Download as PDF, PPTX


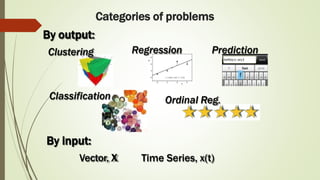

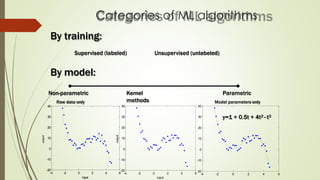
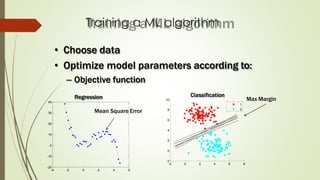

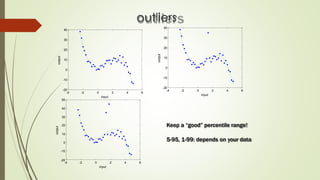
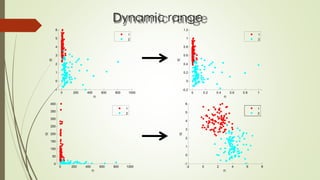
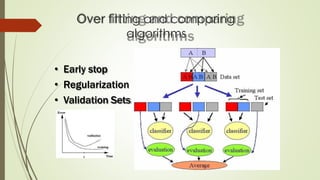

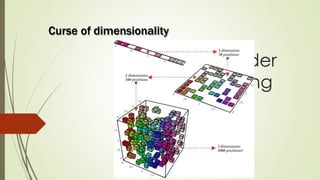
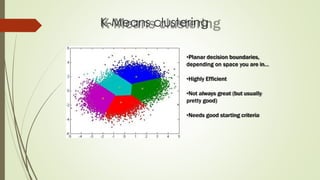

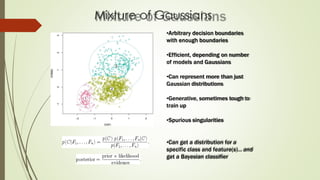


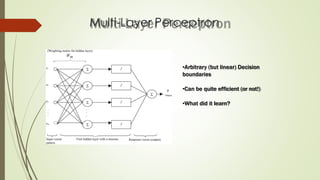

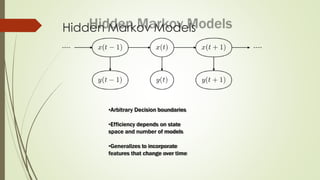


The document provides an overview of machine learning, including its definitions, categories, and training methods, along with critical considerations for improving algorithms. Key topics discussed include supervised and unsupervised learning, pitfalls like overfitting and underfitting, and various classification techniques such as k-means clustering and support vector machines. It emphasizes the importance of feature selection and data preprocessing in the training process.



































































