Download as PDF, PPTX




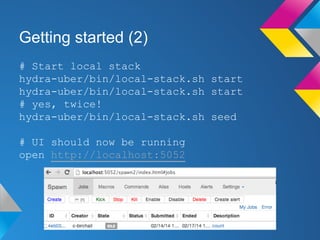
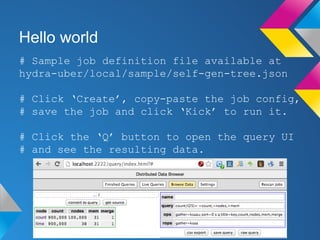



Hydra is a Hadoop-style distributed processing framework optimized for building and navigating tree data structures. It includes components for job control, task running, querying, and a distributed filesystem. To get started, users install prerequisites like RabbitMQ and Maven, clone and build the Hydra repository, start the local stack, seed sample data, and can then run sample jobs and queries to see results. The document provides tips for analyzing text files with Hydra and concludes that it is well suited for applications that involve working with tree data structures.















































