




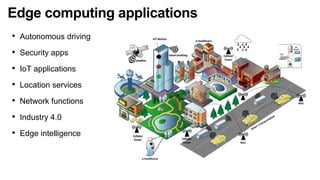




![CLOUDLET/FoG/Edge/CLOUD-To-IOT/CONTINUUM Computing
Inter Micro DCs latency
[50ms-100ms]
Edge
Frontier
Edge
Frontier
Extreme Edge
Frontier
Domestic network
Enterprise network
Wired link
Wireless link
Cloud Latency
> 100ms
Cloud Computing
Micro/Nano DC
Intra DC latency
< 10ms
Hybrid network](https://image.slidesharecdn.com/sss-nov2022-v2-221118213918-4358d6da/85/R-evolution-of-the-computing-continuum-A-few-challenges-10-320.jpg)

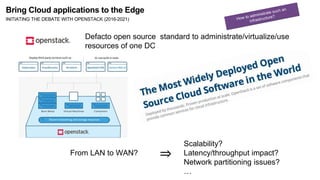
![Inter Micro DCs latency
[50ms-100ms]
Edge
Frontier
Edge
Frontier
Extreme Edge
Frontier
Domestic network
Enterprise network
Wired link
Wireless link
Cloud Latency
> 100ms
Cloud Computing
Micro/Nano DC
Intra DC latency
< 10ms
Hybrid network
WANWIDE
Collaborative?
Bring Cloud applications to the Edge
INITIATING THE DEBATE WITH OPENSTACK (2016-2021)](https://image.slidesharecdn.com/sss-nov2022-v2-221118213918-4358d6da/85/R-evolution-of-the-computing-continuum-A-few-challenges-13-320.jpg)
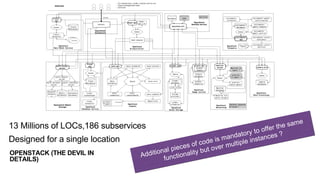
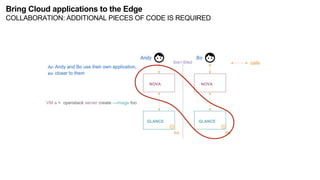
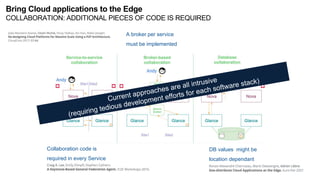
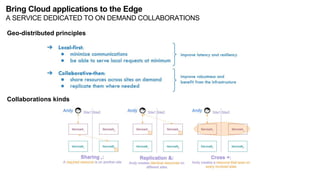
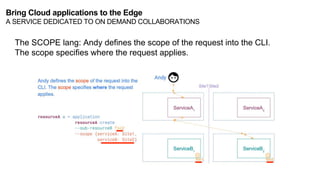
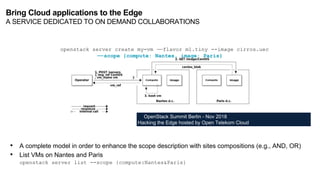
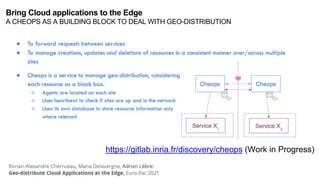
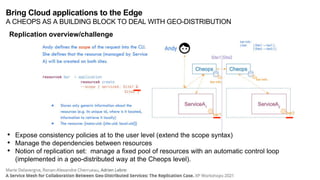
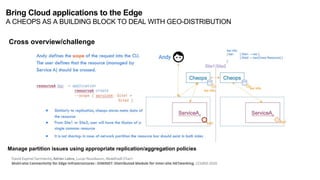



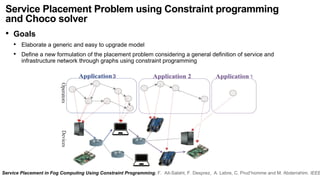
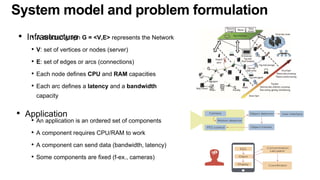
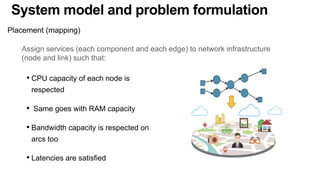

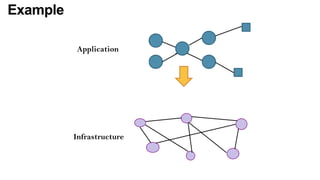
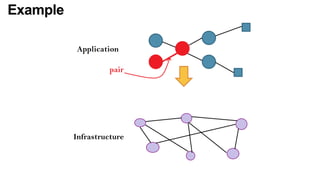
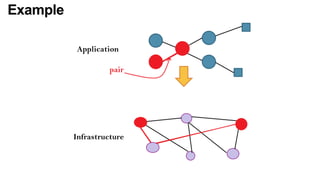






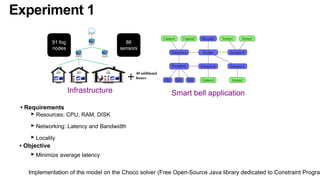
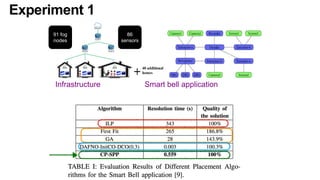
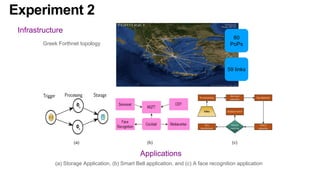
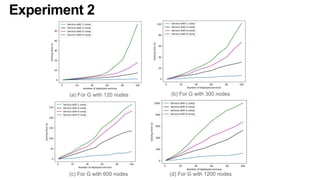


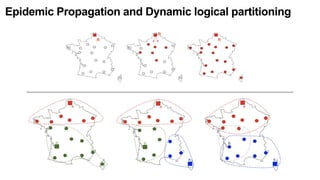


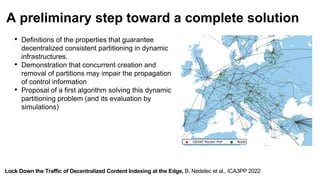


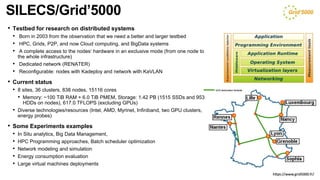
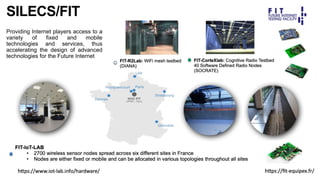

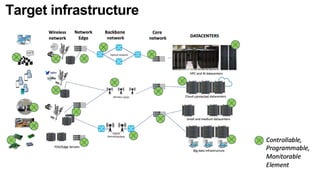

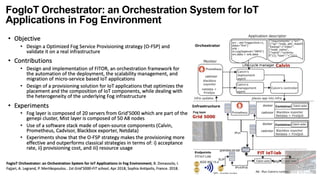
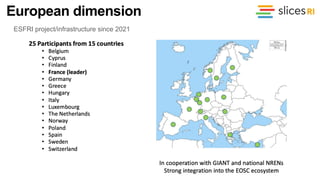




The document discusses the evolution and challenges of the computing continuum, emphasizing the need for a paradigm that minimizes latency and enhances data processing close to its source, particularly in edge computing. It outlines various distributed computing models, such as cloud, fog, and edge computing, while identifying key research issues like service placement and content indexing within dynamic environments. The document highlights the importance of experimental infrastructures for research in distributed systems and the need for collaborative approaches to address geo-distributed constraints.







































































