Download to read offline

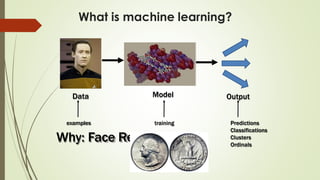


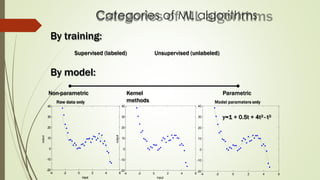
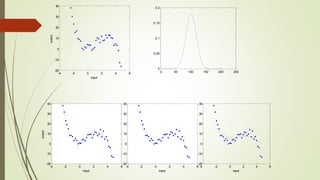



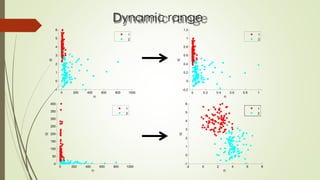
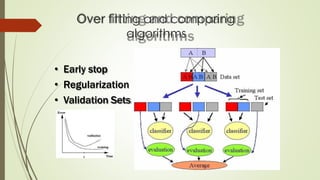


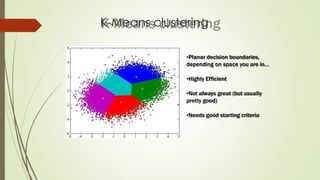




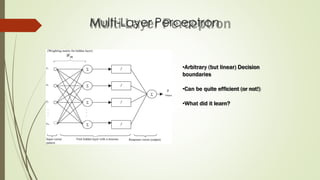

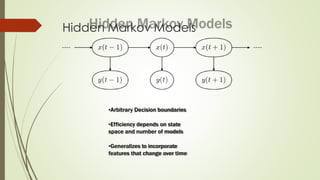


The document provides an overview of machine learning concepts and algorithms, including training methodologies, types of problems (like classification and regression), and challenges such as overfitting and underfitting. It discusses various machine learning algorithms, including supervised and unsupervised methods, and highlights the importance of feature selection and data preprocessing. Additionally, it emphasizes the significance of visualizing data classes and trends for improving algorithm performance.



































































