Download to read offline


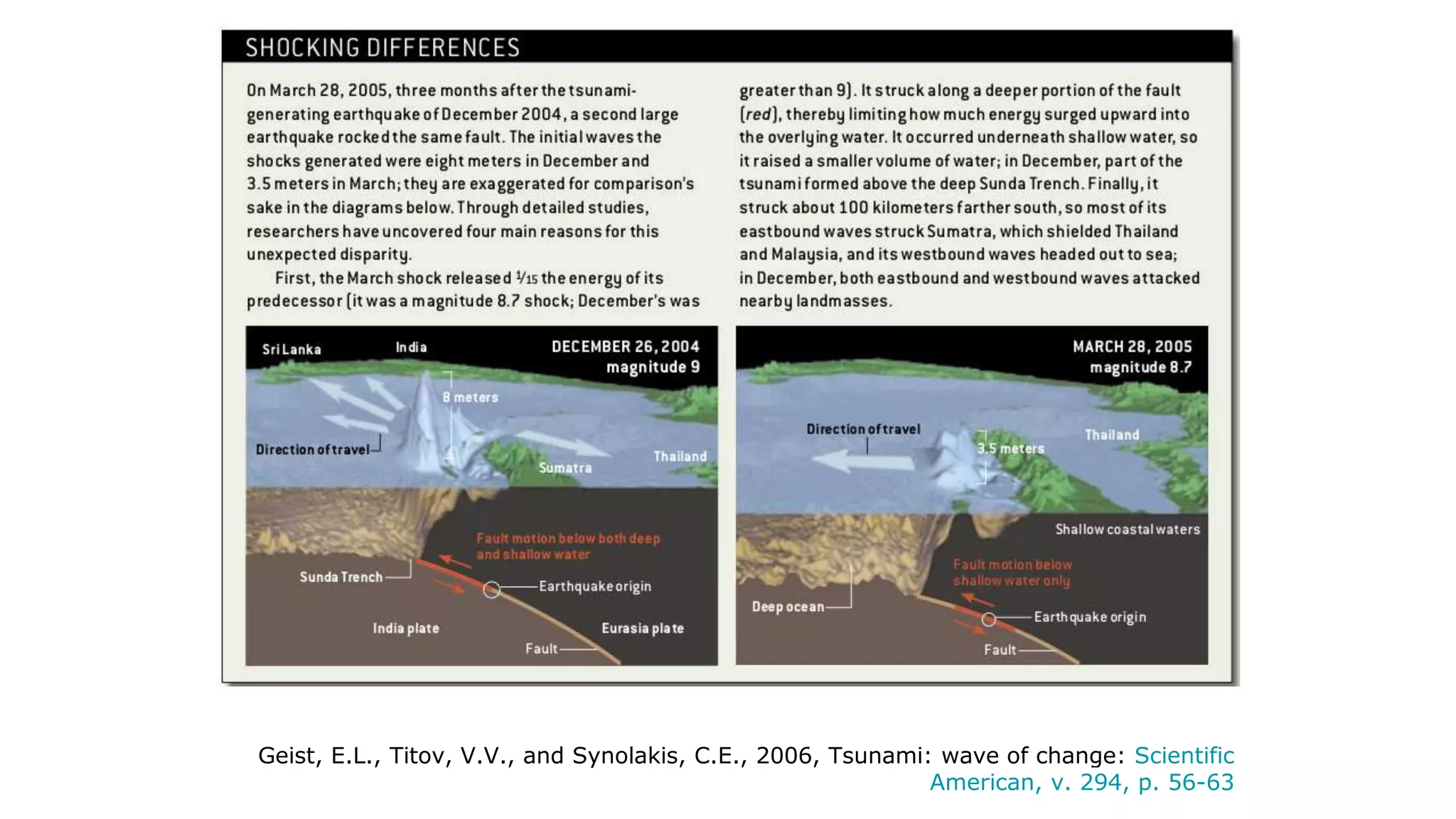



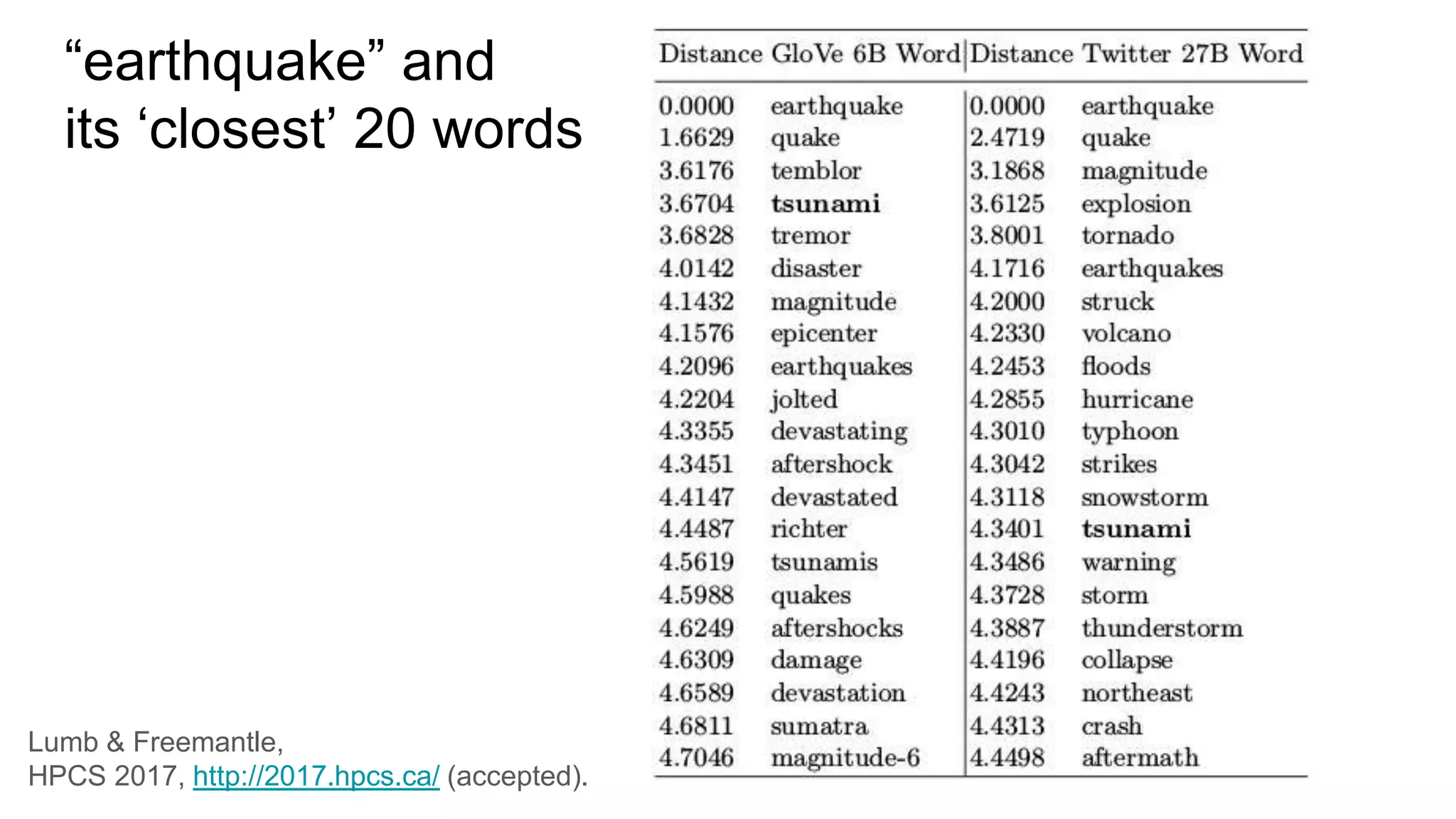
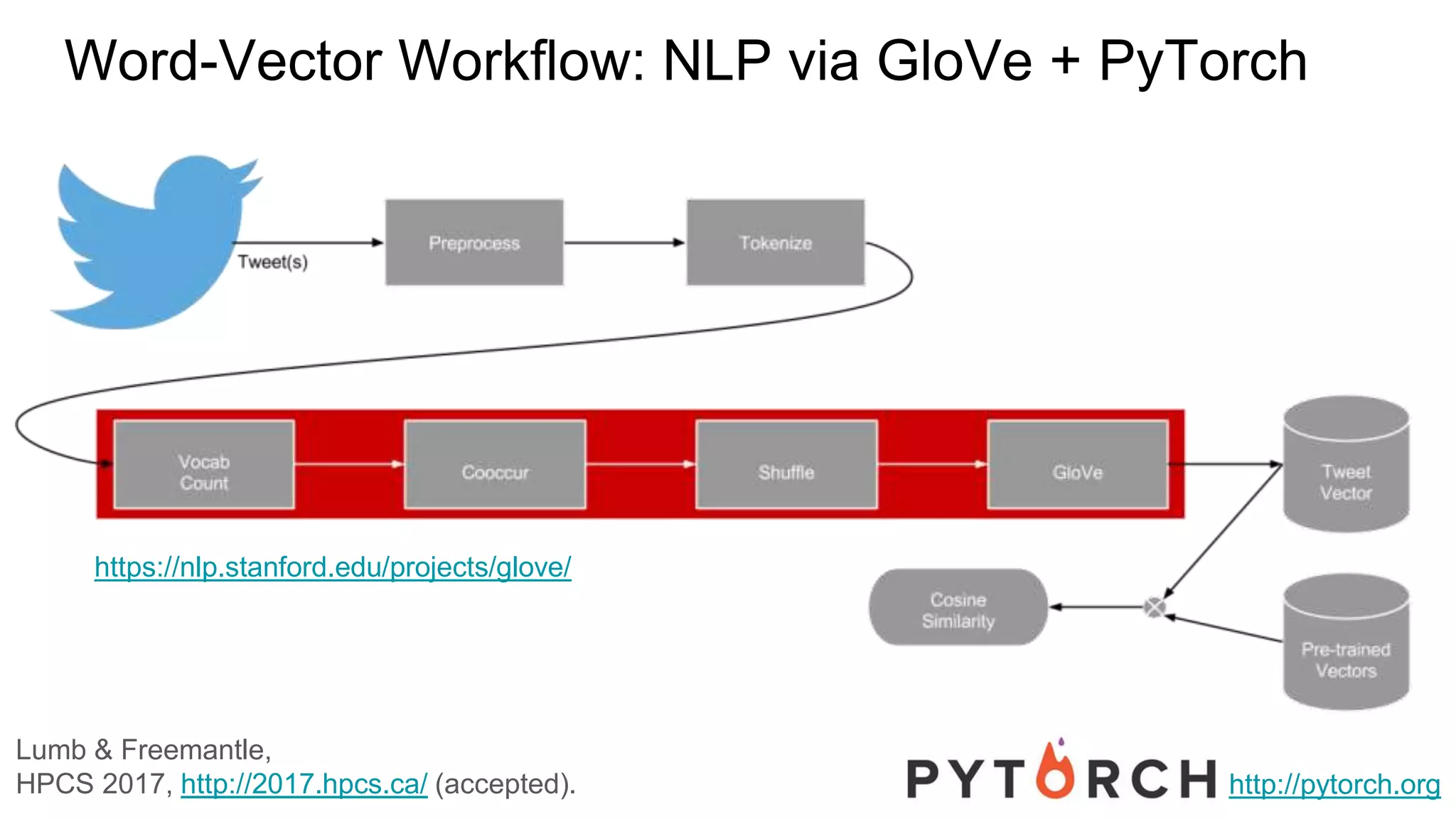
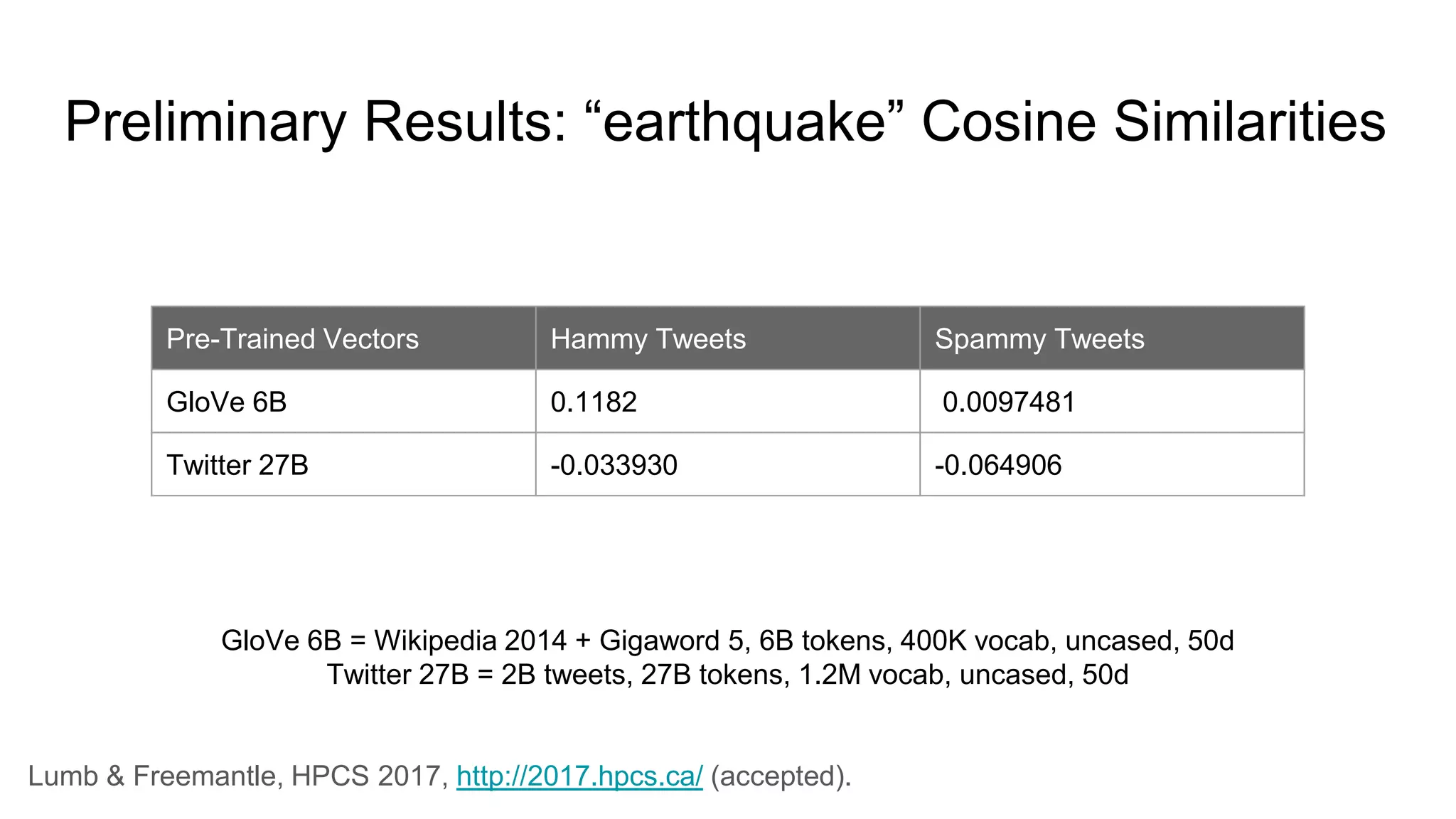

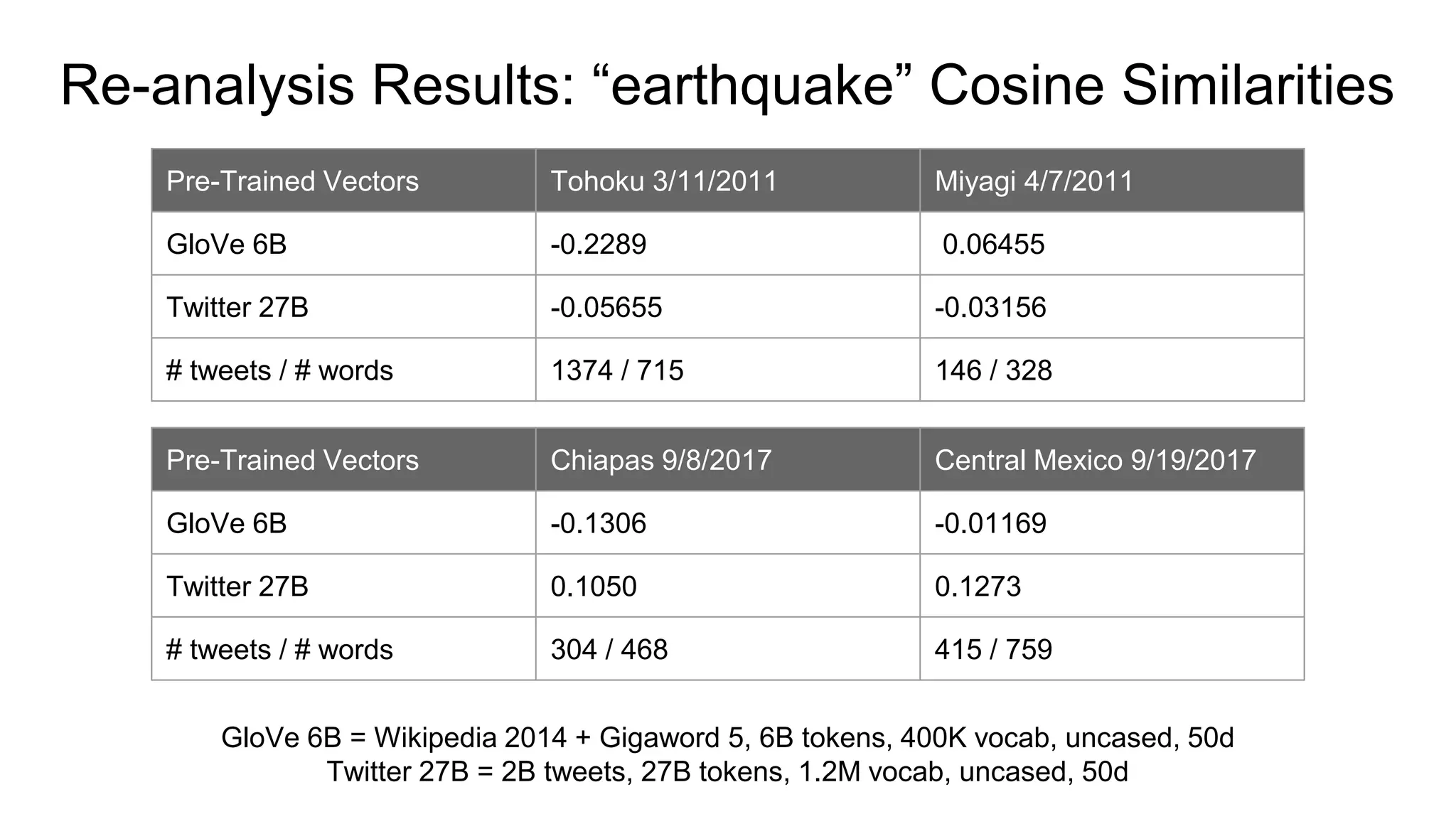
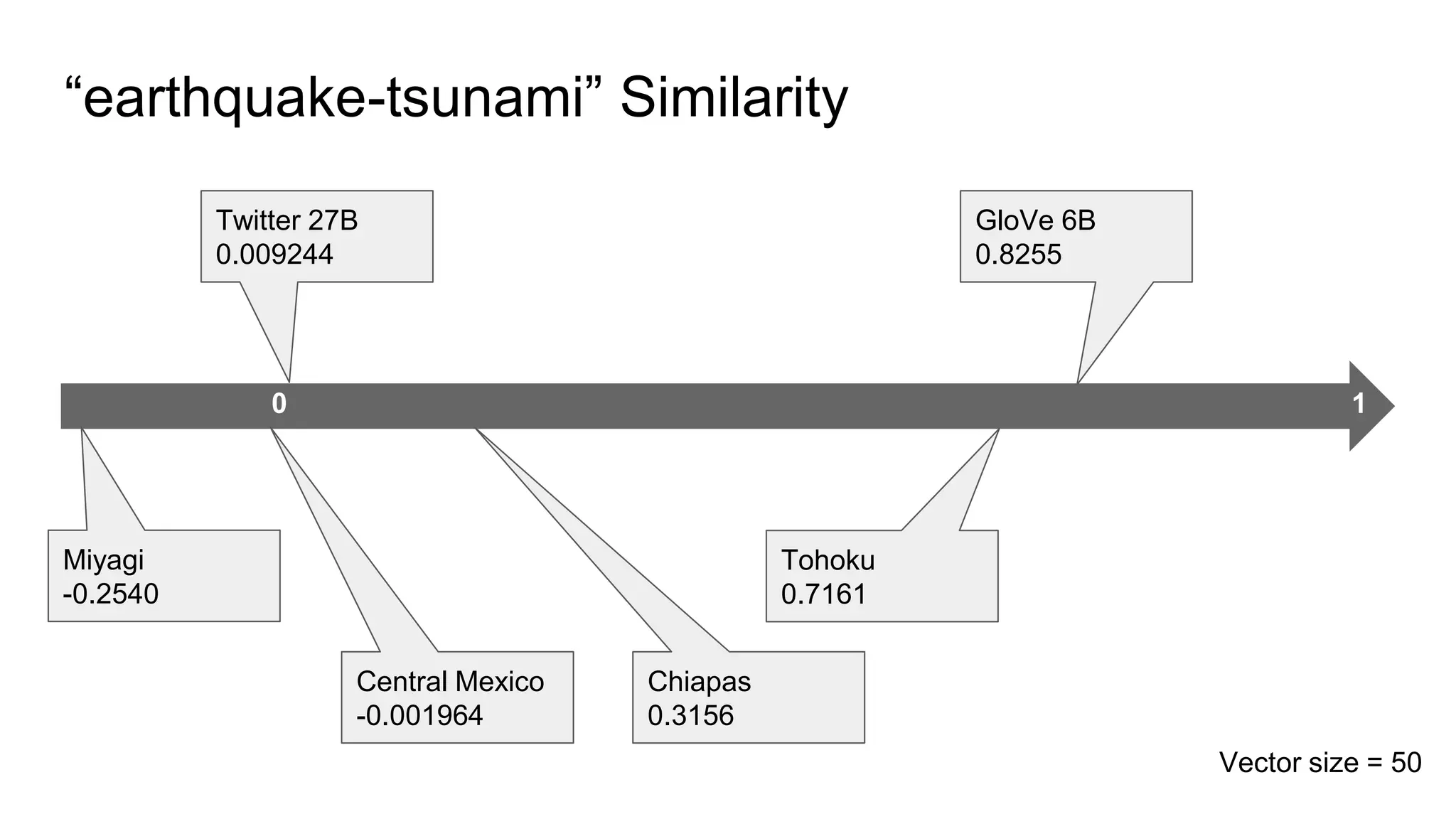




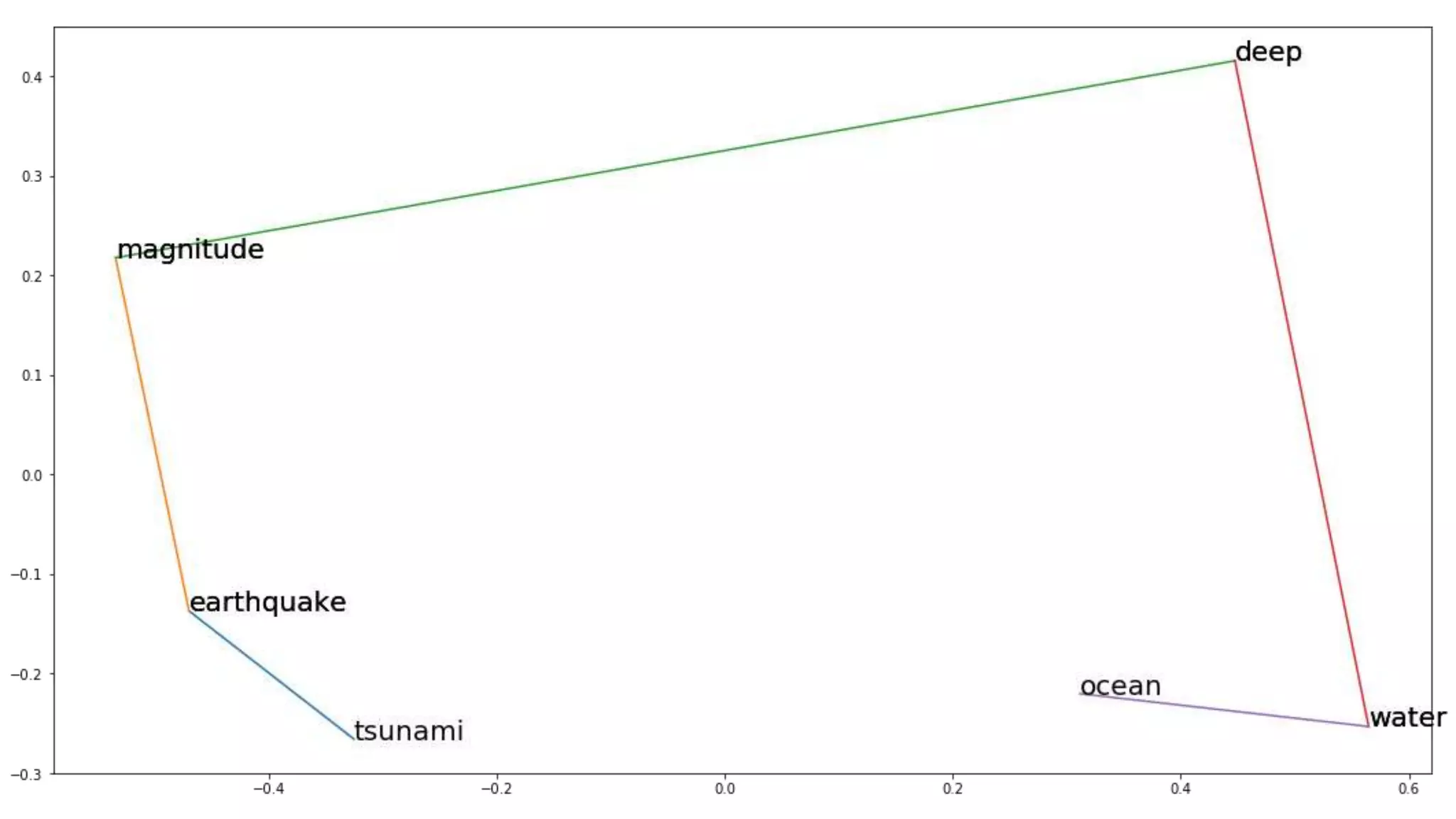



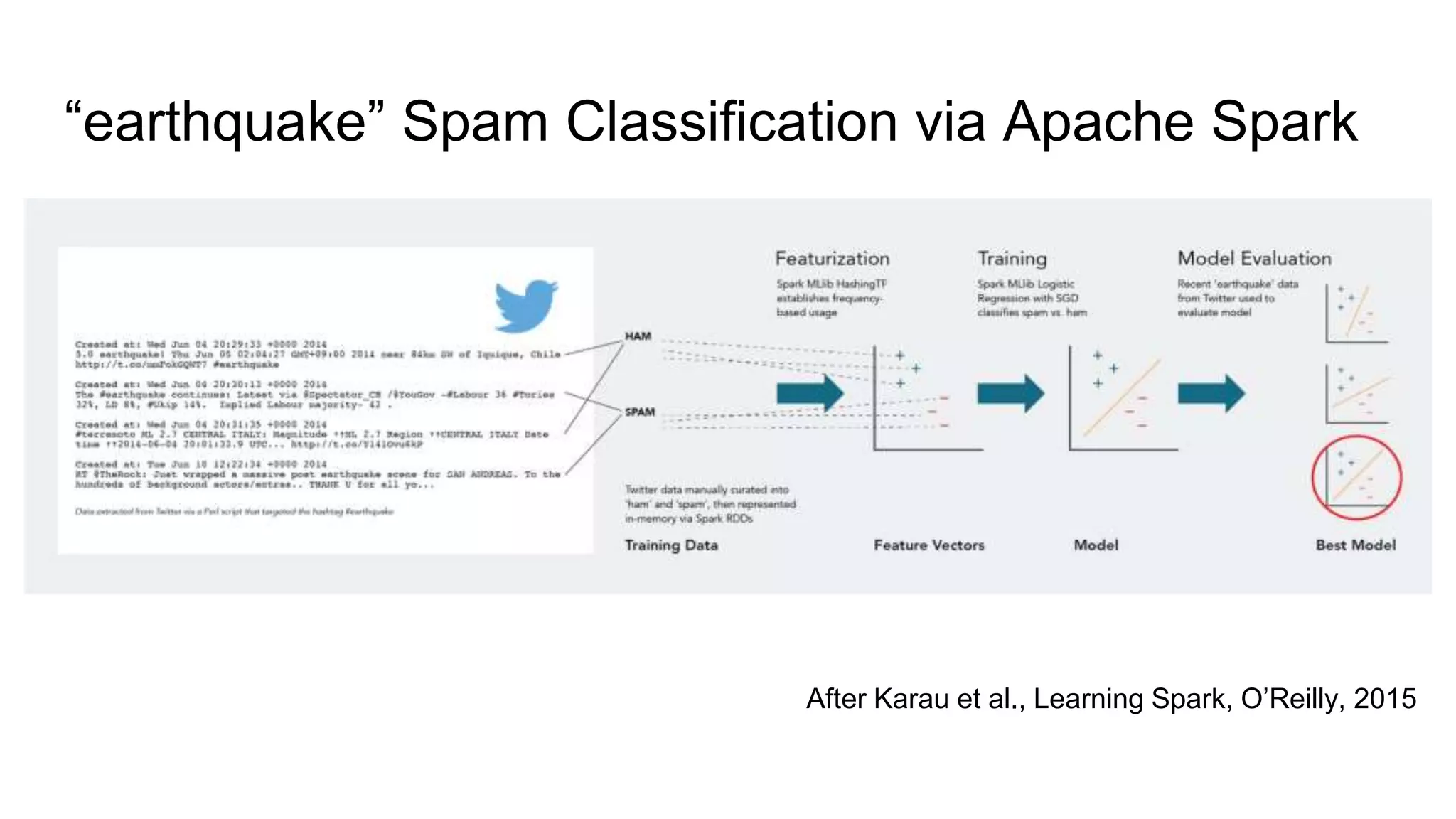


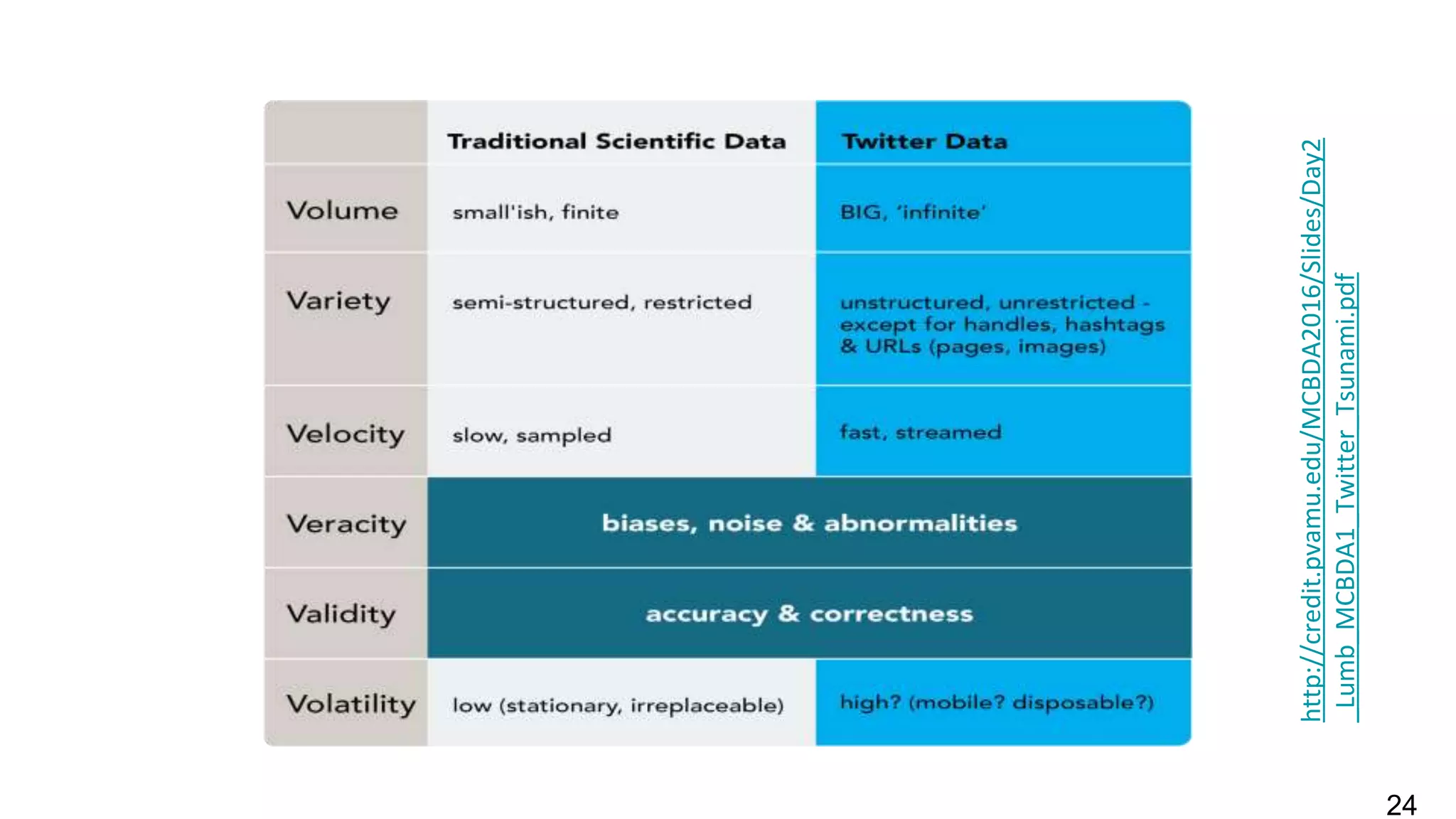

This document discusses the use of deep learning and natural language processing (NLP) to enhance tsunami alerts through Twitter data analysis. It emphasizes the importance of accurate training data and explores the effectiveness of word embeddings in distinguishing relevant seismic events from unrelated content. The findings indicate a shift towards real-time analysis and applications in disaster scenarios beyond tsunamis.




























































