Downloaded 133 times













![TAG clouds from Technorati Technorati: blog aggregator We can get tag clouds from Technoraty through: http://api.technorati.com/blogposttags?key= [apikey] &url= [blog URL]](https://image.slidesharecdn.com/20080602eswc08-1212762297005434-9/85/Metadata-first-ontologies-second-29-320.jpg)

![Tagged URL at Technorati All <tag> elements are downloaded To get the “title” http://api.technorati.com/bloginfo?key= [apikey] &url= [blog url] And<name> is recovered](https://image.slidesharecdn.com/20080602eswc08-1212762297005434-9/85/Metadata-first-ontologies-second-31-320.jpg)
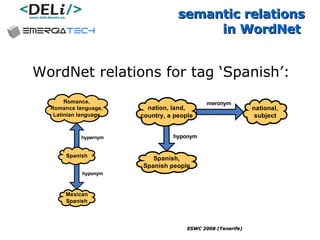





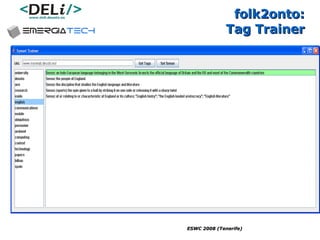
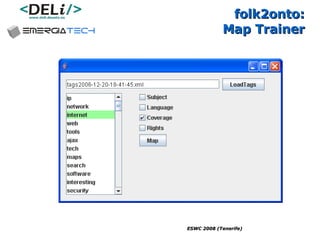



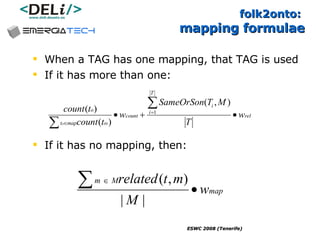

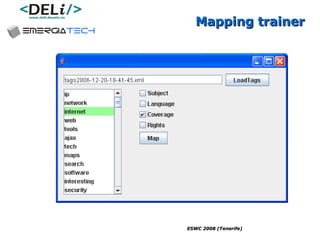

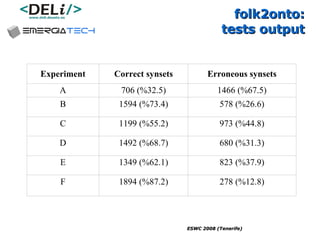
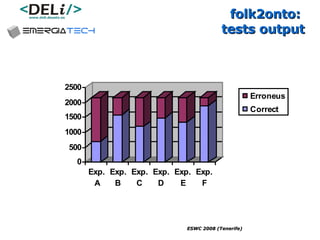



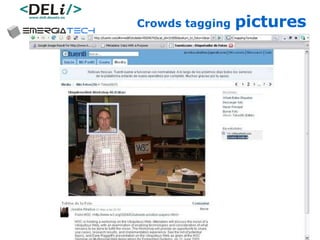
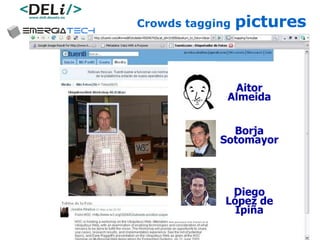
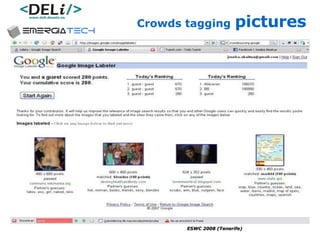
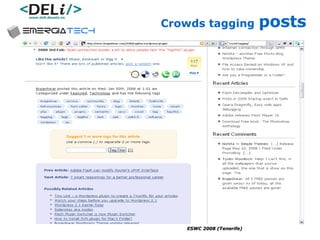
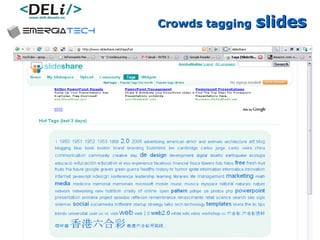
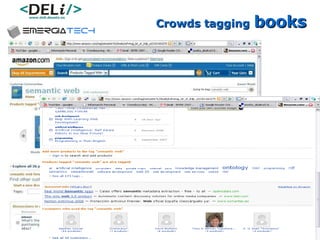
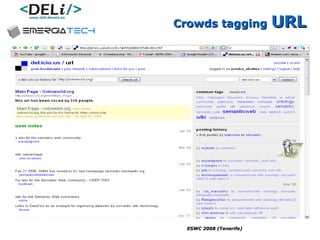
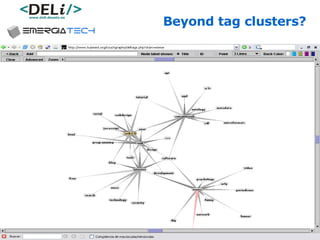
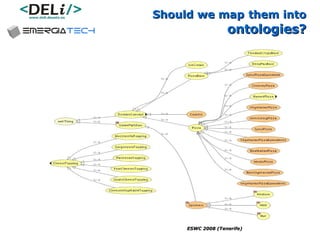
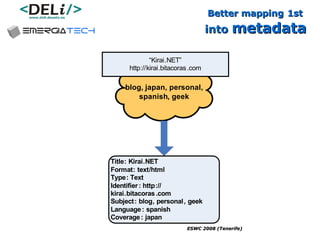
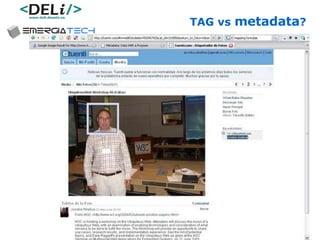
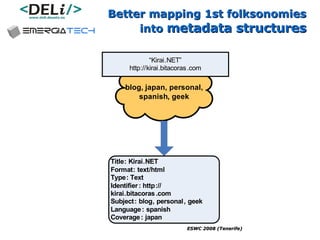
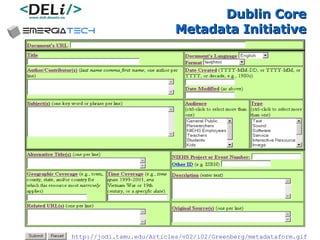
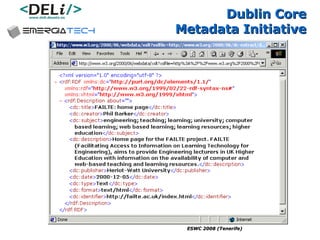
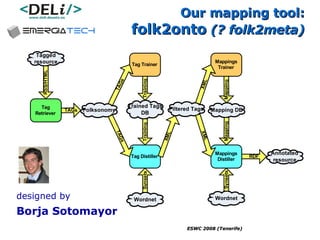
The document discusses a project called CollOnBus that aims to extract knowledge from social tagging data on the web. It presents an approach called "metadata first, ontologies second" which involves mapping tags to Dublin Core metadata structures before converting them to ontologies. The document also describes tools developed as part of CollOnBus called folk2onto and Tag Distiller that are used to filter tags, map them to senses, and generate XML files representing the mapped tags and their relationships.




































































![A course [largely on bibliographic] information managemet](https://cdn.slidesharecdn.com/ss_thumbnails/dec18informationmanagemet-141218030321-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)






























