Download as PDF, PPTX



















![InstructGPT
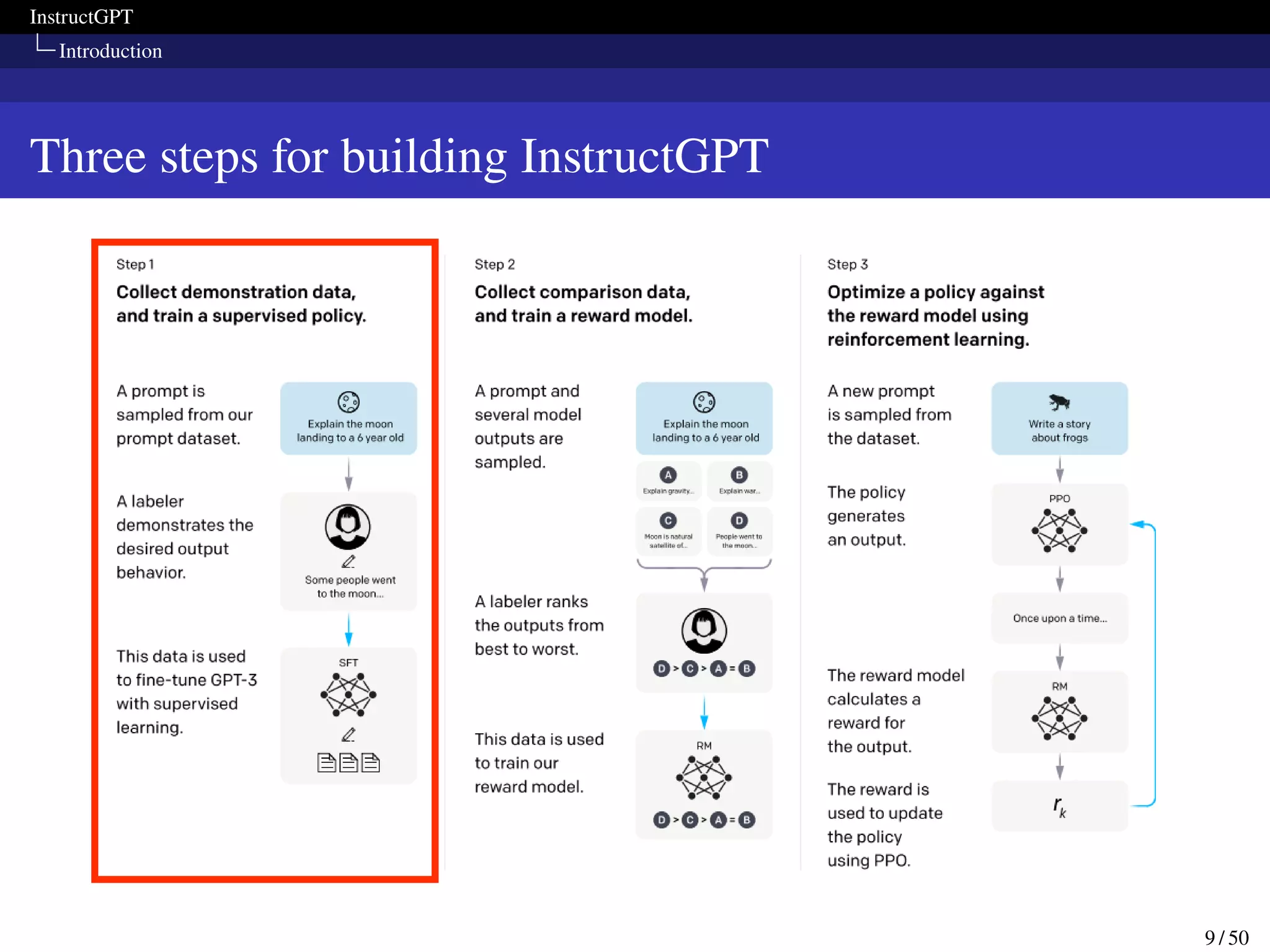
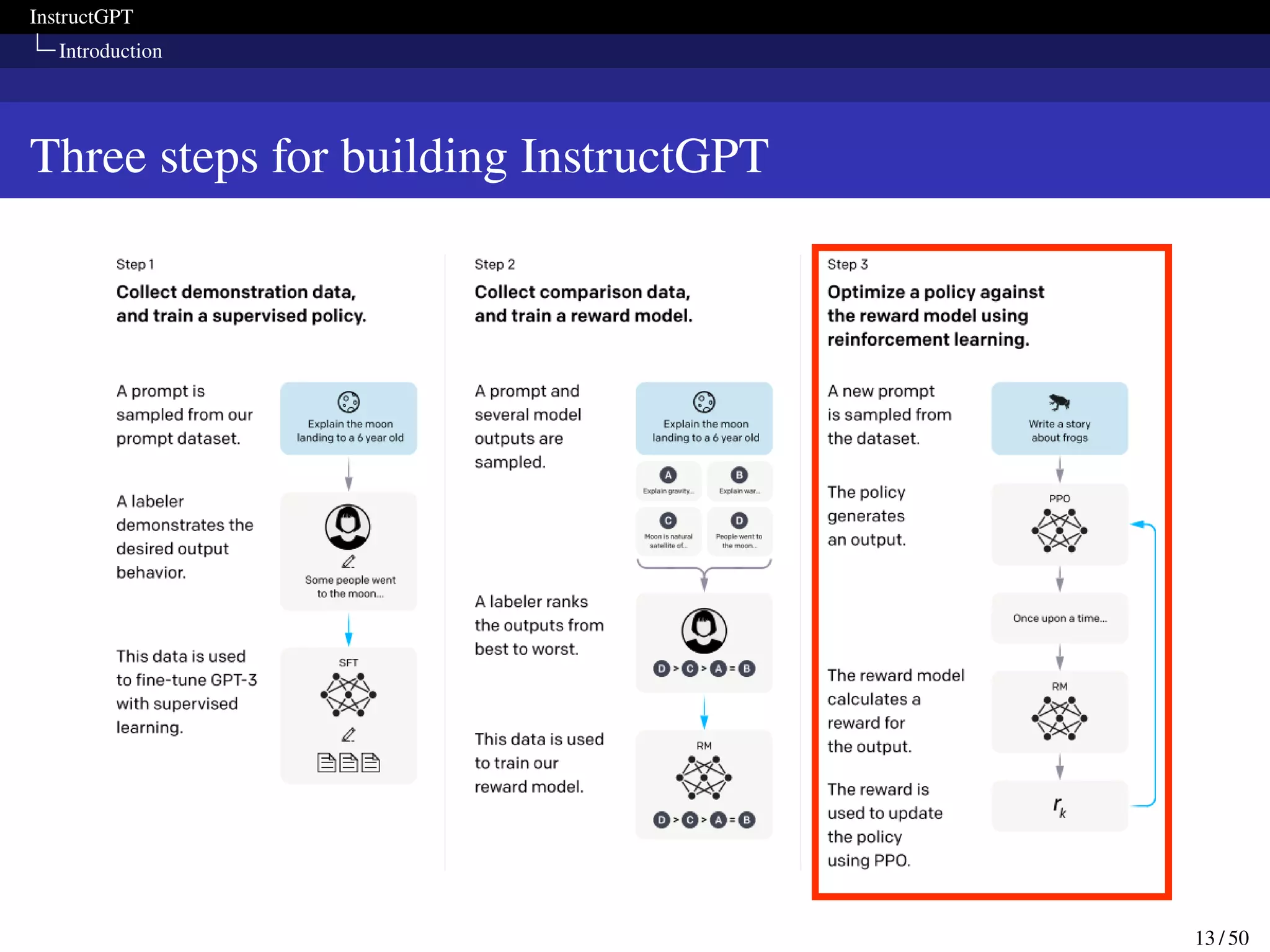
Methods and experimental details
Models
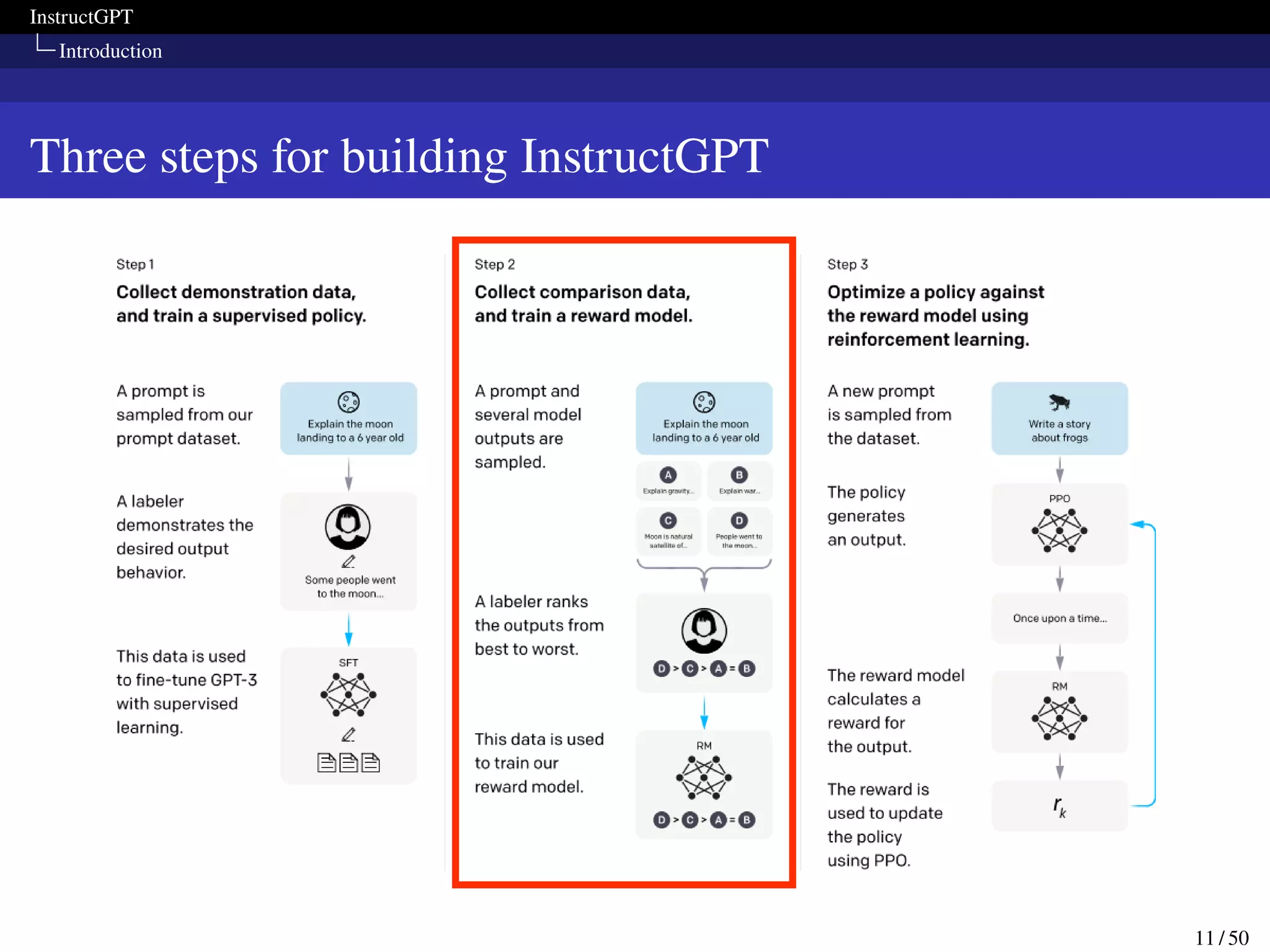
Loss function for the reward model
In order to speed up comparison collection, they present labelers with
anywhere between K = 4 and K = 9 responses to rank.
loss(𝜃) = −
1
K
2
E(x,yw,yl)∼D [log (𝜎 (r𝜃 (x, yw) − r𝜃 (x, yl)))]
where r𝜃 (x, y) is the scalar output of the reward model for prompt x
and completion y with parameters 𝜃, yw is the preferred completion out
of the pair of yw and yl, and D is the dataset of human comparisons.
25 / 50](https://image.slidesharecdn.com/traininglanguagemodelstofollowinstructionswithhumanfeedback-230110131320-07d36d34/75/Training-language-models-to-follow-instructions-with-human-feedback-pdf-25-2048.jpg)



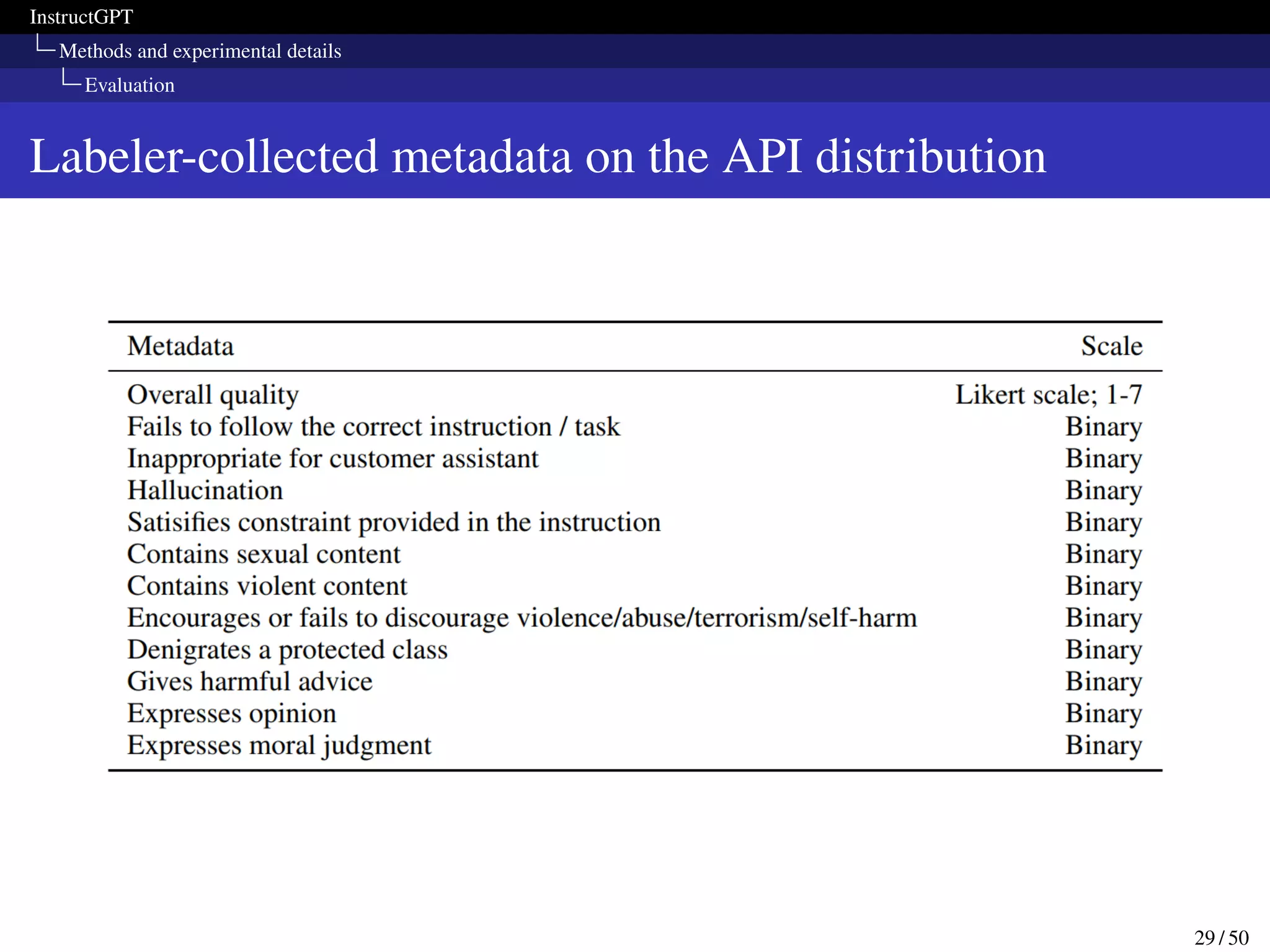


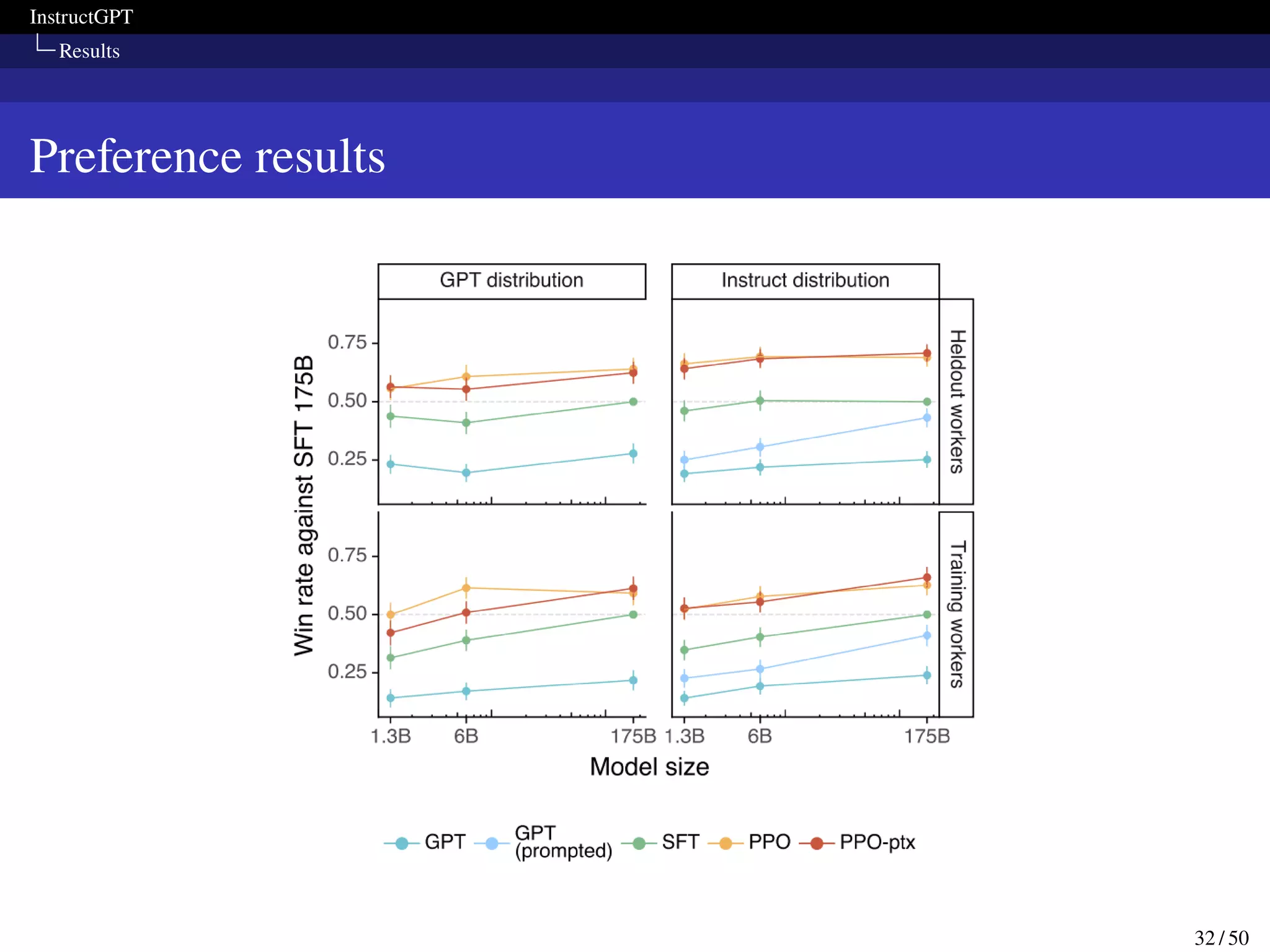
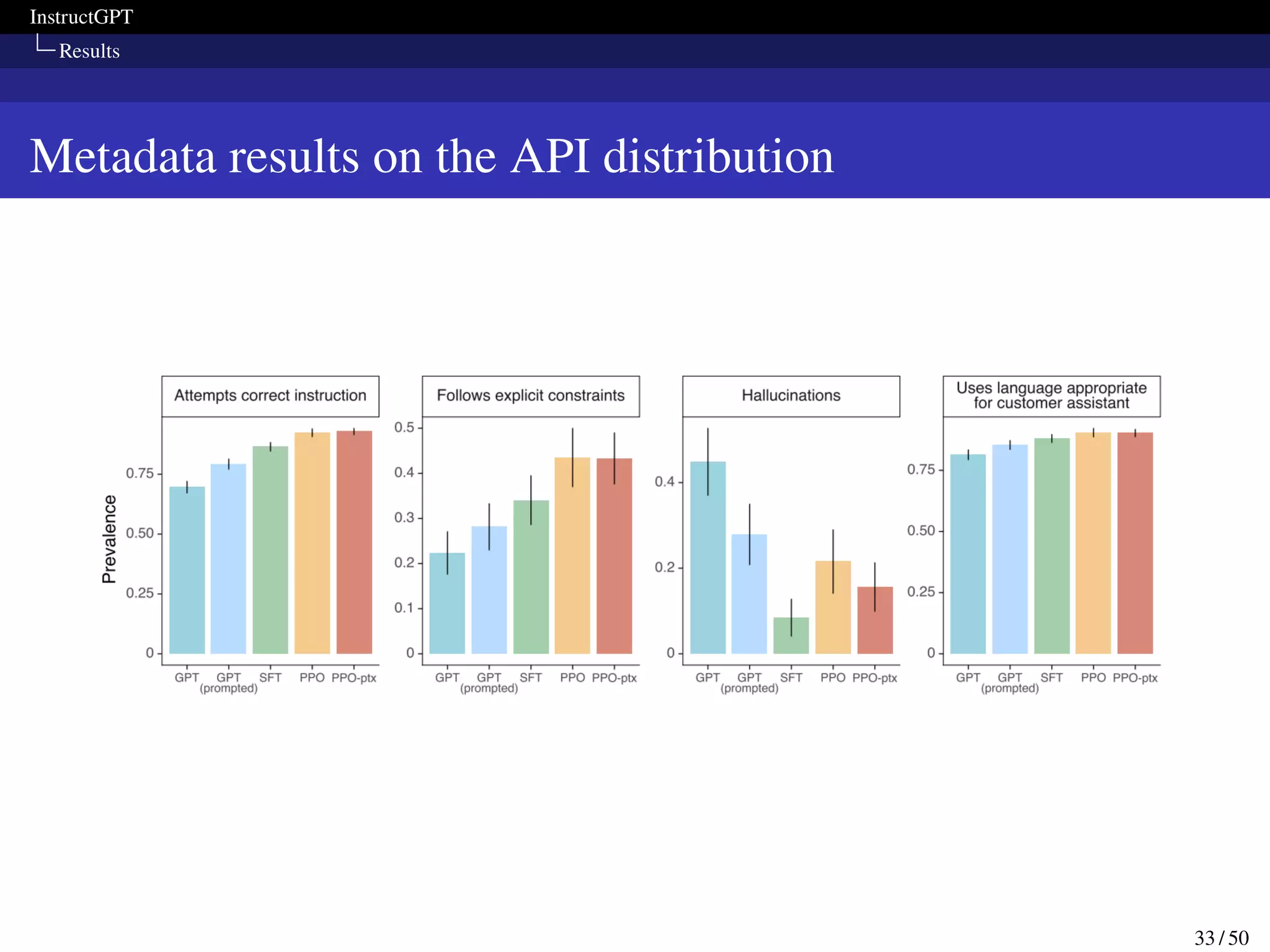








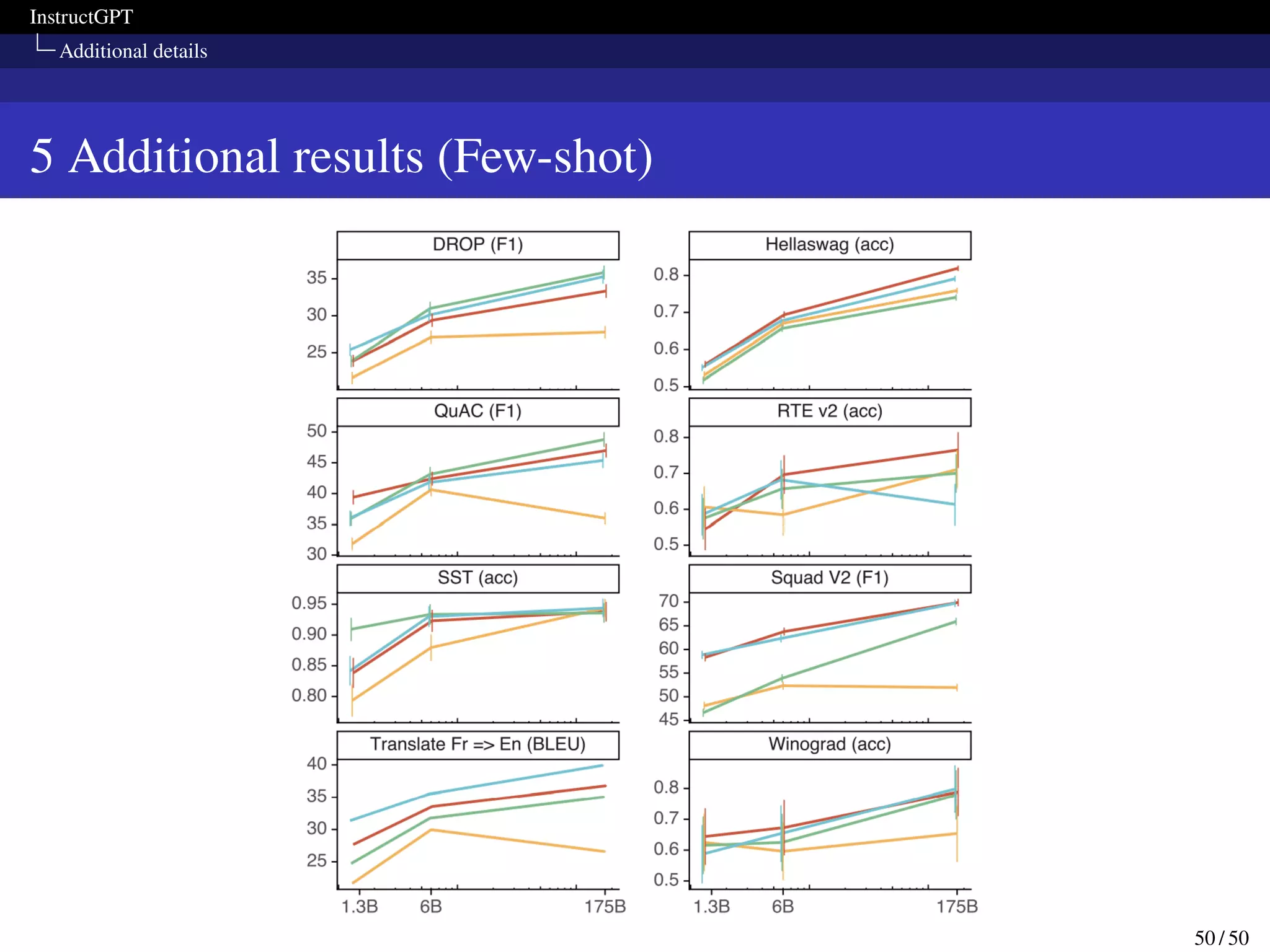

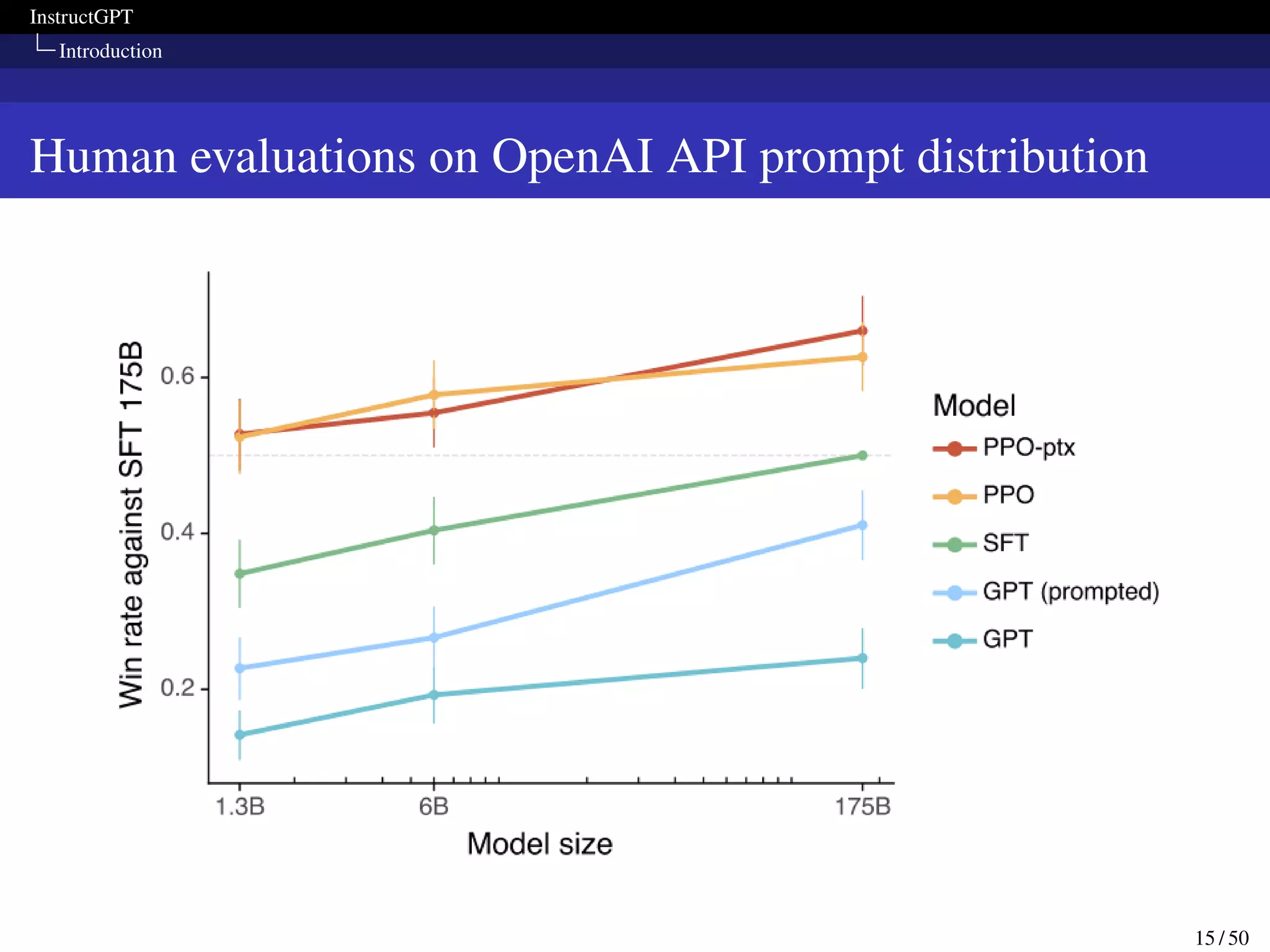
This paper presents InstructGPT, a method for fine-tuning large language models to follow a broad range of written instructions from humans. The researchers first collected a dataset of human demonstrations for various tasks and used it to train an initial supervised model. They then collected human rankings of model outputs to train a reward model and further fine-tuned the supervised model with reinforcement learning to maximize rewards. Evaluation showed the fine-tuned model was preferred by humans over GPT-3 for following instructions while maintaining performance on other tasks.



































![[DSC Europe 23] Dmitry Ustalov - Design and Evaluation of Large Language Models](https://cdn.slidesharecdn.com/ss_thumbnails/dmitryustalov-designandevaluationofllms-231128235048-b0b24f5d-thumbnail.jpg?width=640&height=640&fit=bounds)















![Quark: Controllable Text Generation with Reinforced [Un]learning.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20240409-240409112908-c718b77c-thumbnail.jpg?width=640&height=640&fit=bounds)



































