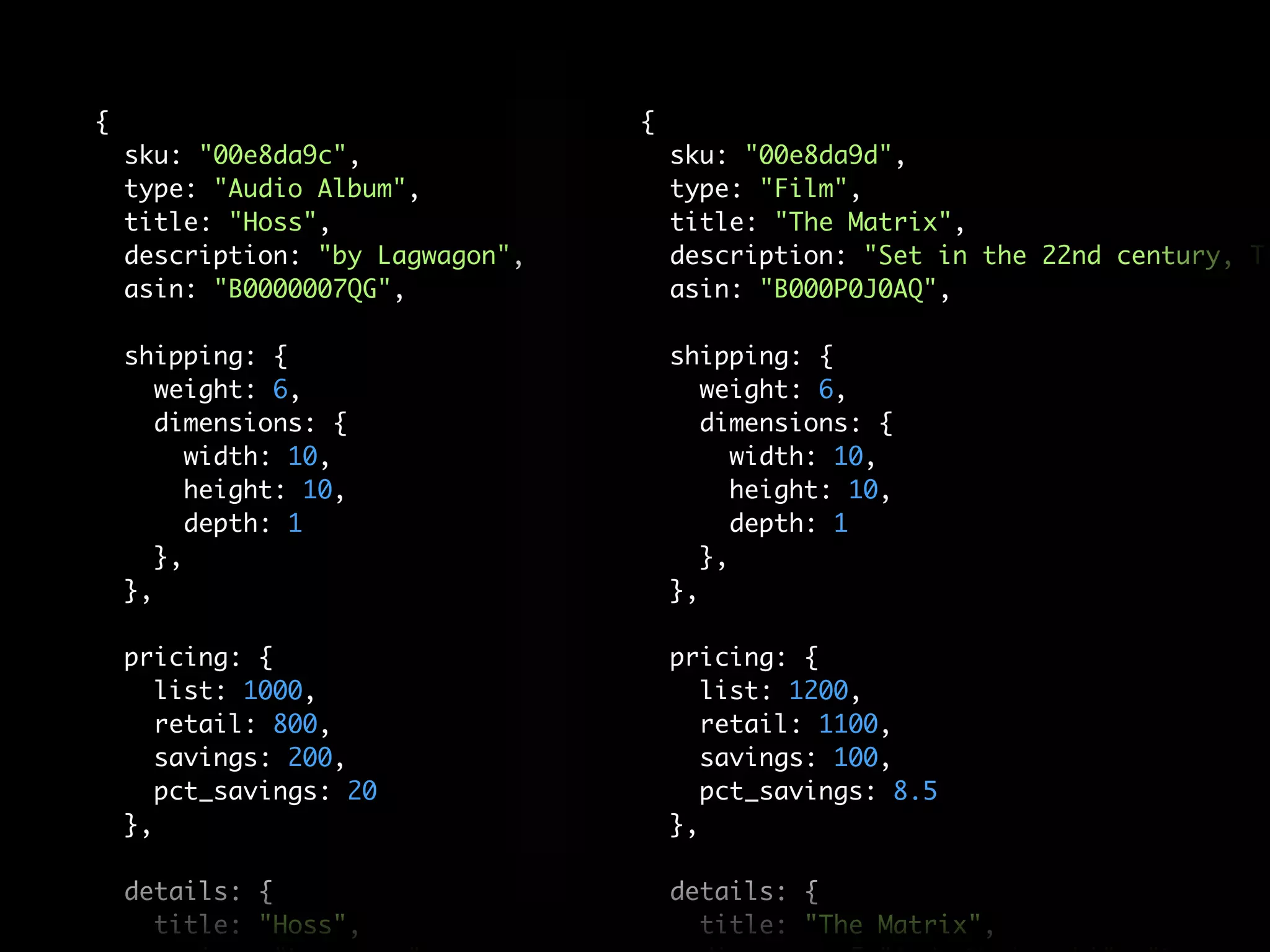
![db.products.find( { 'details.actor': "Groucho Marx" } );
},
"pricing": {
"list": 1000,
"retail": 800,
"savings": 200,
"pct_savings": 20
},
"details": {
"title": "A Night at the Opera",
"director": "Sam Wood",
"actor": ["Groucho Marx", "Chico Marx", "Harpo Marx"],
"genre": "Comedy",
"number_of_discs": 1,
"issue_date": "May 4 2004",
"original_release_date": "1935",
"disc_format": "DVD",](https://image.slidesharecdn.com/mongoecommerceandtransactionsla-111209001510-phpapp02/75/MongoDB-E-commerce-and-Transactions-74-2048.jpg)

![db.products.find( {
'details.genre': "Jazz", 'details.format': "CD"
} );
"list": 1200,
"retail": 1100,
"savings": 100,
"pct_savings": 8
},
"details": {
"title": "A Love Supreme [Original Recording Reissued]",
"artist": "John Coltrane",
"genre": ["Jazz", "General"],
"format": "CD",
"label": "Impulse Records",
"number_of_discs": 1,
"issue_date": "December 9, 1964",
"alternate_formats": ["Vinyl", "MP3"],
"tracks": [
"A Love Supreme Part I: Acknowledgement",](https://image.slidesharecdn.com/mongoecommerceandtransactionsla-111209001510-phpapp02/75/MongoDB-E-commerce-and-Transactions-76-2048.jpg)
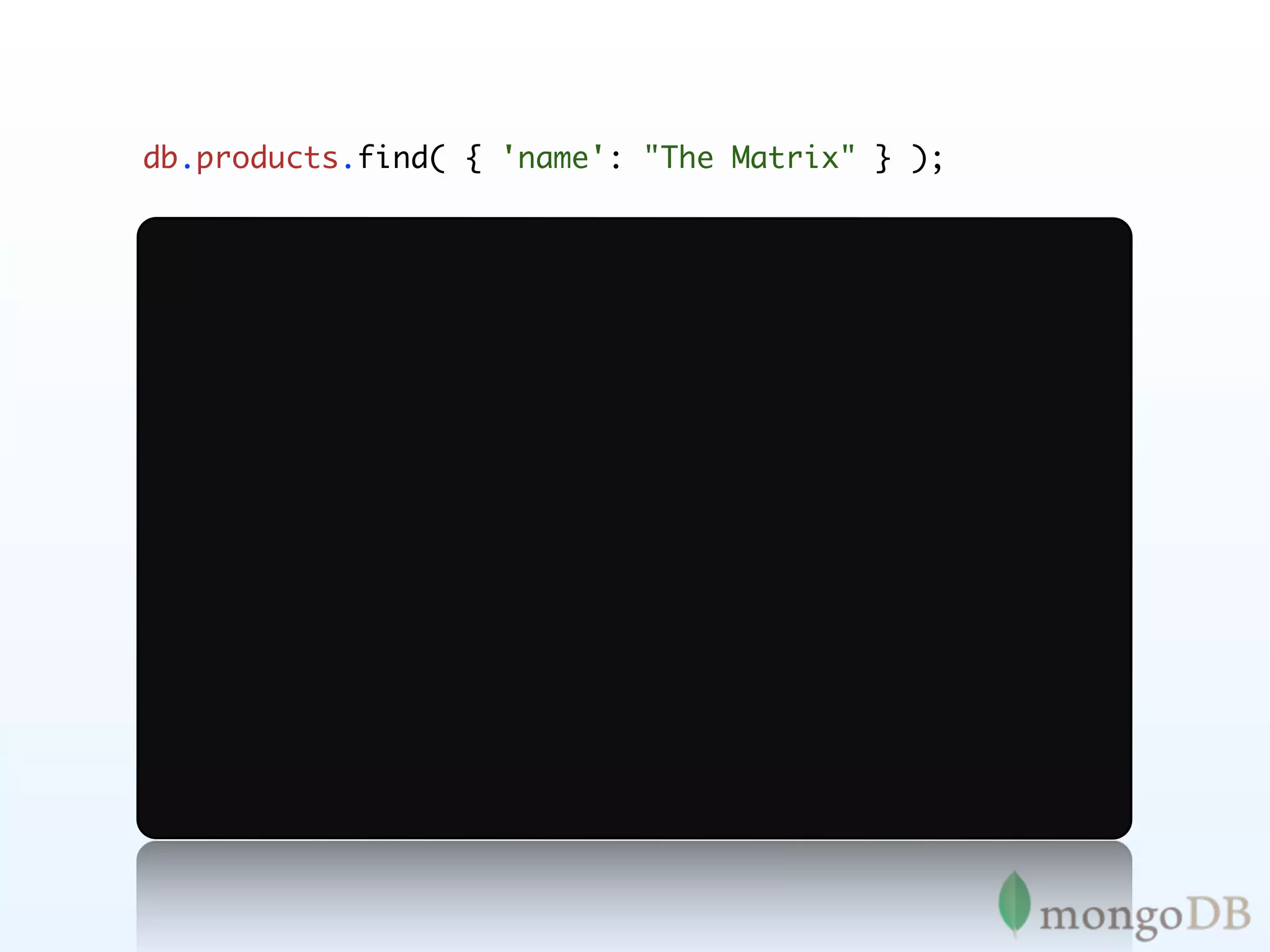
![db.products.find( { 'details.actor':
{ $all: ['James Stewart', 'Donna Reed'] }
} );](https://image.slidesharecdn.com/mongoecommerceandtransactionsla-111209001510-phpapp02/75/MongoDB-E-commerce-and-Transactions-77-2048.jpg)
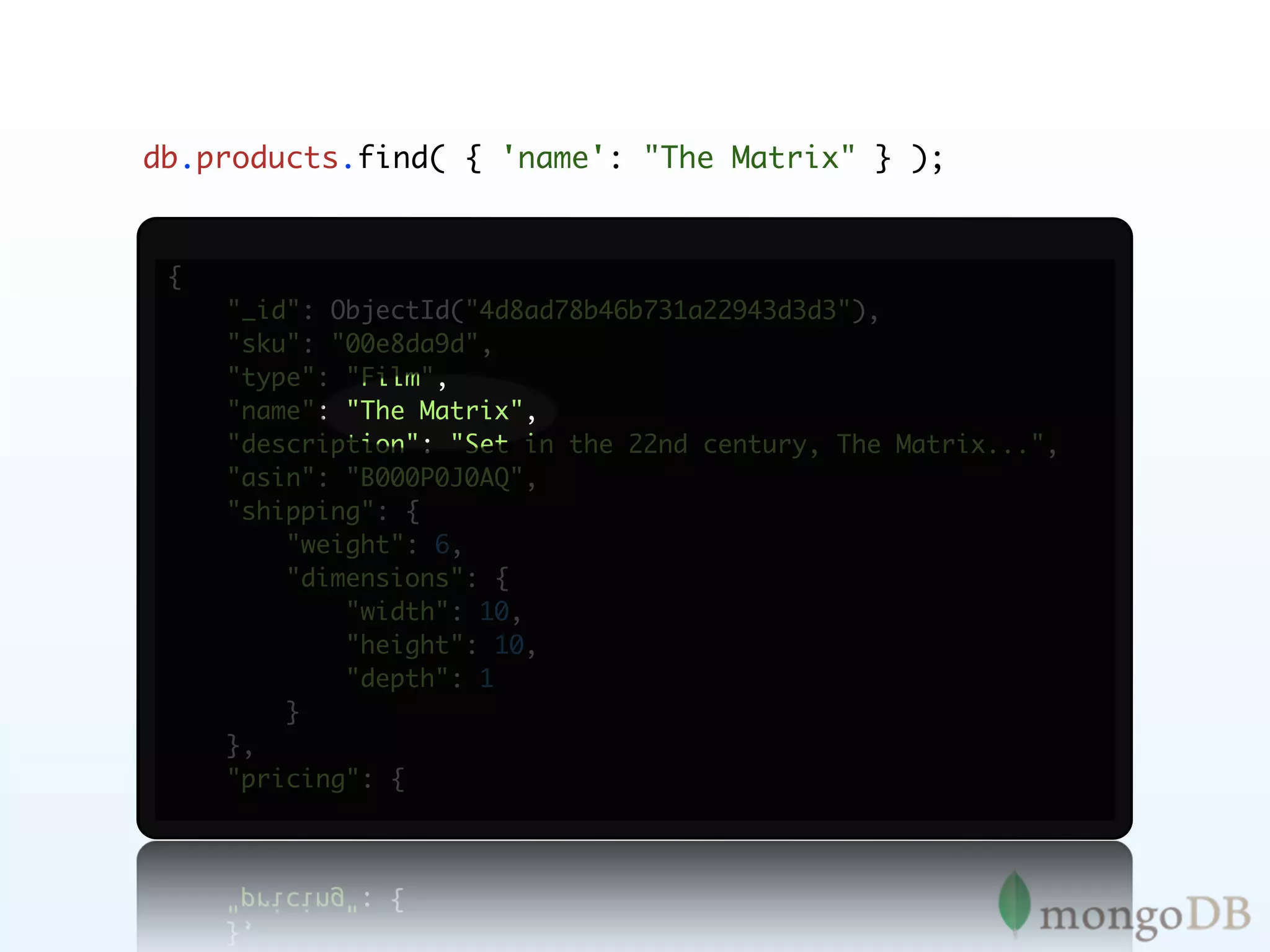
![db.products.find( { 'details.actor':
{ $all: ['James Stewart', 'Donna Reed'] }
} );
},
"details": {
"title": "It's a Wonderful Life",
"director": "Frank Capra",
"actor": ["James Stewart", "Donna Reed", "Lionel Barrymore"],
"writer": [
"Frank Capra",
"Albert Hackett",
"Frances Goodrich",
"Jo Swerling",
"Michael Wilson"
],
"genre": "Drama",
"number_of_discs": 1,
"issue_date": "Oct 31 2006",
"original_release_date": "1947",](https://image.slidesharecdn.com/mongoecommerceandtransactionsla-111209001510-phpapp02/75/MongoDB-E-commerce-and-Transactions-78-2048.jpg)

















































































This document provides information about MongoDB and its suitability for e-commerce applications. It discusses how MongoDB allows for a flexible schema that can accommodate different product types like books, music albums, jeans, without needing to define all attributes in advance. This flexibility addresses the "data dilemma" that traditional relational databases have in modeling diverse e-commerce data. Examples of companies successfully using MongoDB for e-commerce are also provided.




































































![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)




![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)