Downloaded 54 times





















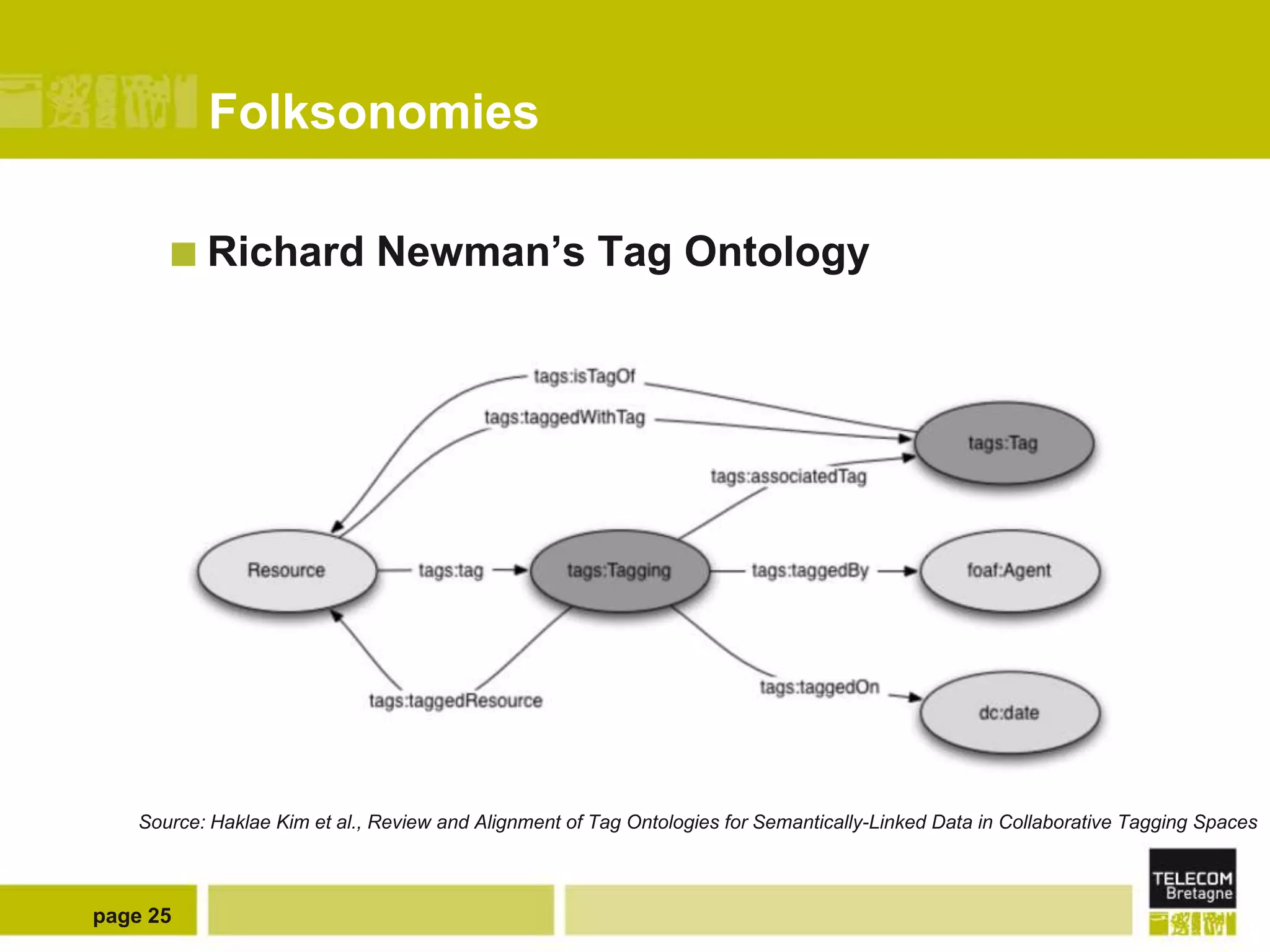




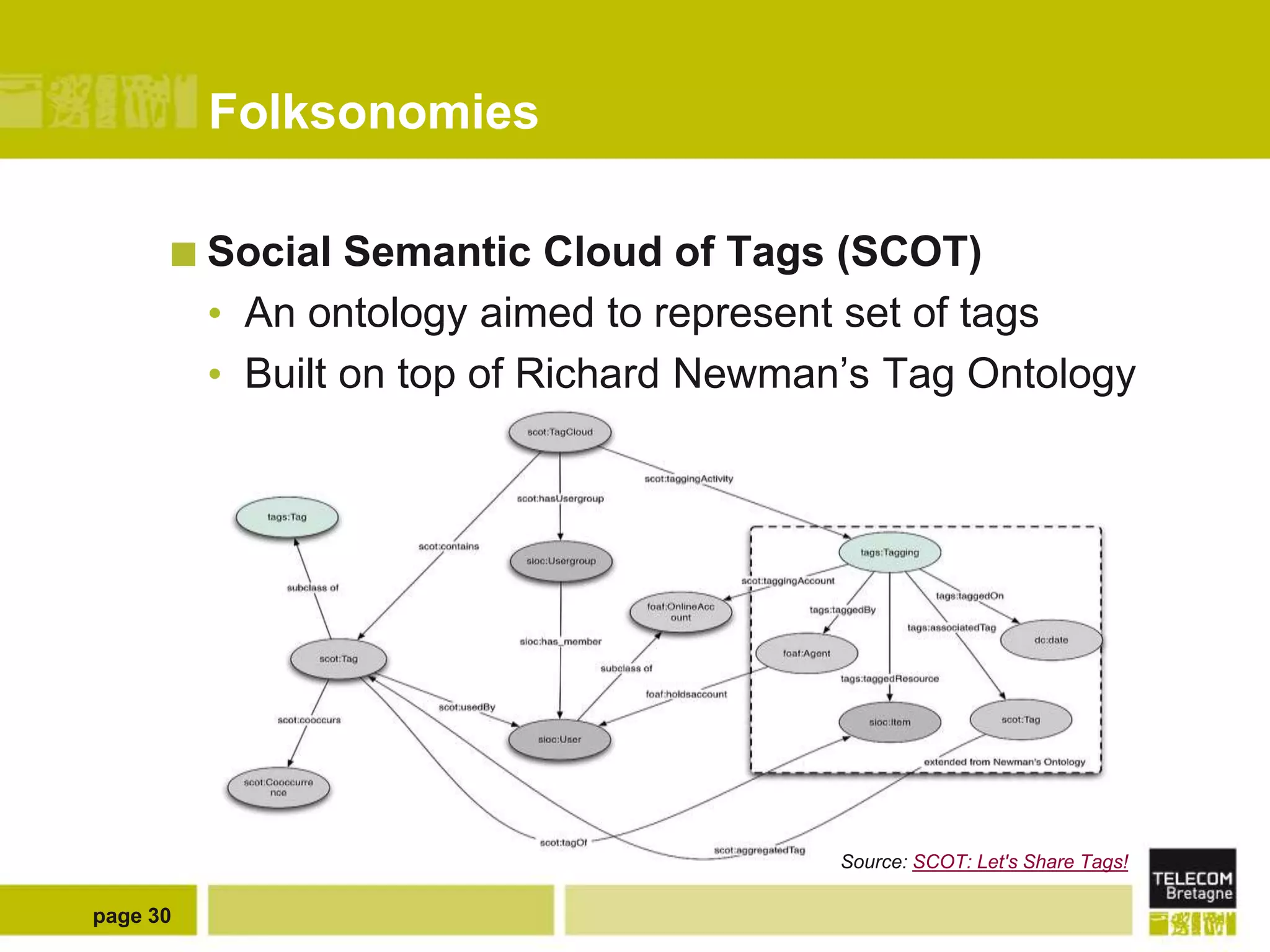






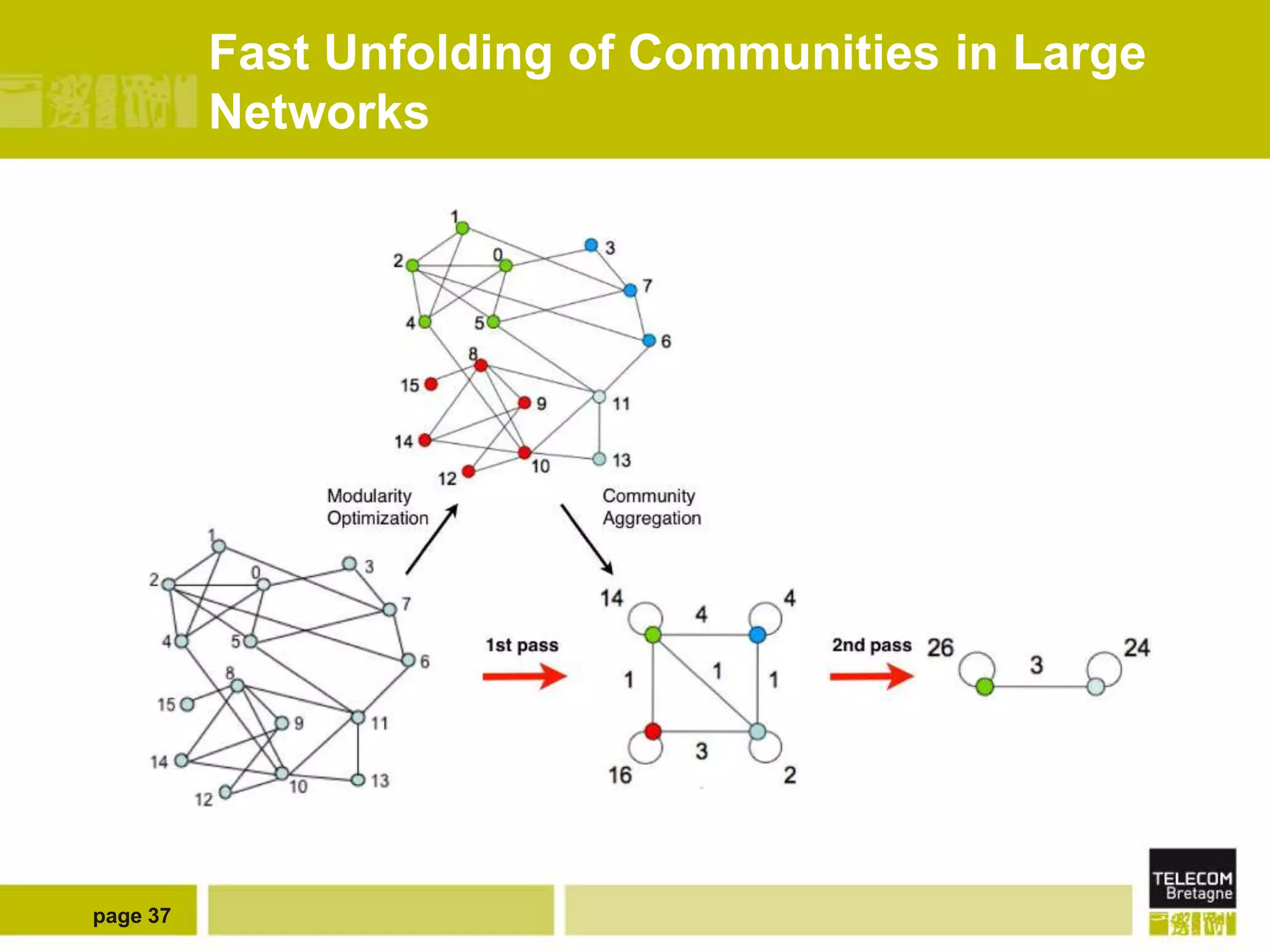






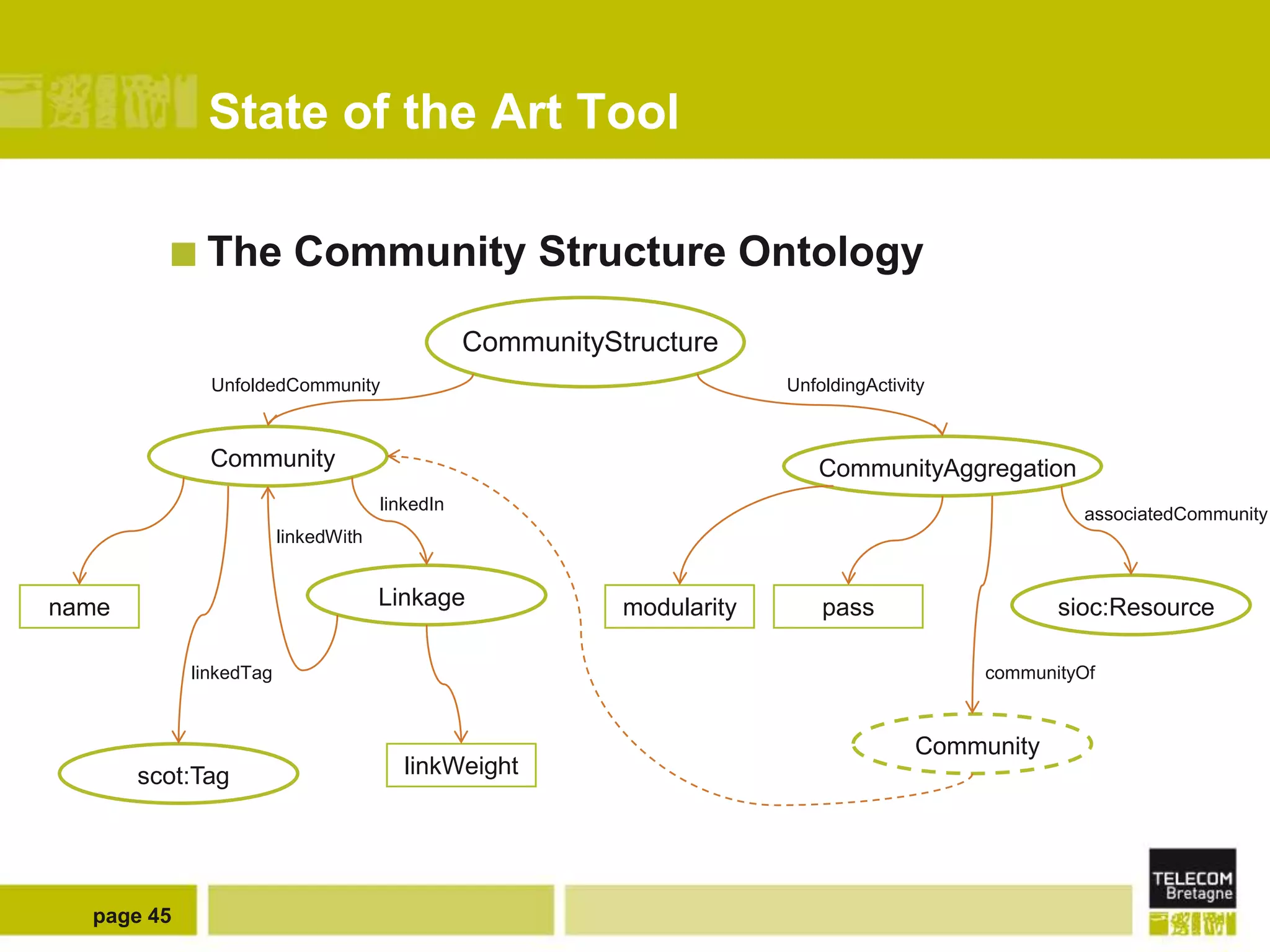



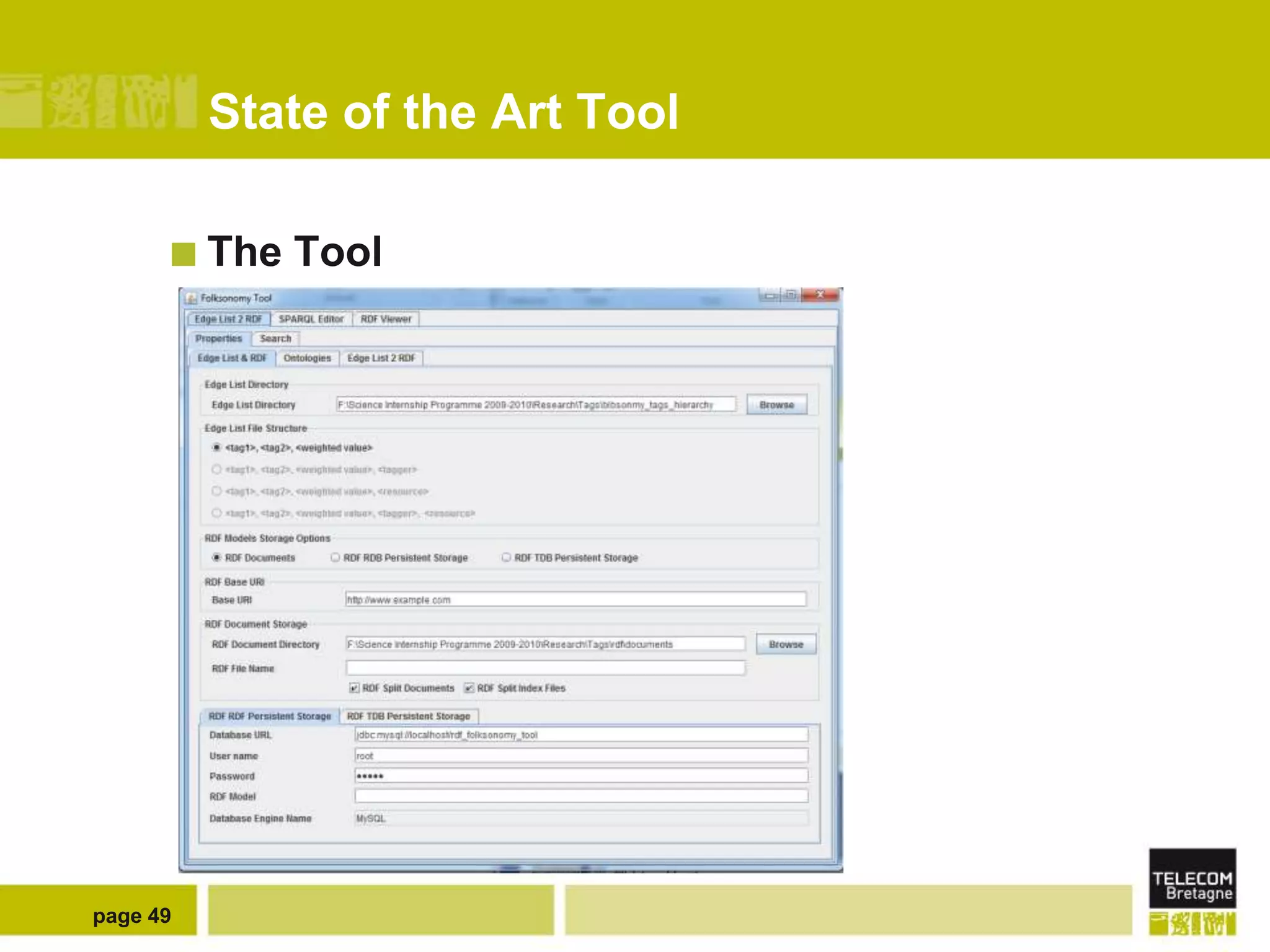
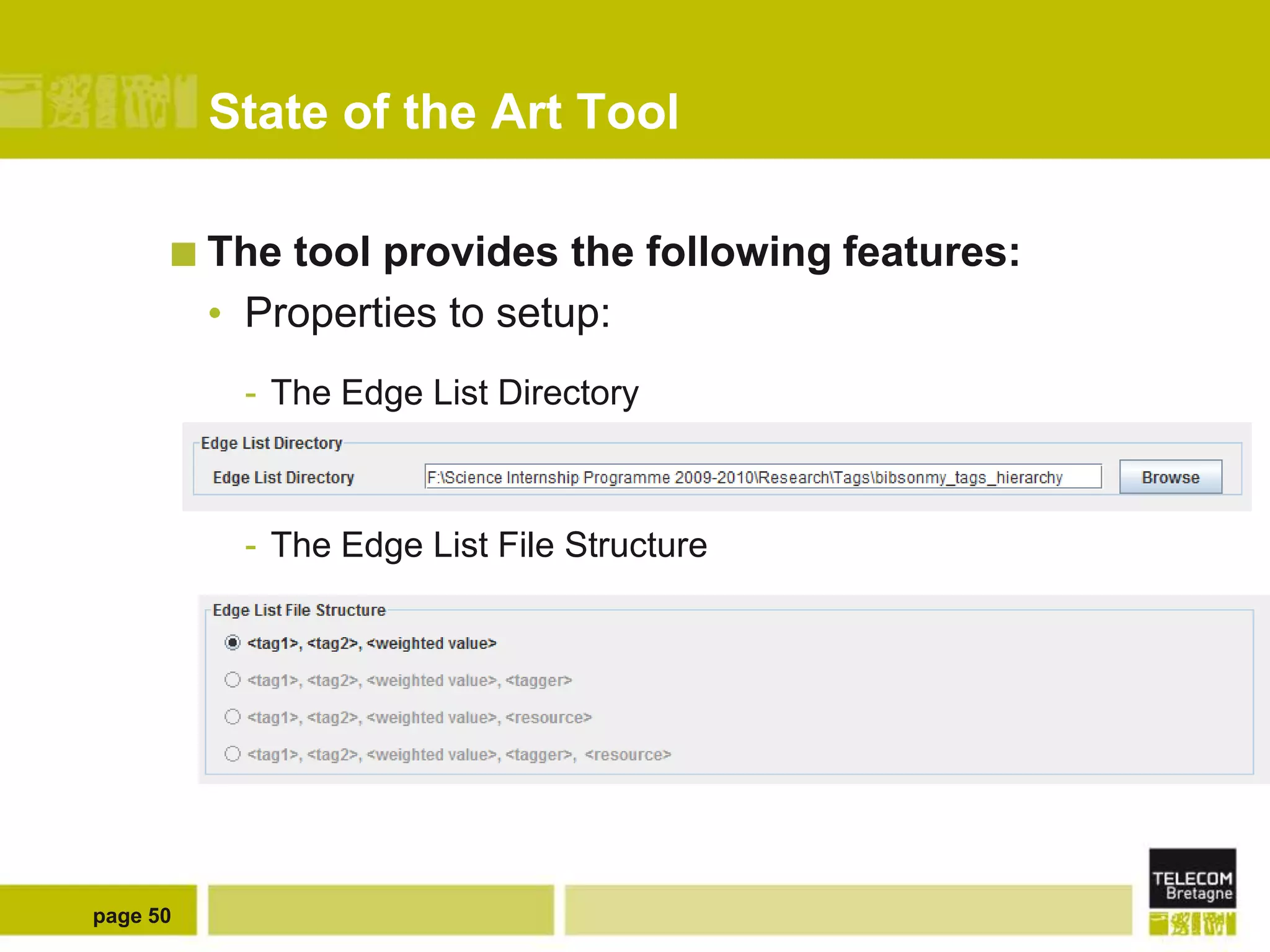

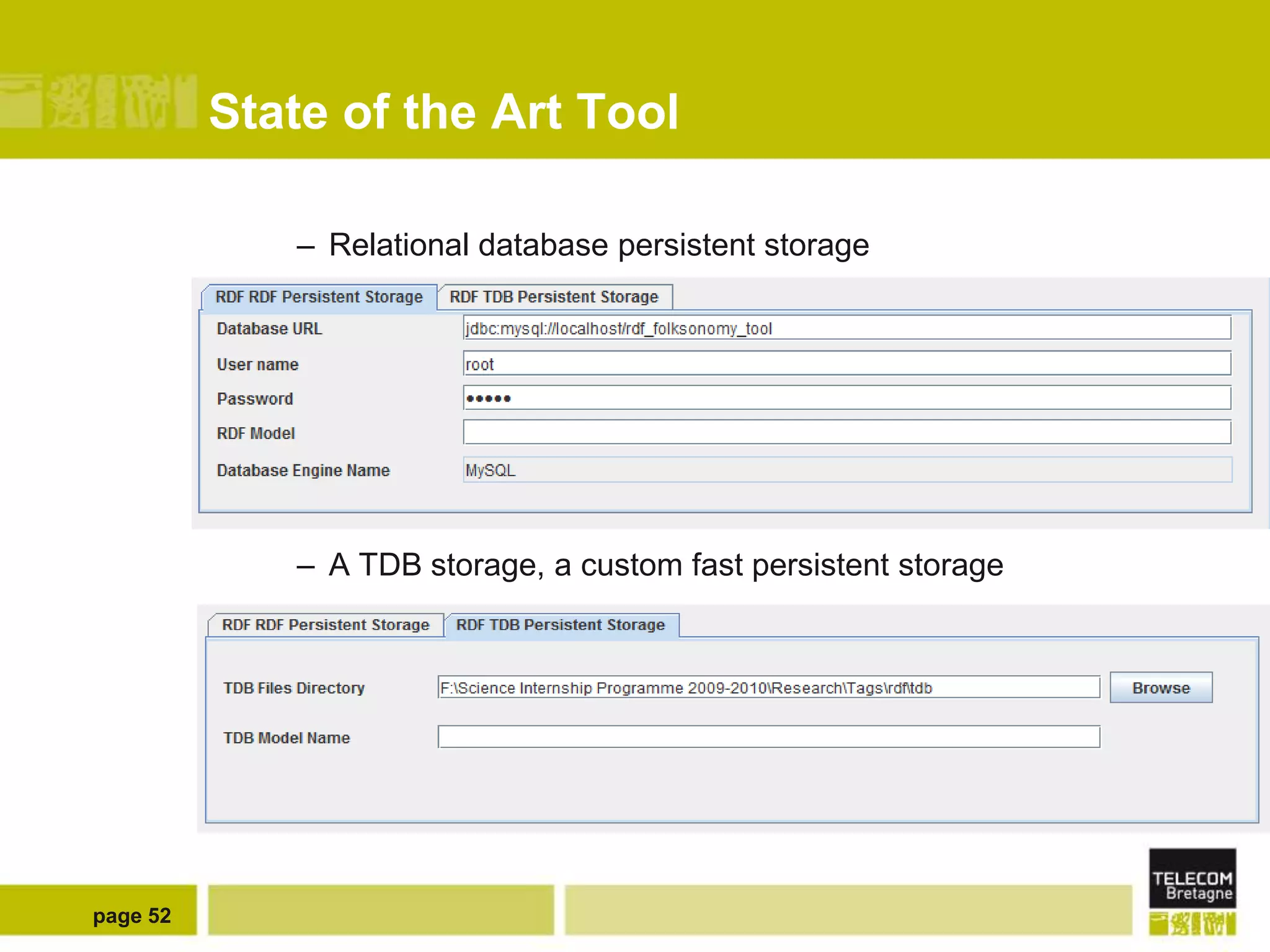
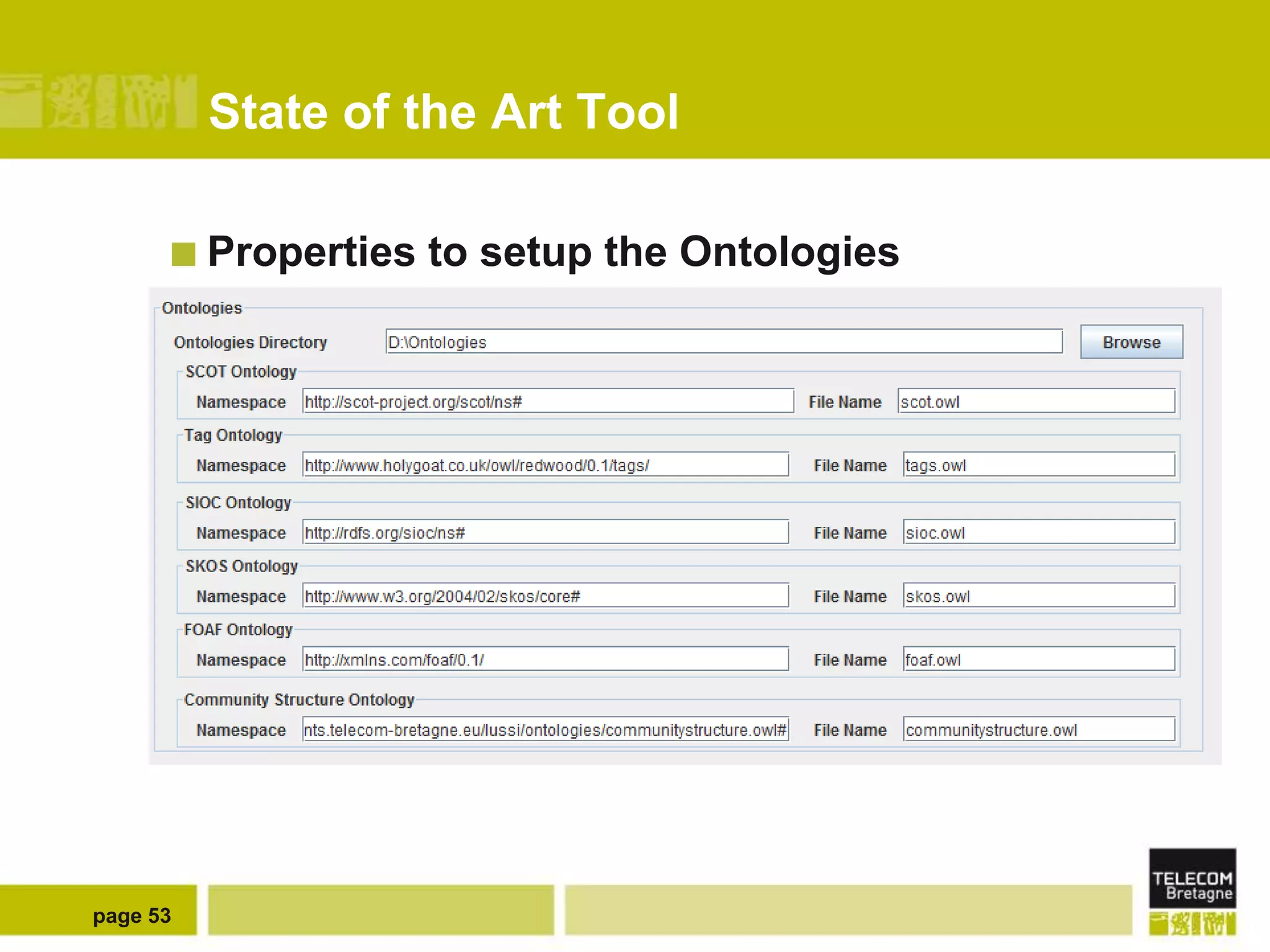
















The document discusses the use of semantic web technologies for representing and utilizing folksonomies, focusing on the integration of tags with the semantic web. It outlines various methodologies, including the 'fast unfolding of communities in large networks' algorithm, to analyze community structures and enhance data representation. Future enhancements aim to expand the application to larger tag models and optimize the processes for querying and writing data.
























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)










