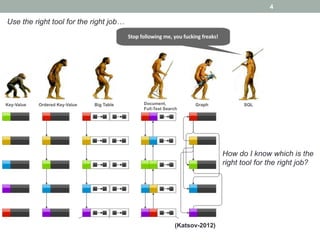
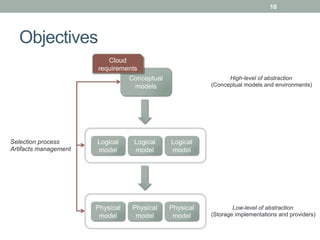
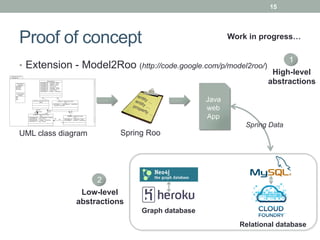
This document discusses model-driven approaches for cloud data storage. It outlines objectives to 1) characterize cloud data storage requirements using conceptual models, 2) select appropriate cloud data storage implementations and providers based on requirements, and 3) manage artifacts for working with different storage solutions. Existing solutions are limited and the proposed approach uses model-driven engineering with multiple levels of modeling and transformation to map between requirements and storage solutions.























![[2015/2016] Modern development paradigms](https://cdn.slidesharecdn.com/ss_thumbnails/08moderndevelopment-151209170018-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![The road ahead for architectural languages [ACVI 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ivanomalavoltaacvi2016-160405090741-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2015/2016] AADL (Architecture Analysis and Design Language)](https://cdn.slidesharecdn.com/ss_thumbnails/07saaadl-151204104852-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






![[2017/2018] AADL - Architecture Analysis and Design Language](https://cdn.slidesharecdn.com/ss_thumbnails/ivano04saaadl-171122165132-thumbnail.jpg?width=640&height=640&fit=bounds)



















































