Downloaded 16 times





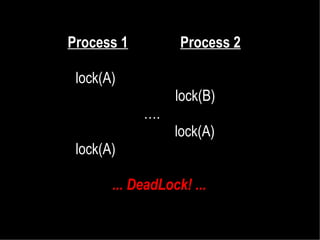

![Intel TSX
if(_xbegin()==-1) {
if( !fallback_mutex.is_acquired() ) {
tions.
sums[mygroup] += data[i];e instruc
impl
} else {
d to s
e
_xabort(1);
● Limit
ll-back
fa
}
erency
Coh
uires
● _xend();
Req
Cache
} else {
ing on
●fallback_mutex.acquire();
Relay
sums[mygroup] += data[i];
fallback_mutex.release();
}](https://image.slidesharecdn.com/openu-140212092522-phpapp01/85/Paractical-Solutions-for-Multicore-Programming-9-320.jpg)


![DSTM2
Maurice Herlihy et al, A flexible framework … [OOPSLA06]
@atomic public interface INode{
int getValue ();
void setValue (int value );
jects.
}
to Ob
d
imite
L
sive.
Factory<INode> factory ru
int = Thread.makeFactory(INode.class );
aries.
●
final INodeVery factory.create(); ort libr
node =
factory result = Thread.doIt(new Callable<Boolean>() {
’t supp e (fork).
n
● Does
public Boolean call nc
rma () {
return node.setValue(value);
perfo
● Bad
} });
●](https://image.slidesharecdn.com/openu-140212092522-phpapp01/85/Paractical-Solutions-for-Multicore-Programming-12-320.jpg)
![JVSTM
João Cachopo and António Rito-Silva, Versioned boxes as the
basis for memory transactions [SCOOL05]
public class Account{
private VBox<Long> balance = new aries.
VBox<Long>();
}
rt libr
suppo
public @Atomic void withdraw(long amount) {
esn’t
● Do
e. - amount); hared fields
balance.put rusiv
int(balance.get() nce” s
● Less
}
nnou
to “A
● Need](https://image.slidesharecdn.com/openu-140212092522-phpapp01/85/Paractical-Solutions-for-Multicore-Programming-13-320.jpg)
![Atom-Java
B. Hindman and D. Grossman. Atomicity via source-tosource
translation. [MSPC06]
public void update ( double value) {
Atomic {
ord.
w
commission += value; erved
a res
tion.
● Add
}
ompila ries.
pre-c
}
ibra
●
eed
N
ort l
’t supp sive.
n
● Does
s intru
n Les
● Eve](https://image.slidesharecdn.com/openu-140212092522-phpapp01/85/Paractical-Solutions-for-Multicore-Programming-14-320.jpg)
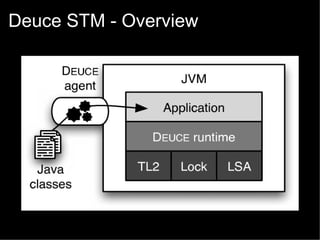
![Deuce STM - API
G. Korland, N. Shavit and P. Felber, “Noninvasive Java
Concurrency with Deuce STM”, [MultiProg '10]
public class Bank{
rds.
ed wo
private double commission = 10;
serv
No re
ased.
nb
tion.
@Atomicnnotatio
mpila
● A
re co
pac1,-Account ac2,rdouble amount){
public void transaction( Account
ies.
d for
ee
● No n (amount + commission);lib
al ra ol
ac1.balance -=
xtern
ac2.balanceppamount;e
+= orts
rch to
● Su
resea
}
able –
d
● Exten
}
●](https://image.slidesharecdn.com/openu-140212092522-phpapp01/85/Paractical-Solutions-for-Multicore-Programming-15-320.jpg)











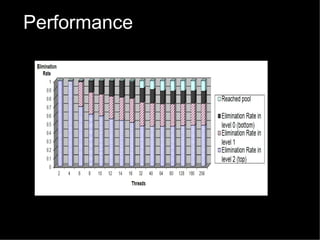





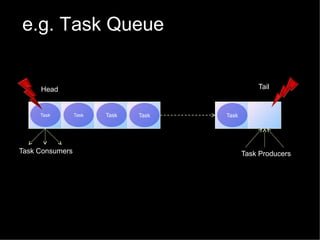
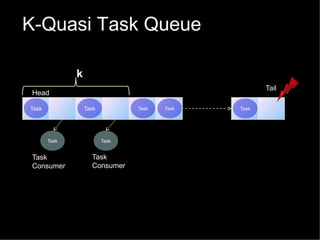
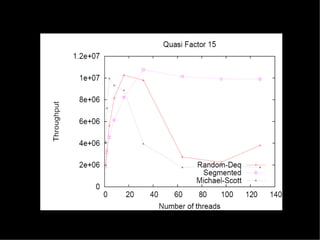
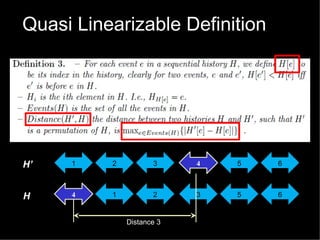




The document discusses practical solutions for multicore programming. It describes some challenges with concurrent programming such as lost updates, deadlocks, and lack of performance. It then presents several solutions to address these challenges, including software transactional memory (STM), lock-free data structures, and relaxed consistency models. STM approaches discussed include DSTM2, JVSTM, Atom-Java, and Deuce STM. It also discusses the need for fine-grained concurrent data structures like a lock-free pool. The document concludes by discussing how relaxing linearizability requirements through approaches like quasi-linearizability can improve concurrency.













![[Sitcon2018] Analysis and Improvement of IOTA PoW Implementation](https://cdn.slidesharecdn.com/ss_thumbnails/sitcon2018analysisandimprovementofiotapowimplementation-180306085230-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


































