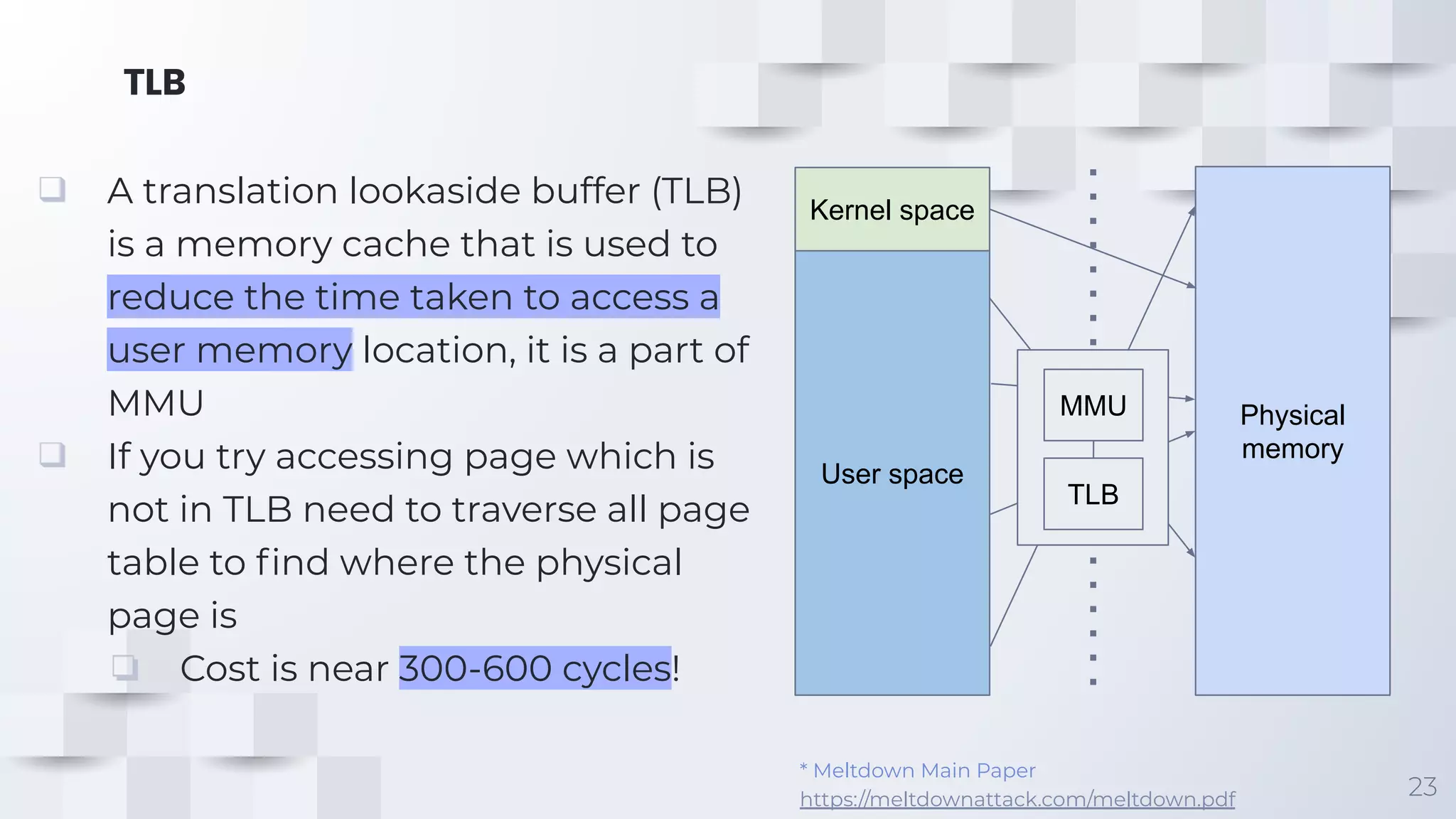
This document discusses the Meltdown and Spectre vulnerabilities that were discovered in modern CPUs. Meltdown allows reading kernel memory from user space by exploiting out-of-order execution and speculative execution. Spectre attacks exploit speculative execution to access sensitive information through side channels. The document explains speculative execution, how Meltdown works by inducing mispredictions and reading memory access times, and the two variants of Spectre that exploit conditional branches and indirect branches. Mitigations like KPTI and inserting blocking instructions are discussed along with the performance trade-offs of addressing these vulnerabilities.


















![Meltdown attack: side channel
20
1. C = A + B;
2. E = C + D;
3. G = E + F;
4. Z = G + Y
5. if (Z == 0){
6. J = kernel_mem[addr];
7. L = J & 0x01;
8. N = L * 4096;
9. M = user_mem[N];
10. }
1. C = A + B; _J = kernel_mem[addr];
2. E = C + D; _L = _J & 0x01;
3. G = E + F; _N = _L * 4096;
4. Z = G + Y; _M = user_mem[_N];
5. if (Z == 0){
6. J =_J; L =_L; N =_N; M =_M;
7. }
8. t1 = get_time();
9. V = user_mem[0];
10. t2 = get_time();
11. delta = t2 - t1;
ALU 1 ALU 2
Predictor
thinks this is
true
Normally, this should receive
segmentation fault, but not in
speculative case
As this will never being executed, _J,
_L and _N will be never revealed
If the difference is < 10
cycles the 1st
bit of
kernel_mem[addr] = 0](https://image.slidesharecdn.com/meltdownspectrefinal-210224132210/75/Meltdown-Spectre-20-2048.jpg)









![Variant 1 : Bound Check Bypass
31
1. array a = …; // size 400
2. array b = …; // size 512
3. offset = …; // user input
4. if (offset < size(a)){
5. v = a[offset];
6. i = (v & 0x01) * 4096;
7. x = b[i];
8. }](https://image.slidesharecdn.com/meltdownspectrefinal-210224132210/75/Meltdown-Spectre-31-2048.jpg)
![Variant 2 : Poisoning Indirect Branches
❏ Indirect branch instructions have ability to jump to more than
two possible target addresses.
❏ X86 example
❏ jmp eax: Address in register
❏ jmp [eax]: Address in memory location
❏ jmp dword ptr [0x12345678]
❏ Address from the stack (“ret”)
❏ MIPS example
❏ jr $ra
32](https://image.slidesharecdn.com/meltdownspectrefinal-210224132210/75/Meltdown-Spectre-32-2048.jpg)
![How can we use this?
❏ Find unsafe user code [unlikely]
❏ Use JIT Compiler of user code [highly likely]
❏ Google PoC uses BPF (packet filter in JIT)
in Linux kernel
❏ Microsoft PoC uses Javascript
❏ Potentially any visited website can
access all your RAM memory
33](https://image.slidesharecdn.com/meltdownspectrefinal-210224132210/75/Meltdown-Spectre-33-2048.jpg)








































































