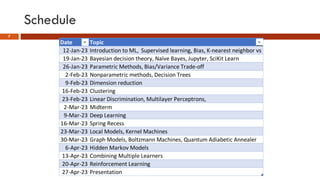
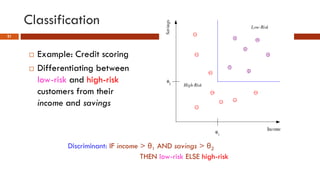
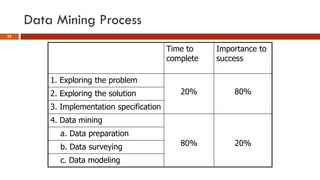
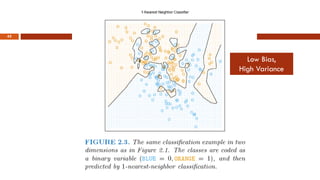
This document provides an overview of machine learning concepts that will be covered in the DSCI 552 course. It introduces key machine learning tasks like classification, regression, and clustering. It discusses the machine learning process and importance of inductive bias. Example applications in areas like credit scoring, face recognition, and customer segmentation are provided. The reading schedule and grading policy are also outlined.






![What is Machine Learning
8
Machine learning is the science (and art) of programming computers so they
can learn from data
Here is a slightly more general definition:
[Machine learning is the] field of study that gives computers the ability to learn
without being explicitly programmed.
Arthur Samuel, 1959
And a more engineering-oriented one:
A computer program is said to learn from experience E with respect to some task T
and some performance measure P, if its performance on T, as measured by P,
improves with experience E.
Tom Mitchell, 1997](https://image.slidesharecdn.com/dsci552lecture12023-01-12-240312035137-7b56ccb5/85/DSCI-552-machine-learning-for-data-science-8-320.jpg)









































































![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Danilo Djukanovic - From Vibes to KPIs: Turning Culture Into ...](https://cdn.slidesharecdn.com/ss_thumbnails/inqestws5wf0cik2glgv-3-danilo-djukanovic-from-vibes-to-kpis-presentation-260114111931-dacff81f-thumbnail.jpg?width=640&height=640&fit=bounds)
