Downloaded 51 times




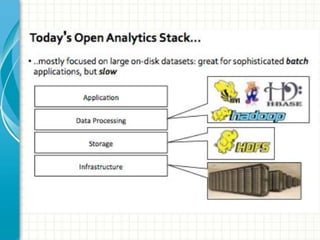
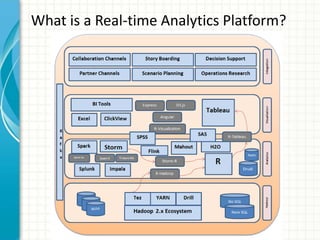


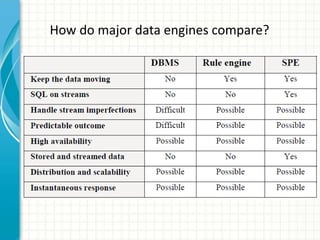
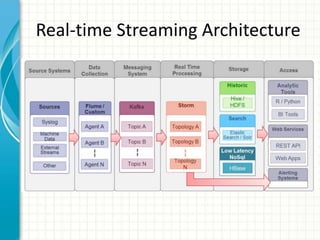
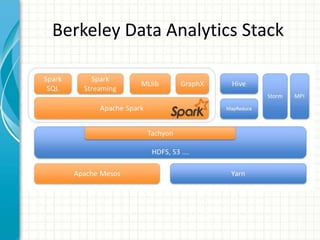


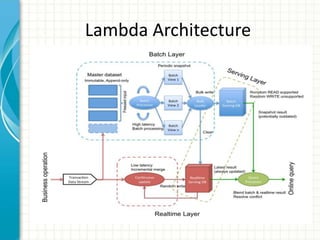
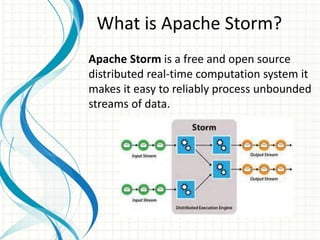

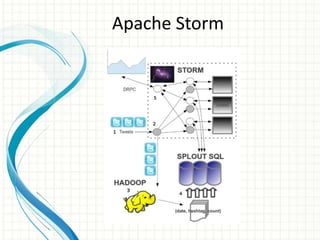
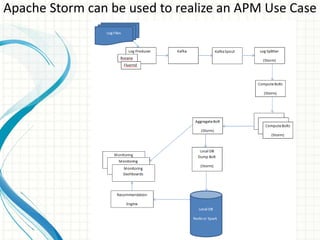

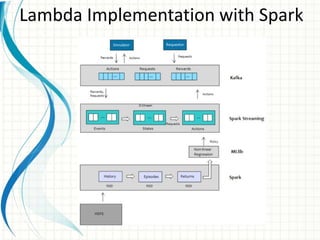
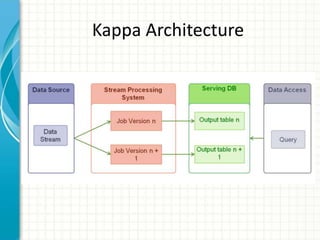
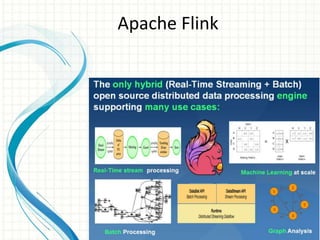
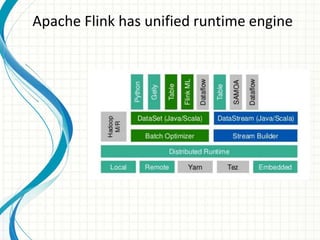




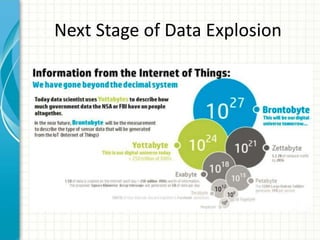




This document provides an introduction to polyglot processing using various big data frameworks. It discusses the lambda and kappa architectures for handling batch, micro-batch, and streaming workloads. The document then demonstrates Apache Spark, Storm, Kafka and Redis for stream processing and compares these tools to Flink. It concludes that polyglot processing allows for any data type or workload to be handled and that frameworks like Spark, Storm and Flink each have strengths for distributed, real-time computation.

































































