Download to read offline

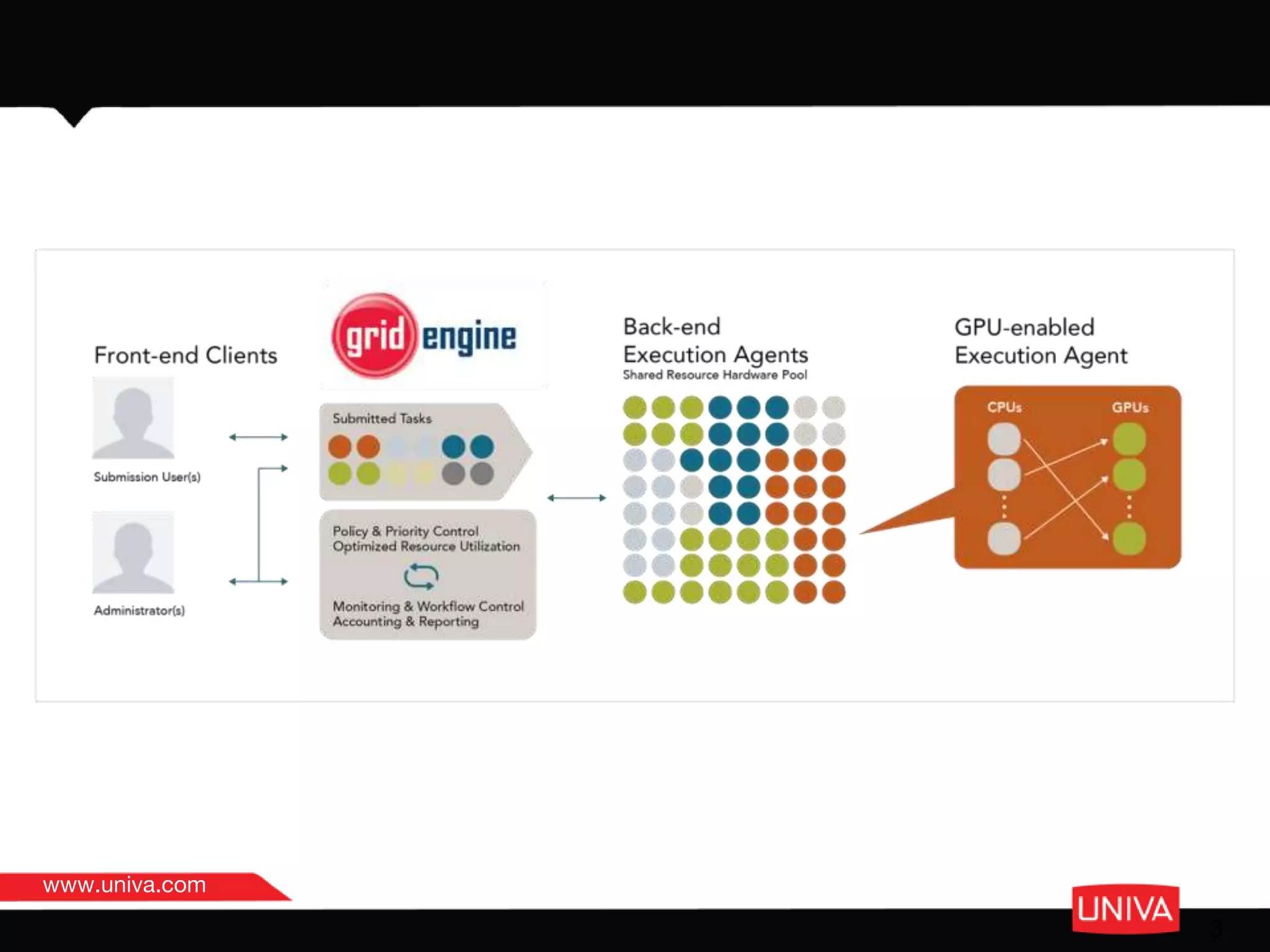
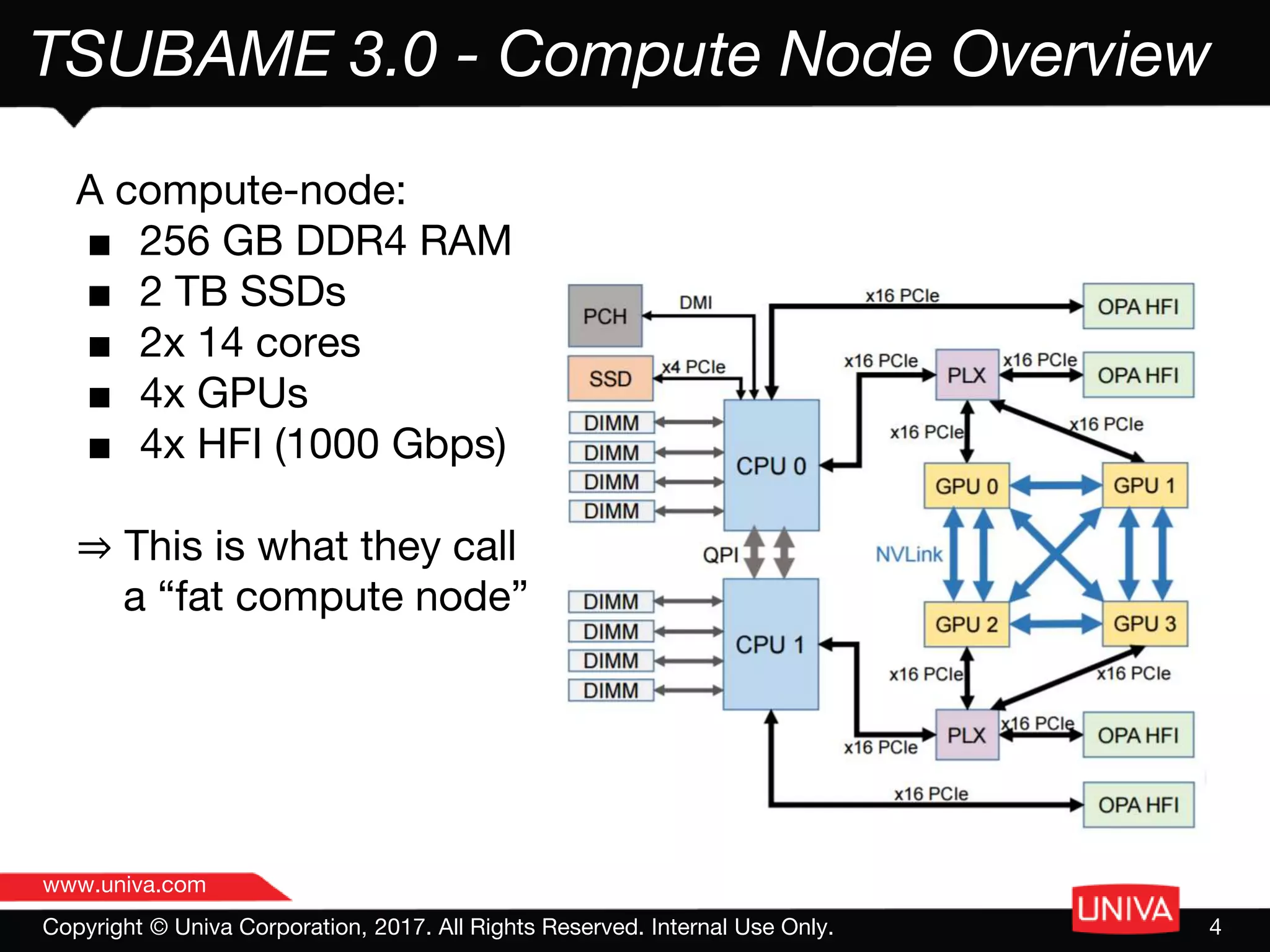





The document discusses the features and advantages of Tsubame 3.0, a high-performance computing (HPC) machine with significant capabilities in managing containerized HPC and AI workloads. It highlights the machine's specifications, challenges related to resource utilization, and enhancements in job management through unique container configurations and improved resource allocation strategies. The emphasis is on maximizing performance and efficiency by utilizing smart partitioning and Docker integration for flexible workload management.













































































