Download as PDF, PPTX










![Hype Cycle 2009
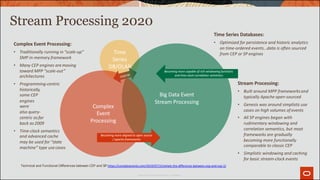
Complex Event Processing:
• CEP is a kind of computing in which incoming data about
events is distilled into more useful, higher level event data
that provides insight into what is happening. […] CEP is
used for highly demanding, continuous-intelligence
applications that enhance situation awareness and
support real-time decisions. Gartner
20 Years Too Early?
• CEP dates back to the 1990’s (history of CEP engines)
• CEP came before “Event Stream Processing” andgenerally
has covered more complex use cases (eg; handling of out-
of-order events and more complicated correlation
semantics) ( what’s the difference, 2019 and mythbuster
CEP vs ESP, 2008)
• Largely overtaken by Big Data stream processing
technologies that are open-source, massively-parallel,and
widely available as cloud-native
2009!
Copyright © 2020 Oracle and/or its affiliates.](https://image.slidesharecdn.com/dataengineerpatternsarchitecture-200616130532/85/Data-Engineer-Patterns-Architecture-The-future-Deep-dive-into-Microservices-Patterns-with-Stream-Process-22-320.jpg)
![Stream Processing/CEP for Event Driven Architectures
There has been a widespread
awakening to the benefits of Event
Drive Architecture (EDA) for
increasing the scalability and agility of
business systems. […] Stream
analytics is based on the mathematics
of complex-event processing (CEP).
CEP is a computing technique in
which incoming data about what is
happening (event data) is processed
as it arrives (data in motion or
recently in motion) to generate
higher level, more useful, summary
information (complex events).
W. Roy Schulte (of Gartner), March 2020:
EDA is Suddenly Popular Will Stream Analytics be Next?
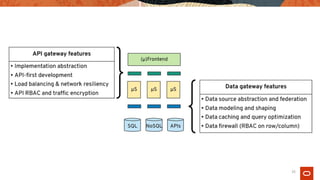
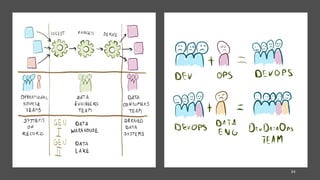
Event Stream Analytics (& CEP)
Data & Microservice Events
Event/Data
Pipelines
Time-Series
Analysis
Geospatial
Analysis
Real-time
AI/ML
Continious
ETL
Use Cases:](https://image.slidesharecdn.com/dataengineerpatternsarchitecture-200616130532/85/Data-Engineer-Patterns-Architecture-The-future-Deep-dive-into-Microservices-Patterns-with-Stream-Process-24-320.jpg)







![Spark, Flink or KSQL
Copyright © 2019 Oracle and/or its affiliates.
[best] ˜œ›™[worst]
Spark
Streaming
Apache
Flink / SQL
Confluent
KSQL
User Experience
Low Code Development (with built-in patterns/accelerators) ™
Interactive/Live Edits (browser based, view changes immediately) ™ ˜
Built-in Live Dashboards (event-driven charts/graphs) ™
Core Streaming Semantics
What is Being Computed (transforms, joins, flatten, statefulness etc) › œ œ
Time Windows(global, fixed, sliding, tumbling, custom etc) › ˜ ˜
When in Processing Time (triggers – event, time, count, timers, etc) œ
How do Refinements Relate (discarding, accumulating, retracting) › œ
Analytics
Robust CEP Capabilities (complex event correlations, native time clock) ™
Geo-Fencing & Spatial (lat/long, built in maps, custom map tiles, etc) ™ ™ ™
Machine Learning (native scala, PMML, python support etc) œ œ
Time Series Analysis (built-in interval patterns, thresholding etc)
Other Features
Backpressure (dynamic ingest per pipeline) Custom Custom Custom
State Management (automation across streams & native cache) N/A RocksDB RocksDB
Data Consistency (OLTP Change Events, Inserts/Updates/Deletes) Custom Custom Custom
GoldenGate Stream Type (aware of SCN/CSN, transactions, order, etc) Custom Custom Custom](https://image.slidesharecdn.com/dataengineerpatternsarchitecture-200616130532/85/Data-Engineer-Patterns-Architecture-The-future-Deep-dive-into-Microservices-Patterns-with-Stream-Process-37-320.jpg)
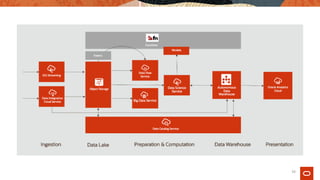




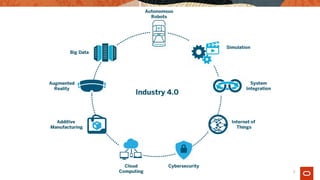
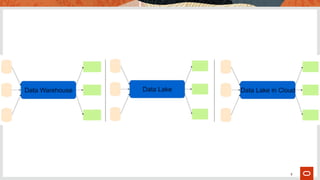
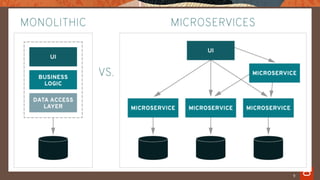
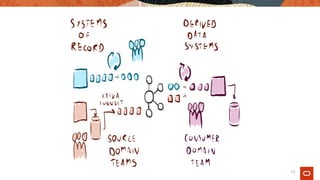
The document explores the evolution of data architecture, emphasizing the transition from batch-centric models to event-driven, microservices-based systems as seen in Industry 4.0. It discusses key concepts such as data mesh, the benefits of microservices and service mesh architectures, and the importance of real-time data processing. Additionally, it critiques traditional ETL practices and highlights the need for modern data approaches to support digital transformation.























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)











































