Download as PDF, PPTX




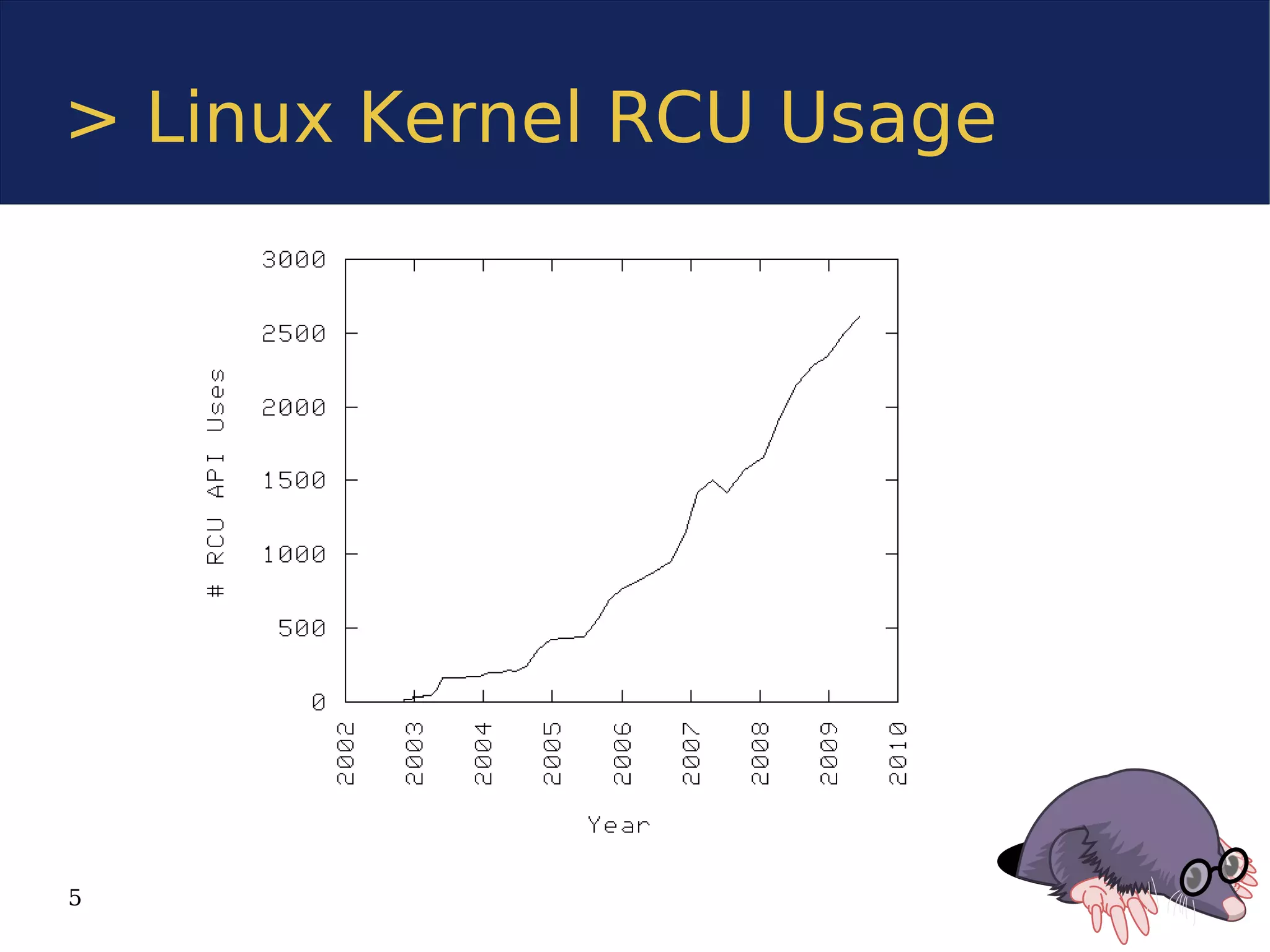

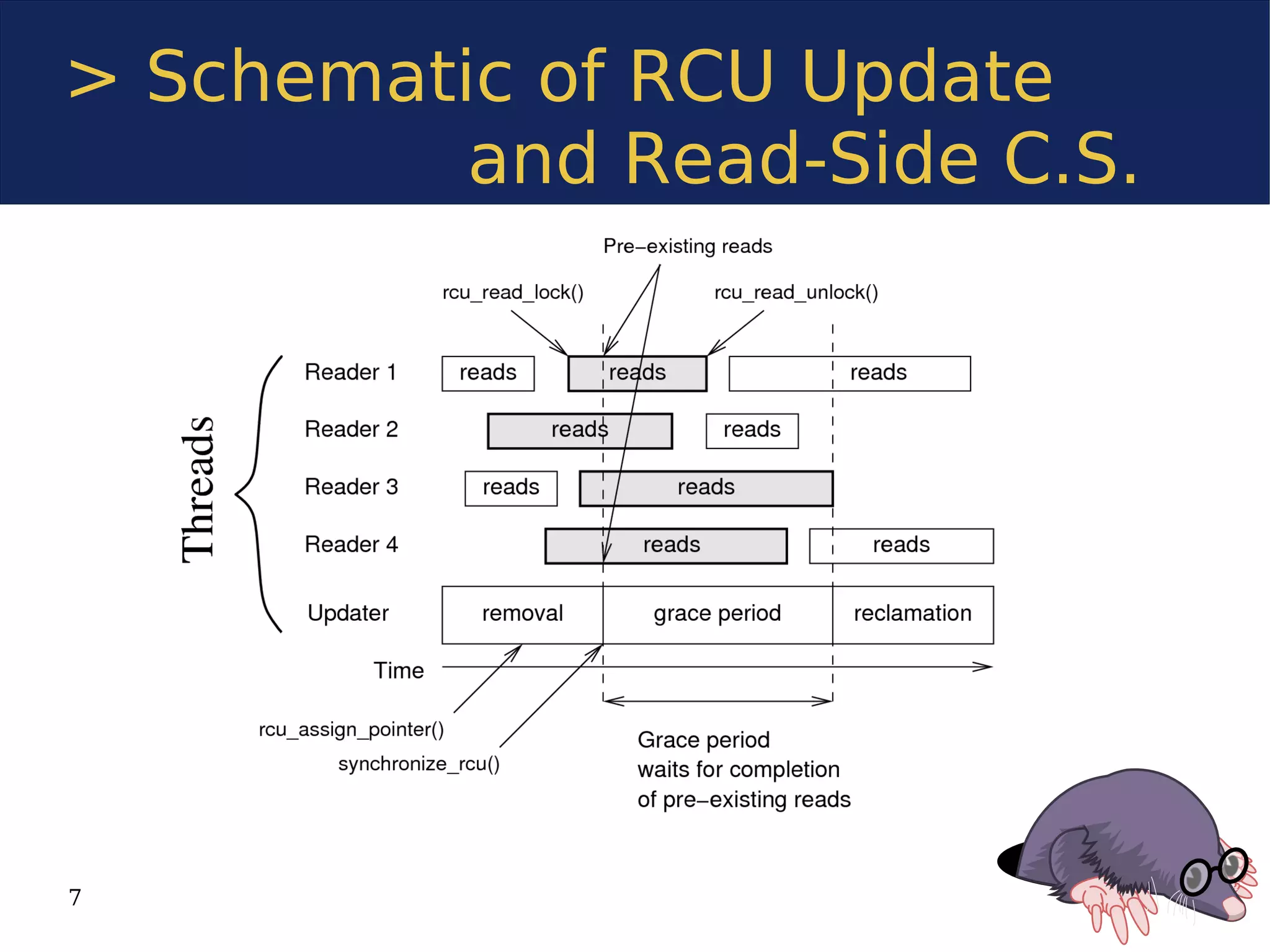
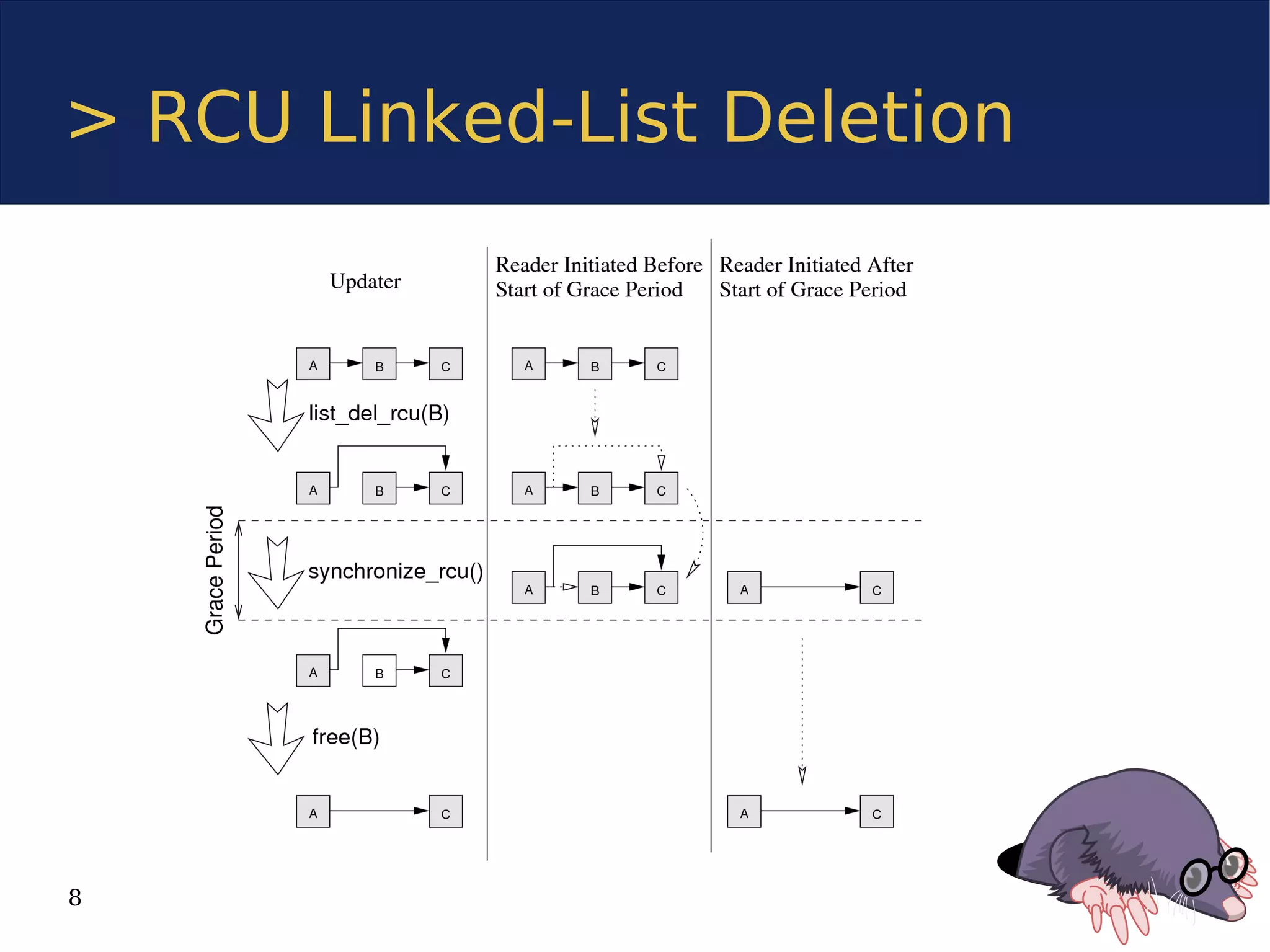










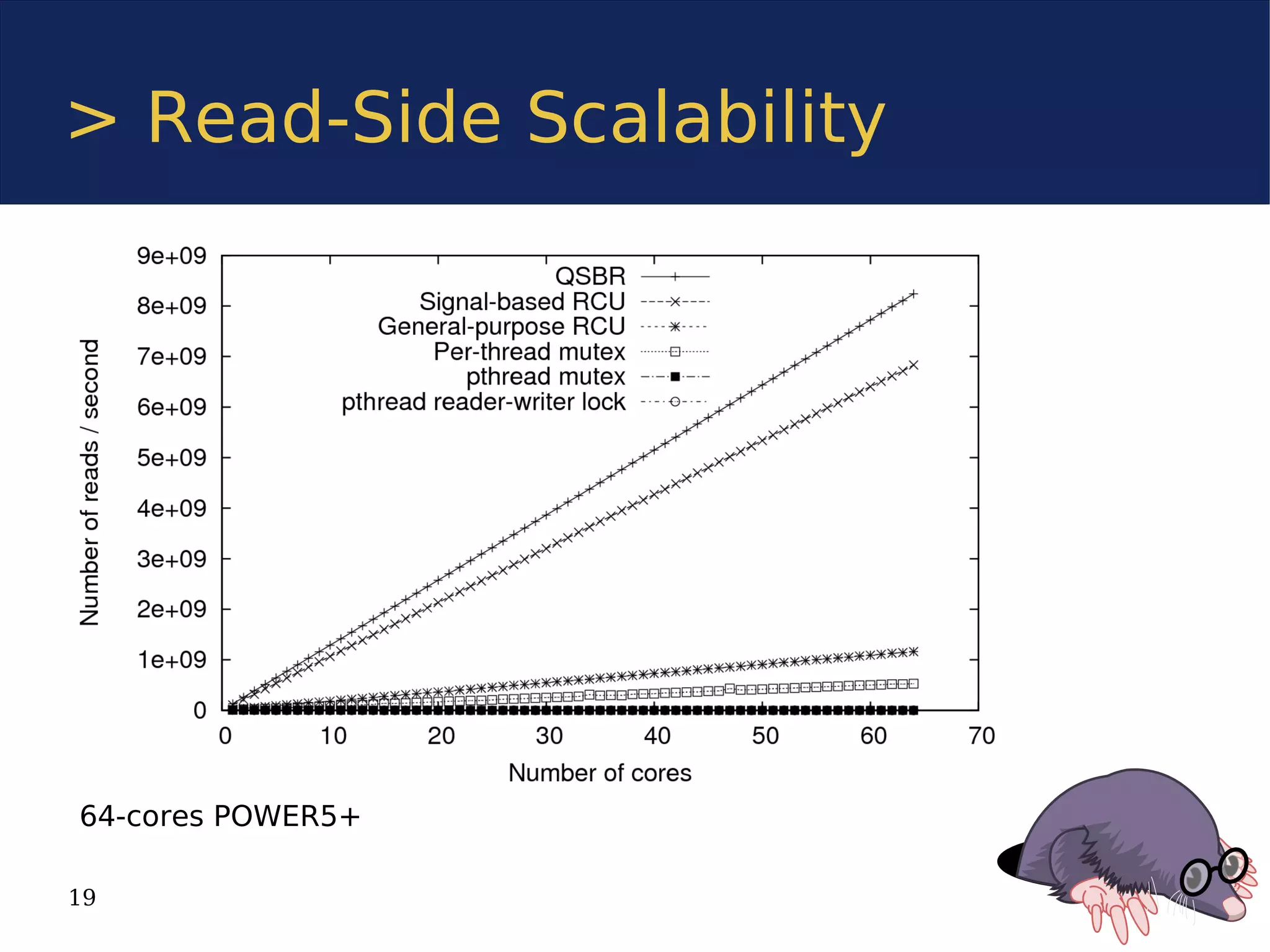
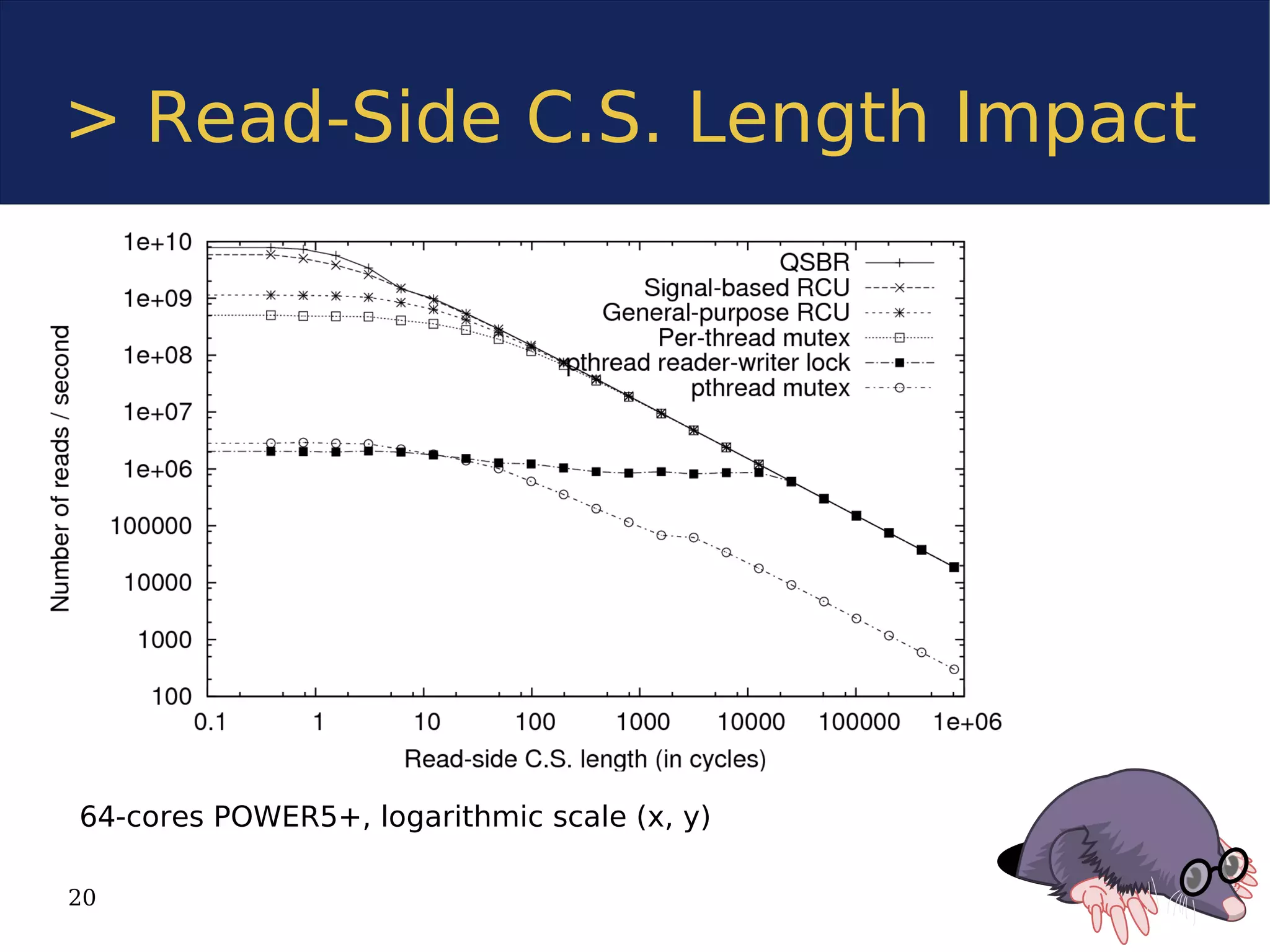
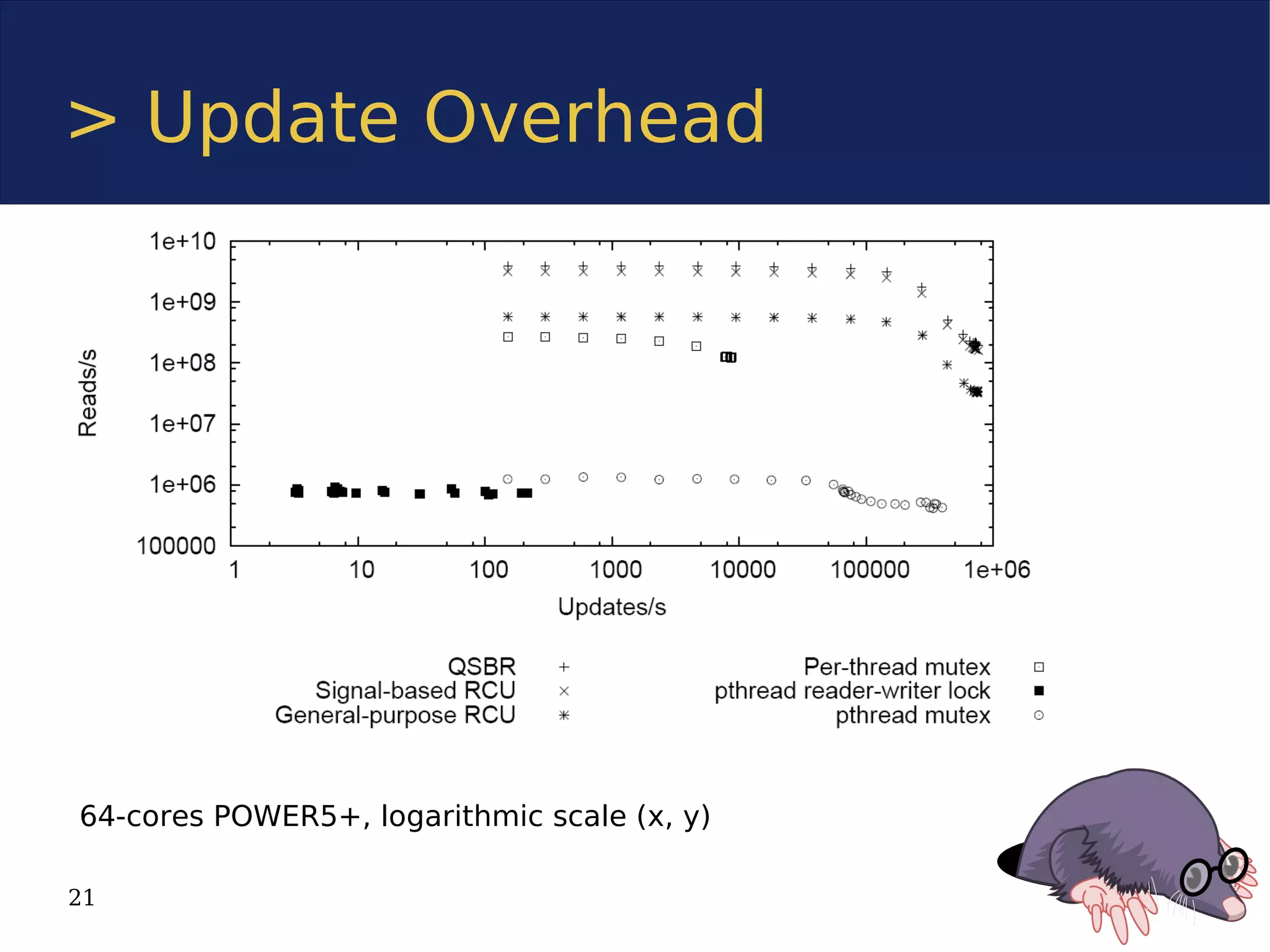






The document discusses the Userspace RCU (Read-Copy Update) library, detailing its implementation for improving linear multiprocessor scalability in applications. It compares kernel vs userspace RCU, highlights various implementations, and offers benchmarks for performance evaluation. Additionally, it outlines how RCU can benefit multithreaded applications by minimizing synchronization overhead.


































































