Download as PDF, PPTX






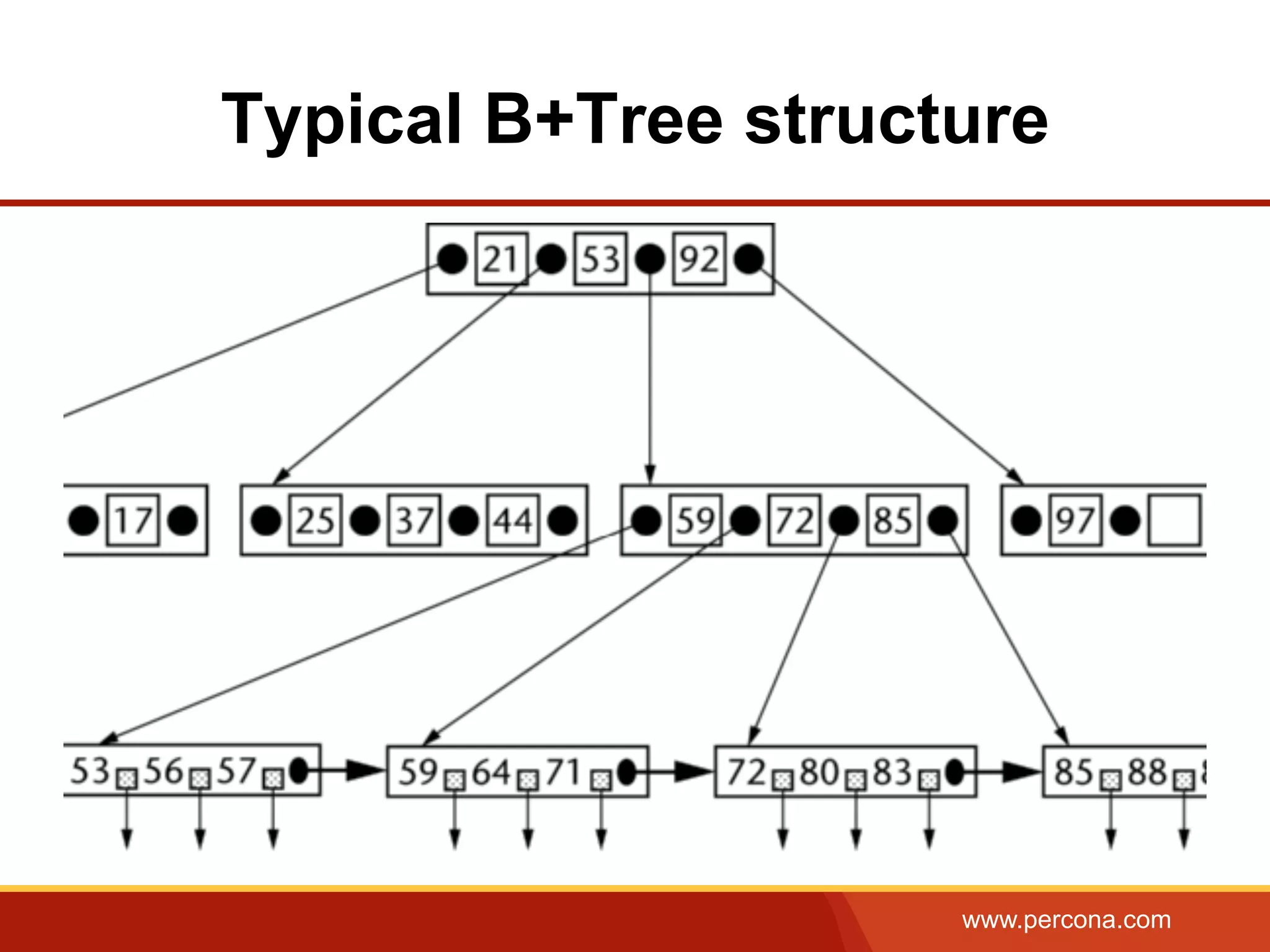











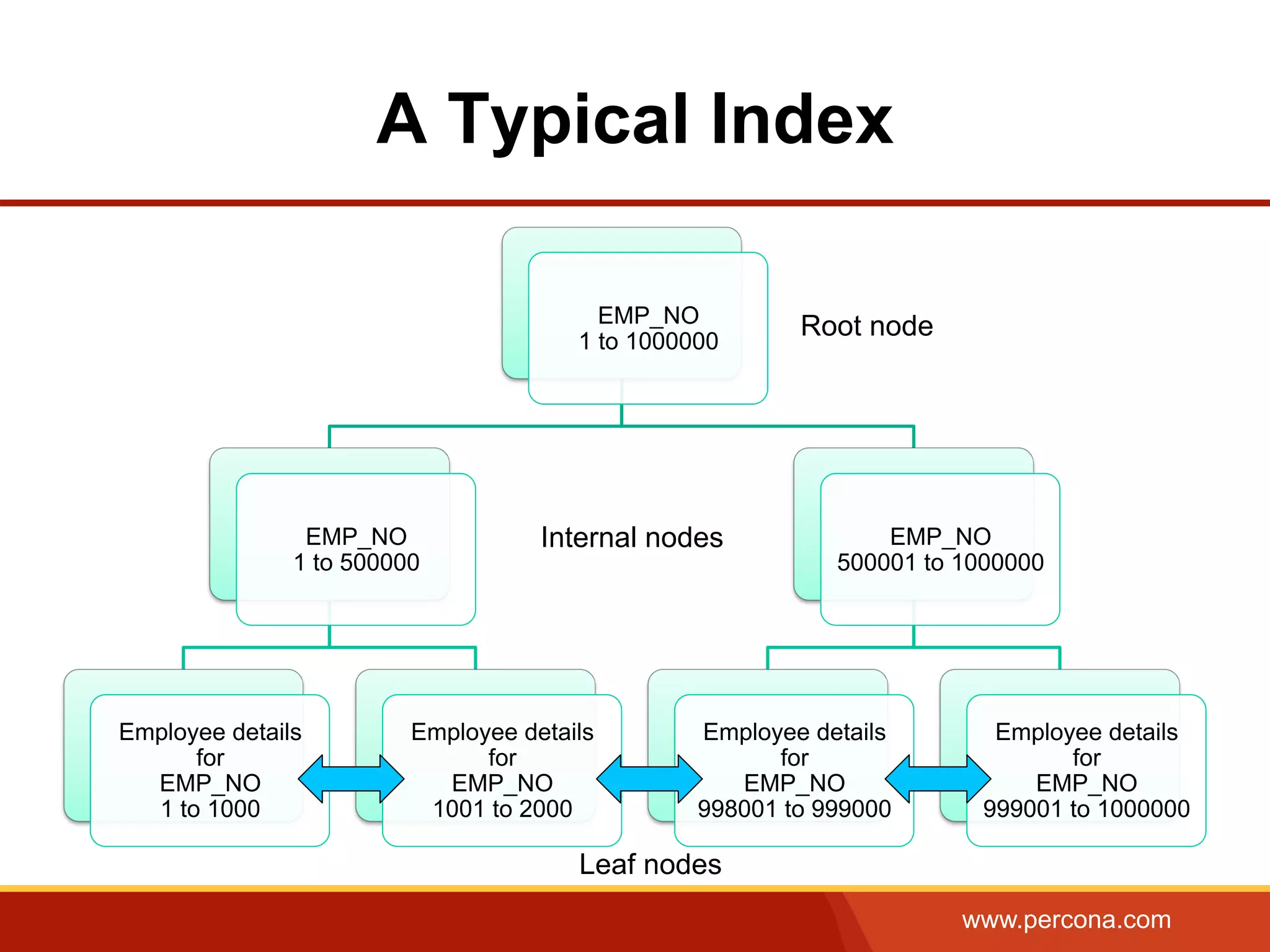


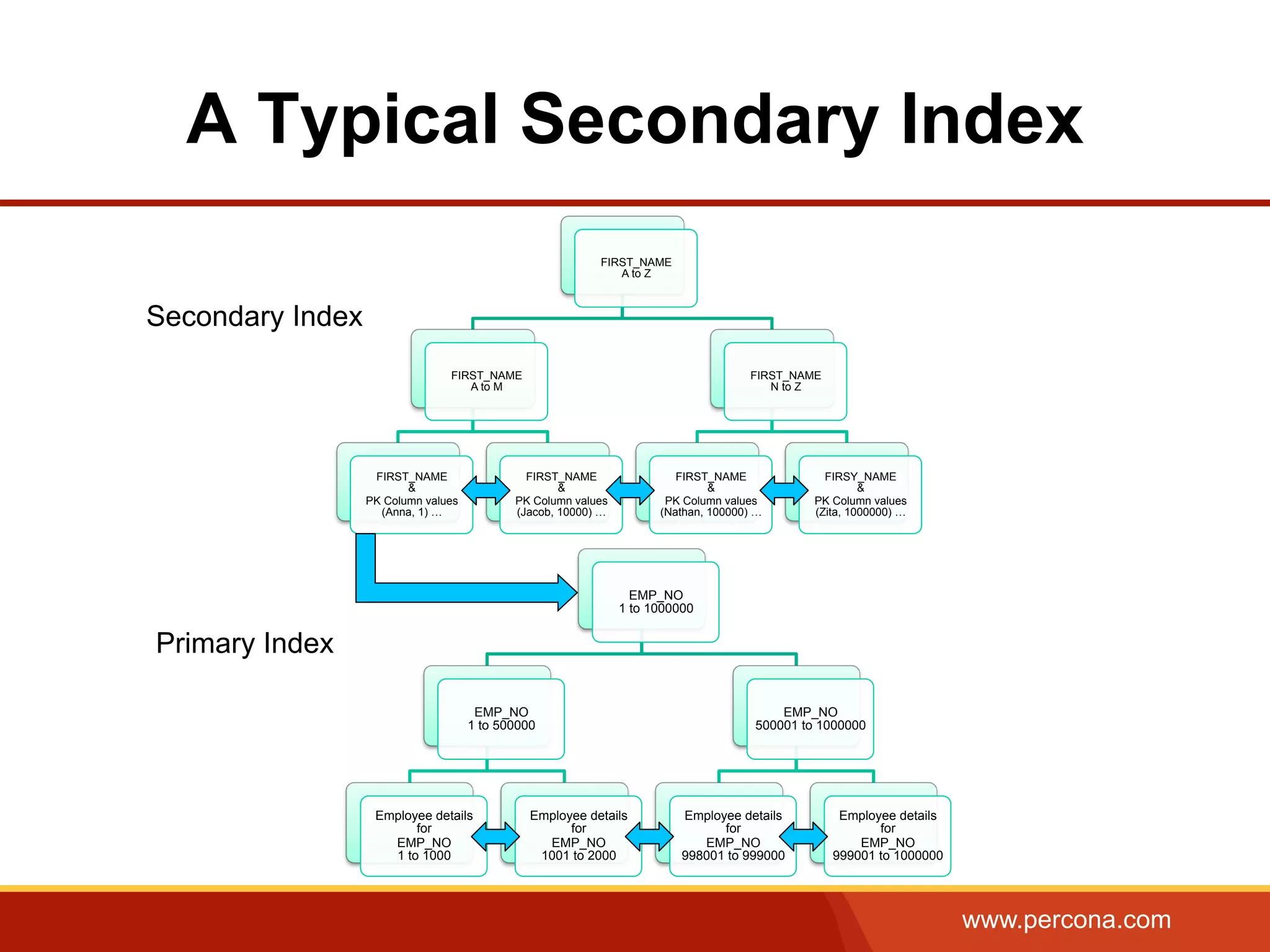























The document provides an overview of b+tree indexes, focusing on their structure, advantages, and cost estimations related to database operations in InnoDB. Key topics include primary and secondary indexes, composite indexes, and optimizations for improved query performance. The content emphasizes efficient data retrieval and performance trade-offs associated with indexing in database management systems.




![[2019] 200만 동접 게임을 위한 MySQL 샤딩](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201923-200122092657-thumbnail.jpg?width=640&height=640&fit=bounds)











































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















