











![Benefits of Open Metadata
• Driving users to your content
• Stimulating collaboration
• Enabling new scholarship that can only be
done with open data
• Allowing creation of new services for
discovery
• "increas[ing] relevance to digital society"
(Oomen and Baltussen)](https://image.slidesharecdn.com/uncscholcommworkinggroup-130326140511-phpapp02/75/Metadata-Ownership-Metadata-Rights-13-2048.jpg)





![Case Law: Claims of Meta[data]
Rights Violations
Trademark violation claims in meta tags (HTML)
• PLAYBOY ENTERPRISES INC v. WELLES (279
F3d 796 (2002))
"Nominative use"
Copyright violation claims in page number use
• Matthew Bender & Co Inc v. West Publishing
Co (158 F. 3d 674 (1998))](https://image.slidesharecdn.com/uncscholcommworkinggroup-130326140511-phpapp02/75/Metadata-Ownership-Metadata-Rights-19-2048.jpg)









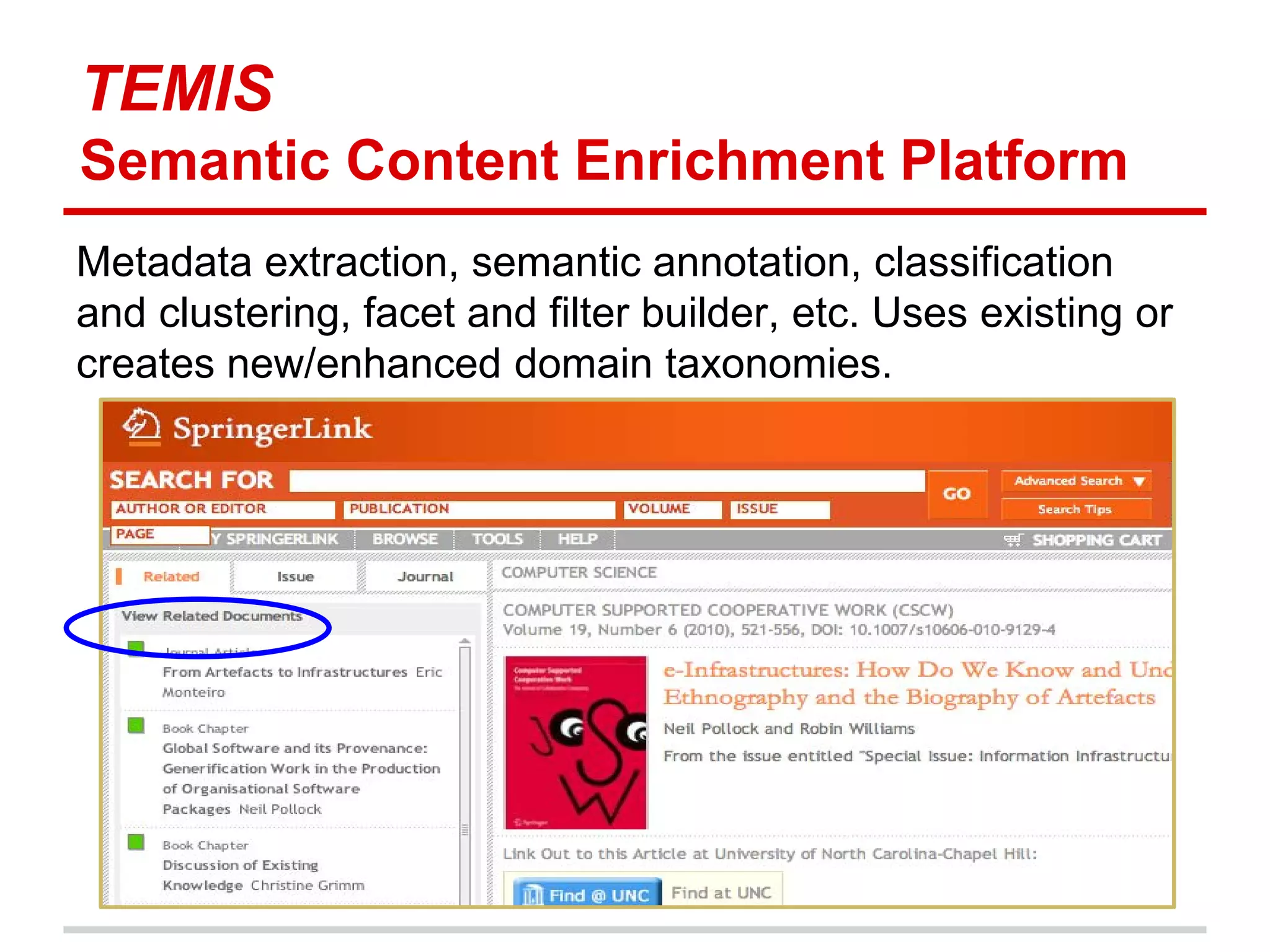











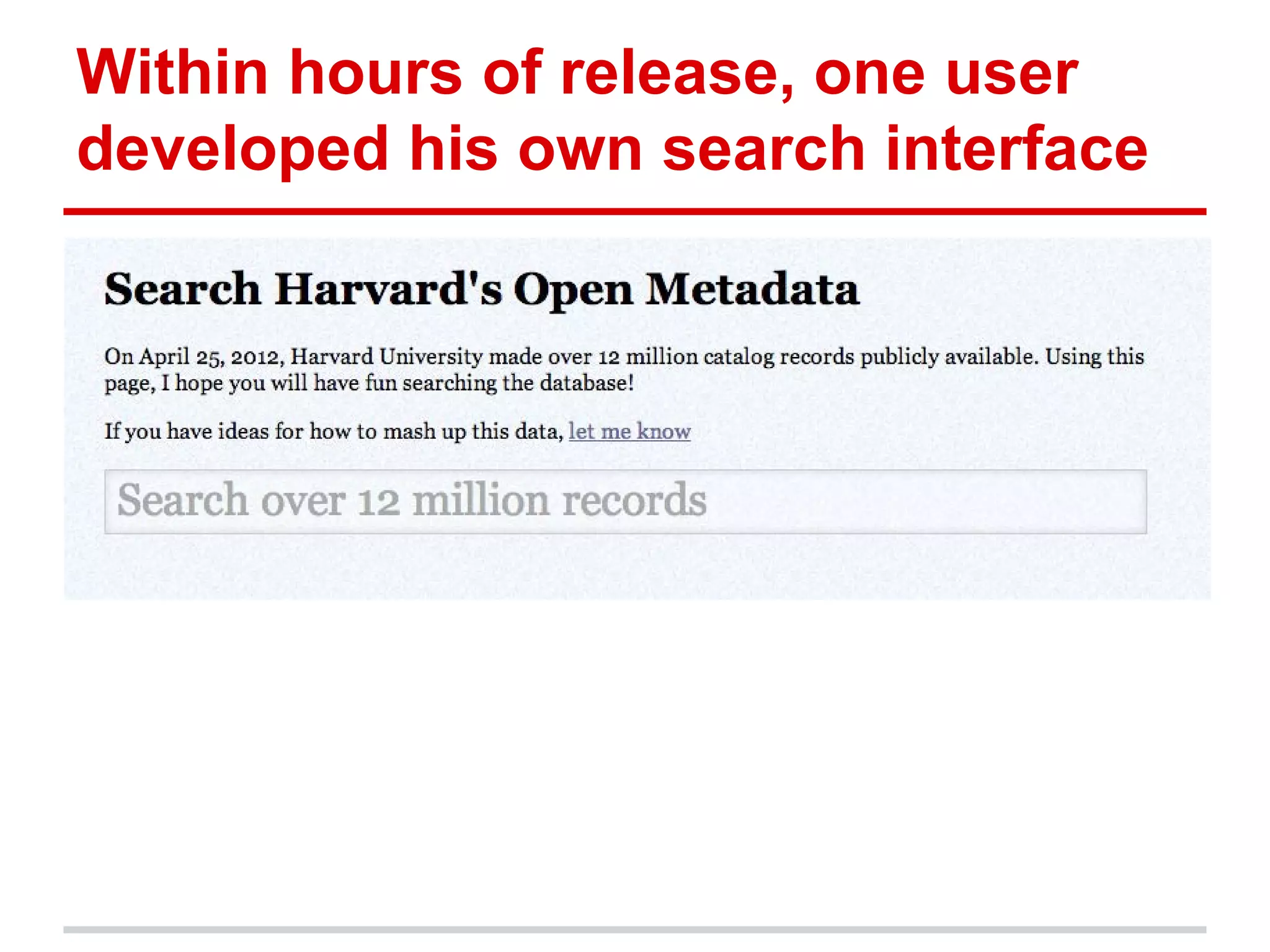
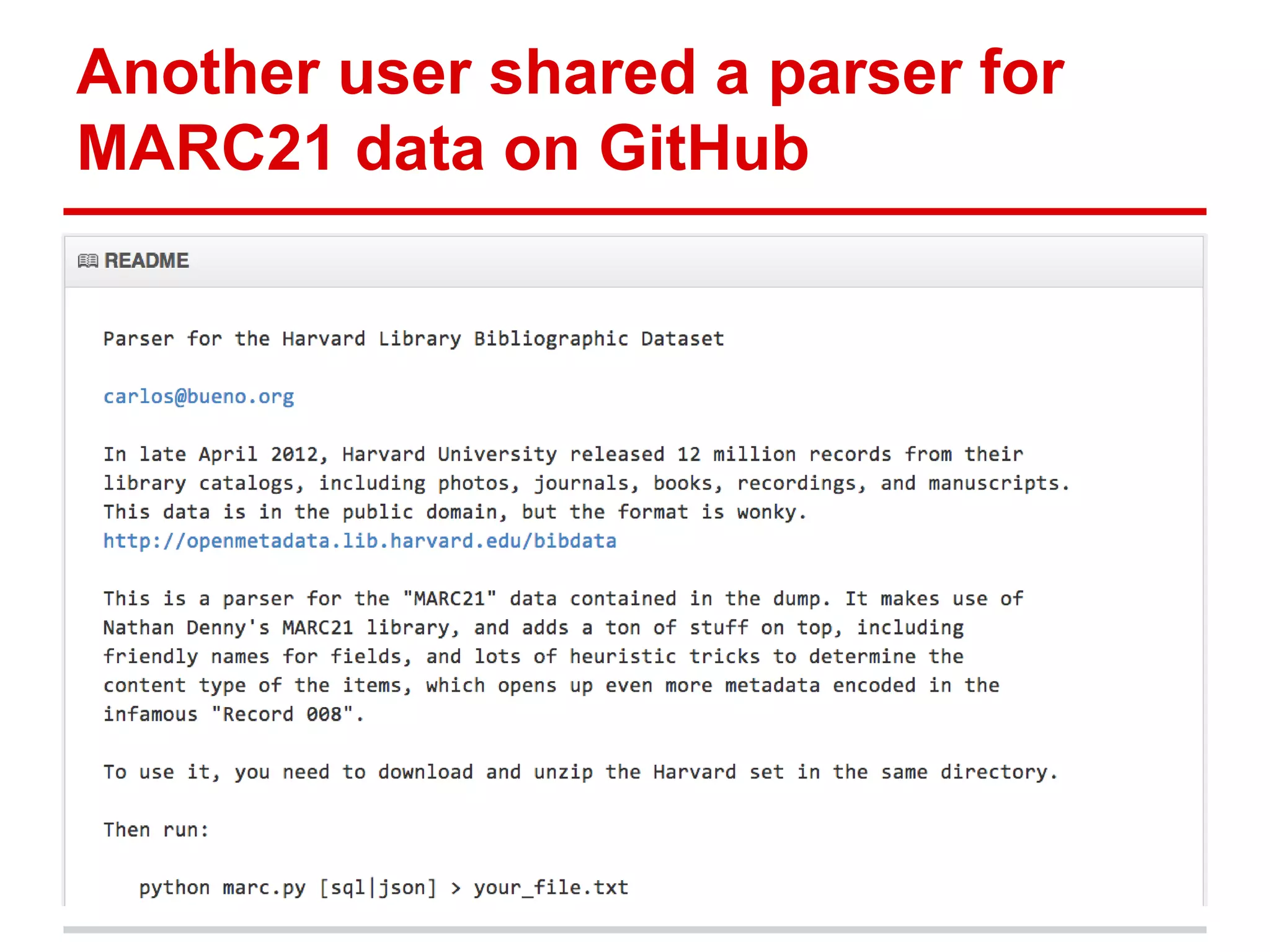
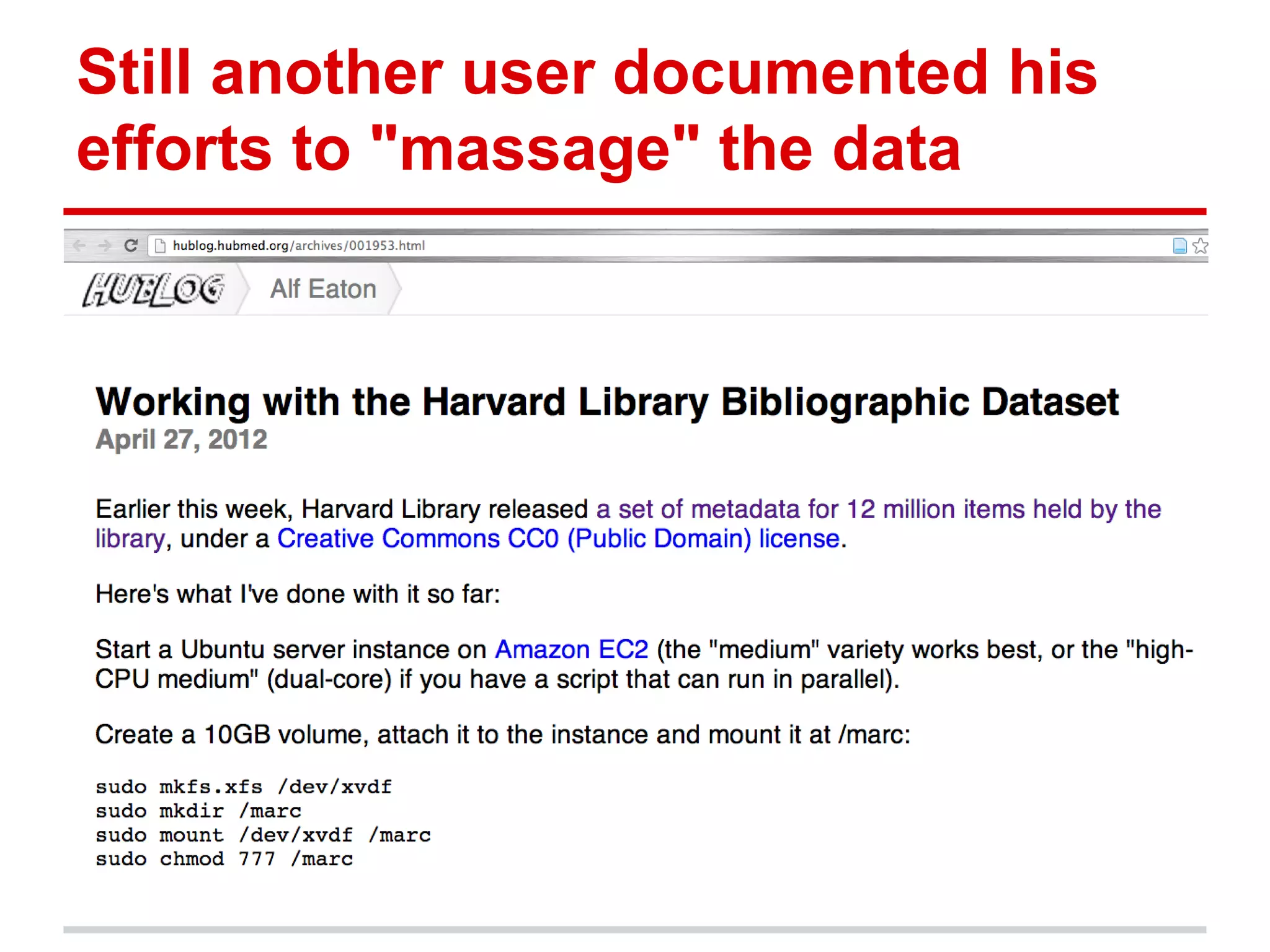







The document discusses metadata ownership and rights, exploring when metadata can be viewed as intellectual property and the implications of copyright in relation to metadata. It includes various case studies, such as that of Duke University Press and Open Bibliographic Data initiatives, highlighting issues of attribution, copyrightability, and the benefits and drawbacks of open metadata. Overall, it emphasizes the necessity of understanding legal rights surrounding metadata to promote innovation and effective use in scholarly communications.




































