Downloaded 23 times






















![26© Cloudera, Inc. All rights reserved.
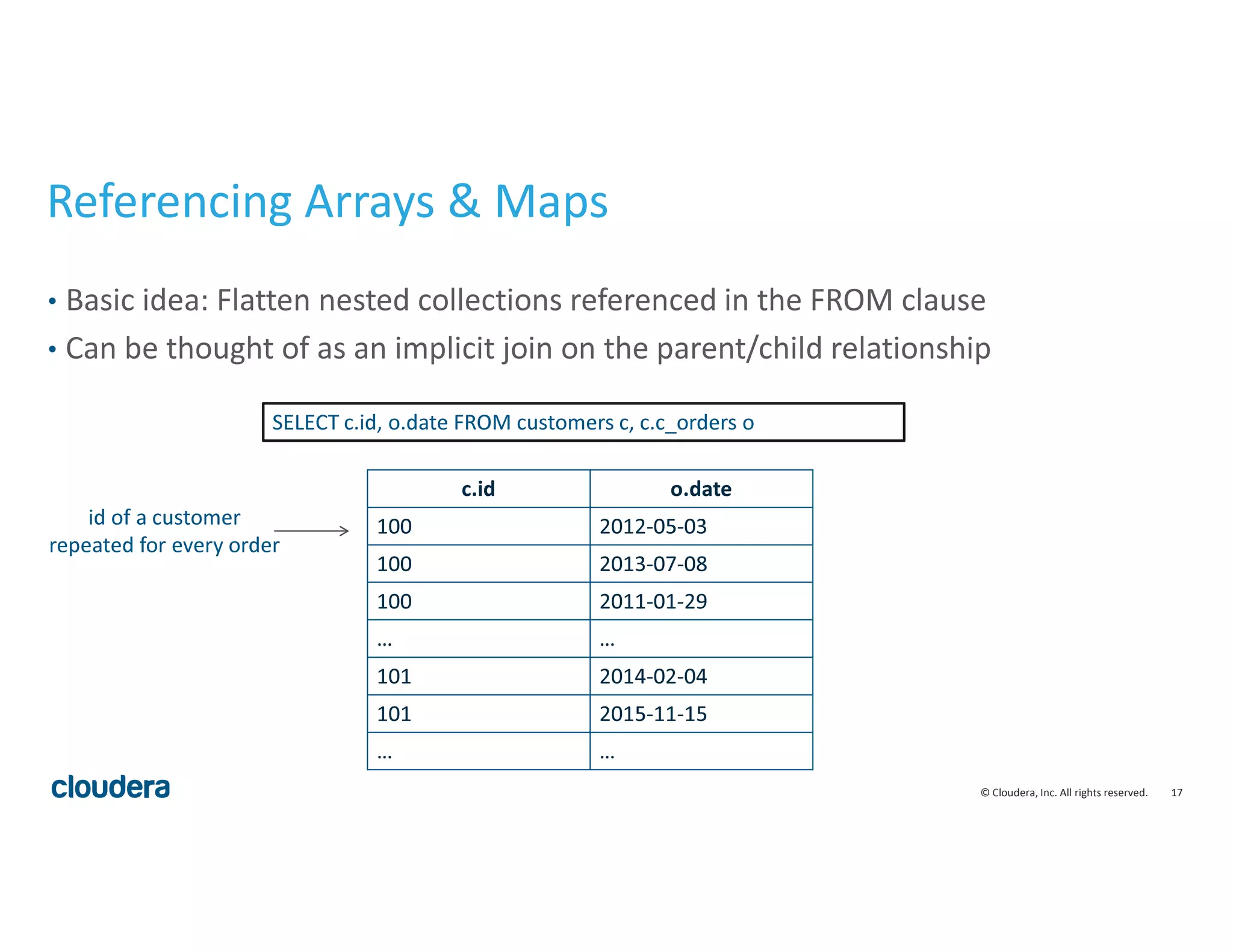
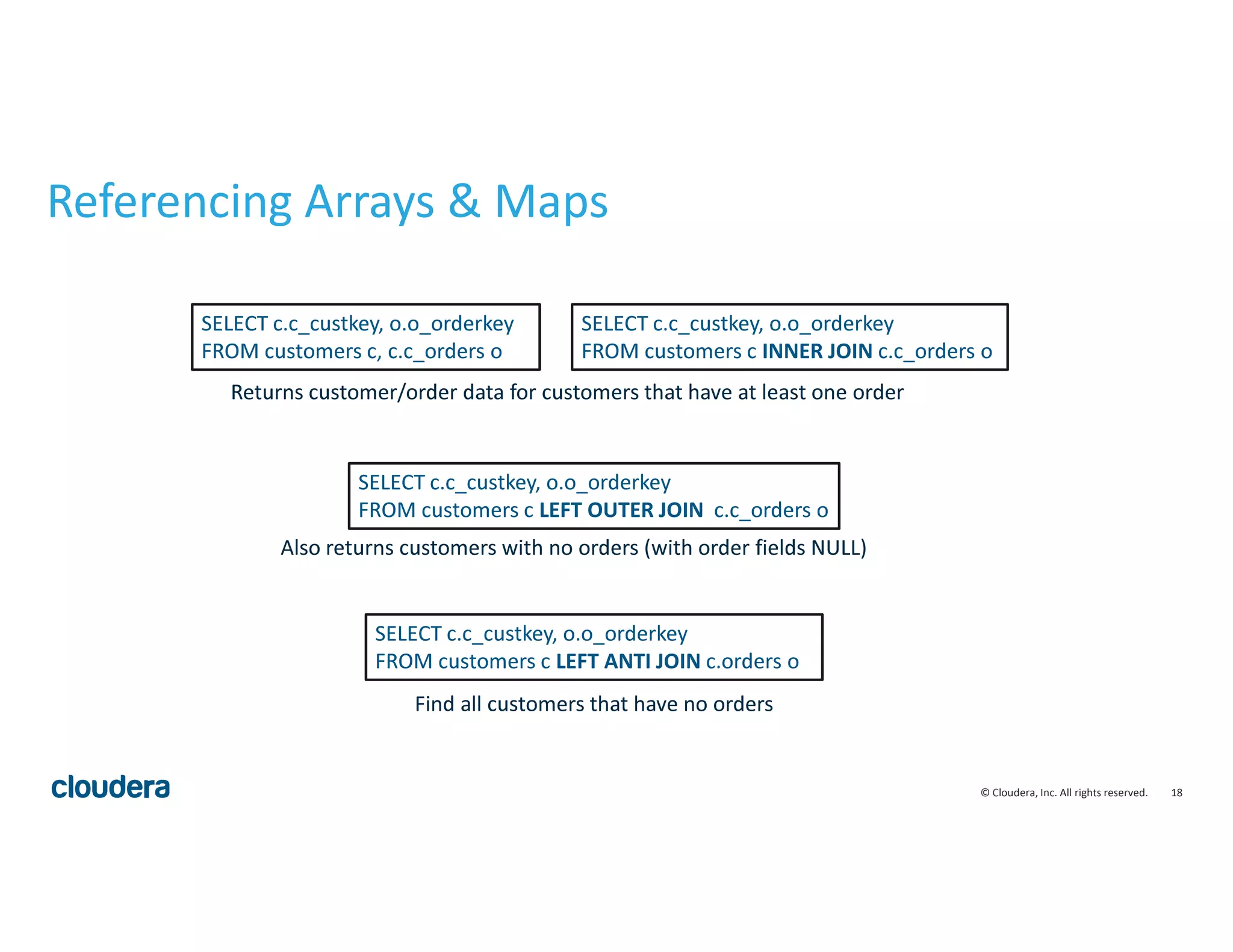
Columnar Storage for Complex Schemas
• Columnar storage: a necessity for processing nested data at speed
• complex schemas = really wide tables
• row-wise storage: read lots of data you don’t care about
• Columnar formats effectively store a join index
{id: 17
orders: [{date: 2014-01-29, price: 10.2}, {date: ….} …]
}
{id: 18
orders: [{date: 2015-04-10, price: 2000.0}, {date: ….} …]
}
17
18
10.2
22.1
100
200
id orders.price
…
…
…](https://image.slidesharecdn.com/marcelkornackerclouderanestedtypes-160531131049/75/Marcel-Kornacker-Software-Enginner-at-Cloudera-Data-modeling-for-data-science-Simplify-your-workload-with-complex-types-26-2048.jpg)


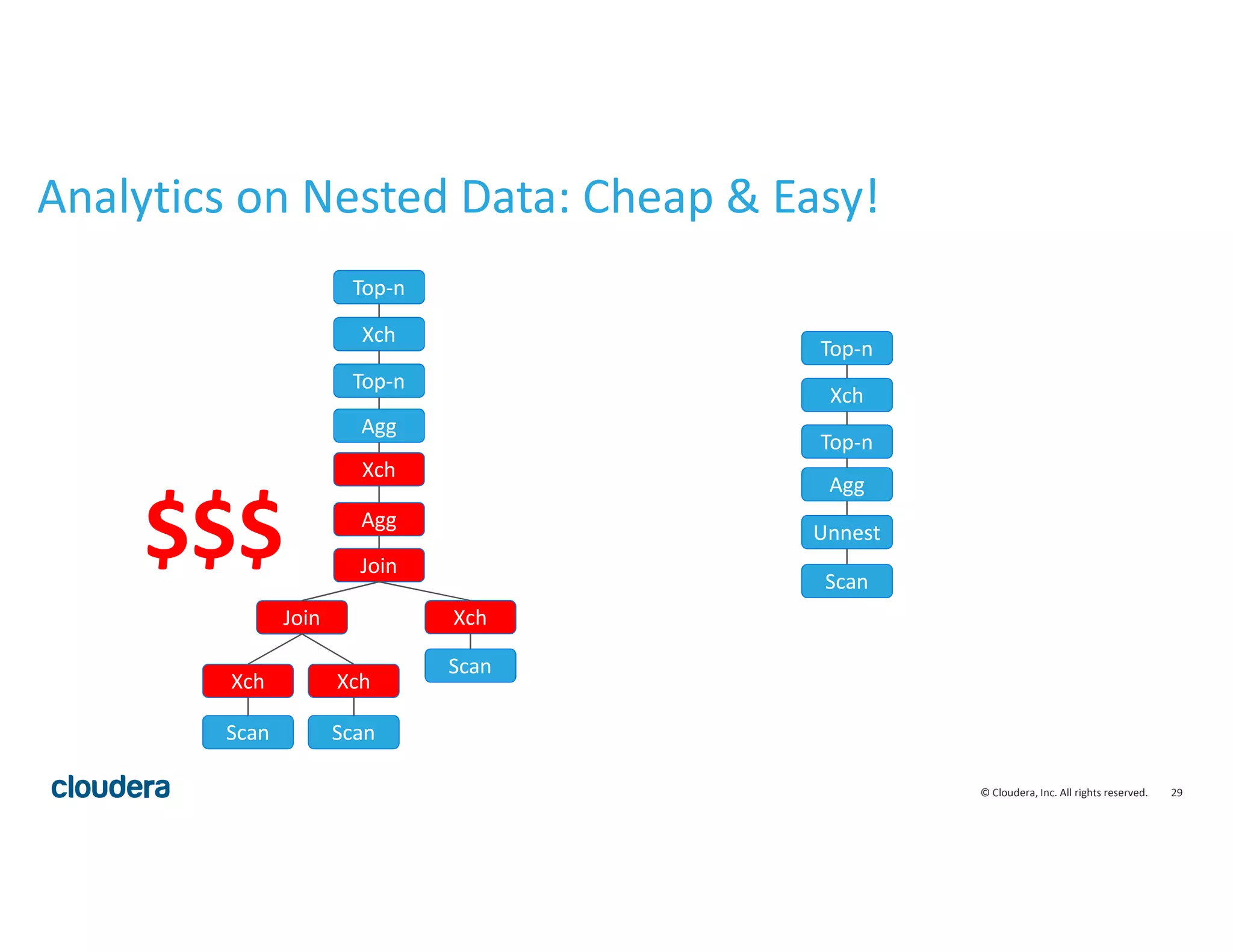



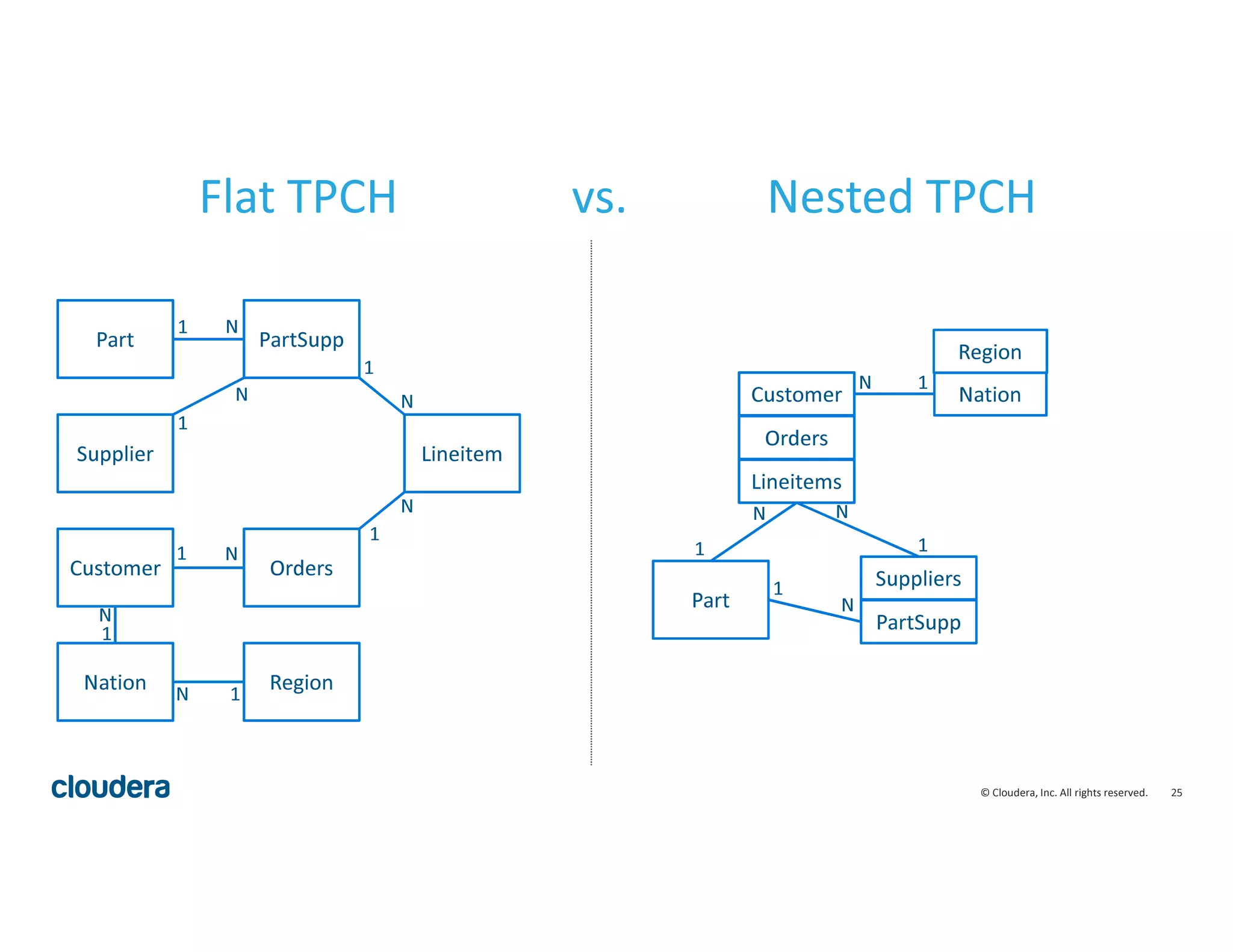
The document discusses how relational databases are optimized for flat schemas but much real-world data uses complex schemas. It advocates for using intentional complex schemas to simplify analytic workloads. It describes how SQL engines like Impala can handle complex schemas through extensions like supporting nested data types of struct, map, and array to allow full SQL expressiveness over nested data. Columnar storage is also important for efficiently processing complex schemas.
























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)















