Downloaded 29 times



![Ruby is many things
Ruby is a dynamic, reflective, object-oriented, general-
purpose programming language. [...] Ruby was influenced
by Perl, Smalltalk, Eiffel, Ada, and Lisp. It supports multiple
programming paradigms, including functional, object-
oriented, and imperative. It also has a dynamic type system
and automatic memory management.
~Wikipedia](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-3-320.jpg)





![(defobs process-modified-path
[pid path]
:doc "A pathname modified by a process,
associated by the PID."
:tags ["process" "file" "directory" "path"])
assert observations
Malware analysis generates
analysis data, which in turn
generates observation data that
can be queried by core.logic.
Some observations are exported
to the database.](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-10-320.jpg)
![(defioc autoexec-bat-modified
:title "Process Modified AUTOEXEC.BAT"
:description "A process modified the AUTOEXEC.BAT file. ..."
:category ["persistence" "weakening"]
:tags ["process" "autorun" "removal"]
:severity 80
:confidence 70
:variables [Path Process_Name Process_ID]
:query [(process-modified-path Process_ID Path)
(matches "(?i).*AUTOEXEC.BAT" Path)
(process-name Process_ID Process_Name)])
Logic programs are queries
Security researchers write
core.logic queries over the
observations.
Declarative nature combined with
abstraction make queries small
and high level.](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-11-320.jpg)
![(defioc sinkholed-domain-detected
:title "Domain Resolves to a Known DNS Sinkhole"
:description "..."
:category ["research" "defending"]
:tags ["network" "dns" "sinkhole" "botnet"]
:severity 100
:confidence 100
:variables [Answer_Data Answer_Type Query_Data
Query_Type Network_Stream]
:query
[(fresh [qid]
(dns-query Network_Stream qid (lvar)
Query_Type Query_Data)
(dns-answer Network_Stream qid (lvar)
Answer_Type Answer_Data (lvar)))
(sinkhole-servers Answer_Data)])
Logic programs are queries
We combine rules with internal
knowledge bases.
Declarative queries combined
with abstraction make queries
small and high level.](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-12-320.jpg)
![Indicators produce data
{:ioc autoexec-bat-modified
:hits 1
:data ({Process_ID 1200
Process_Name "smss.exe"
Path "AUTOEXEC.BAT"})
:confidence 70
:truncated false
:title "Process Modified AUTOEXEC.BAT"
:description "A process modified the AUTOEXEC.BAT ..."
:severity 80
:category ["persistence" "weakening"]
:tags ["process" "autorun" "removal"]}
Queries generate data that is
used in reports.](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-13-320.jpg)



![run
run([], succeed)
This is the simplest possible
minikanren. There are no query
variables, and the query always
succeeds
run says "give me all the results"
and in ruby minikanren is an
array. This query returns one
result, which matches the empty
query.
[[]]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-17-320.jpg)
![run
run([], fail)
This query fails. There are no
matches, so the result is an
empty array.
[]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-18-320.jpg)
![FRESH
fresh introduces logic variables.
Logic variables are the things we
want to find the values of.
Minikanren programs often use q
to represent the query.
_.0 represents an unbound logic
variable in the results. We are
saying, the query succeeded and
the result is anything.
["_.0"]
q = fresh
run(q, succeed)](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-19-320.jpg)
![FRESH
This query has two logic
variables, and we find one
results, where both logic
variables are unbound and
different. (or at least not
constrained to be the same) [["_.0", "_.0"]]
a, b = fresh 2
run([a, b], eq(a, b))](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-20-320.jpg)
![unification
run(q, eq(q, :hello))
The most fundamental operation
on a logic variable is to unify it.
unification is eq.
There is only one value of q that
satisfies the relation. [:hello]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-21-320.jpg)
![unification
run(q, eq(q, [:hello, :world]))
Logic variables can also be
unified over non-primitive values
There is still only one value of q
that satisfies the relation.
[[:hello, :world]]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-22-320.jpg)
![all
run(q, all(eq(q, :helloworld),
eq(:helloworld, q)))
All expresses that all conditions
must be true.
A logic variable can unify with the
same value multiple times. But
the overall goal only succeeds
once, so there is only one value
of q that satisfies the relation.
[:helloworld]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-23-320.jpg)
![all
run(q, all(eq(q, :hello),
eq(q, :world)))
A logic variable cannot unify with
two different values at the same
time.
There are no values of q that
satisfy the relation. []](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-24-320.jpg)
![conde
run(q,
conde(eq(q, :hello),
eq(q, :world)))
You can introduce alternative
values with conde. Every conde
clause that succeeds produces
possible alternative values.
There are 2 values of q that
satisfy the relation. [:hello, :world]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-25-320.jpg)
![Ordering clauses
run(q,
fresh {|a,b|
all(eq([a, :and, b], q),
eq(a, :something),
eq(:somethingelse, b)})
fresh can be used inside of a
query.
Order does not matter for
unification nor does the order of
clauses matter. [[:something, :and, :somethingelse]]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-26-320.jpg)

![rock paper scissors
run(q, beats(:rock, :paper))
beats fails because :rock does
not beat :paper. No value of q
makes this succeed.
[]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-28-320.jpg)
![rock paper scissors
run(q, beats(:paper, :rock))
beats succeeds because :paper
beats :rock. q remains fresh
because no questions were
asked of it.
["_.0"]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-29-320.jpg)
![rock paper scissors
core.logiccore.logic
beats can answer in either
direction.
[:scissors] [:rock]
run(q,
beats(:rock, q))
run(q,
beats(q, :scissors))](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-30-320.jpg)
![rock paper scissors
core.logic
winner, loser = fresh 2
run([winner, loser],
beats(winner, loser))This query asks for all the pairs
where winner beats loser.
[[:rock, :scissors],
[:scissors, :paper],
[:paper, :rock]]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-31-320.jpg)

![SPOCK CHAINS
core.logiccore.logic
run(q,
fresh{|m1, m2|
all(eq(q, [:spock, m1, m2, :spock]),
rpsls_beats(:spock, m1),
rpsls_beats(m1, m2),
rpsls_beats(m2, :spock))})
We can ask questions like: give
me a 4-chain of dominated
moves starting and ending
with :spock. There are three
solutions.
[[:spock, :rock, :lizard, :spock],
[:spock, :scissors, :paper, :spock],
[:spock, :scissors, :lizard, :spock]]](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-33-320.jpg)

![how many chains?
run(q,
all(eq(q, build_list([:spock] + fresh(10) +[:spock])),
chain(q))).length
How many winning chains are
there from :spock to :spock with
10 steps?
385](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-35-320.jpg)
![def edge(x,y)
edgefact = -> (x1, y1) {
all(eq(x,x1),eq(y,y1))
}
conde(edgefact[:g, :d],
edgefact[:g, :h],
edgefact[:e, :d],
edgefact[:h, :f],
edgefact[:e, :f],
edgefact[:a, :e],
edgefact[:a, :b],
edgefact[:b, :f],
edgefact[:b, :c],
edgefact[:f, :c])
end
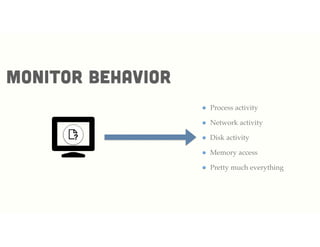
Path finding
D
A
E
B
G
H
F
C](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-36-320.jpg)
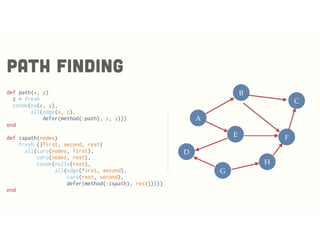



![Map coloring
core.logiccore.logic
http://pragprog.com/book/btlang/seven-languages-in-seven-weeks
(run 1 [q]
(fresh [tn ms al ga fl]
(everyg #(membero % [:red :blue :green])
[tn ms al ga fl])
(!= ms tn) (!= ms al) (!= al tn)
(!= al ga) (!= al fl) (!= ga fl) (!= ga tn)
(== q {:tennesse tn
:mississipi ms
:alabama al
:georgia ga
:florida fl})))
({:tennesse :blue,
:mississipi :red,
:alabama :green,
:georgia :red,
:florida :blue})](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-42-320.jpg)
![FINITE DOMAINS
core.logiccore.logic
fd/interval declares a finite
integer interval and fd/in
contrains logic variables to a
domain.
(defn two-plus-two-is-four [q]
(fresh [t w o f u r TWO FOUR]
(fd/in t w o f u r (fd/interval 0 9))
(fd/distinct [t w o f u r])
(fd/in TWO (fd/interval 100 999))
(fd/in FOUR (fd/interval 1000 9999))
...
(== q [TWO TWO FOUR])))
T W O
+ T W O
-------
F O U R
http://www.amazon.com/Crypt-arithmetic-Puzzles-in-PROLOG-ebook/dp/B006X9LY8O](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-43-320.jpg)

![FINITE DOMAINS
core.logiccore.logic
There are 7 unique solutions to
the problem.
(run* [q]
(two-plus-two-is-four q))
T W O
+ T W O
-------
F O U R
([734 734 1468]
[765 765 1530]
[836 836 1672]
[846 846 1692]
[867 867 1734]
[928 928 1856]
[938 938 1876])](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-45-320.jpg)

![USEless logic puzzle
core.logiccore.logic
(defn pigso [q]
(fresh [h1 h2 h3 t1 t2 t3]
(== q [[:petey h1 t1]
[:pippin h2 t2]
[:petunia h3 t3]])
(permuteo [t1 t2 t3]
[:chocolate :popcorn :apple])
(permuteo [h1 h2 h3]
[:wood :straw :brick])
... ))
pigso starts by defining the
solution space.
permuteo succeeds when the
first list is permutation of the
second.](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-47-320.jpg)
![USEless logic puzzle
core.logiccore.logic
(fresh [notpopcorn _]
(!= notpopcorn :popcorn)
(membero [:petey _ notpopcorn] q))
(fresh [notwood _]
(!= notwood :wood)
(membero [:pippin notwood _] q))
(fresh [_]
(membero [_ :straw :popcorn] q))
(fresh [_]
(membero [:petunia _ :apple] q))
(fresh [notbrick _]
(!= notbrick :brick)
(membero [_ notbrick :chocolate] q))
The clues translate cleanly to
goals constraining the solution
space.
membero has a solution when
the first item is a member of the
second.](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-48-320.jpg)
![FACTS and RELATIONS
core.logiccore.logic
(run* [q]
(pigso q))
pigso finds the only solution.
([[:petey :wood :chocolate]
[:pippin :straw :popcorn]
[:petunia :brick :apple]])](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-49-320.jpg)
![sudoku made easier
core.logic
After setting up the logic
variables and initializing state,
the solution simply requires every
row, column and square on the
board to have distinct values.
(defn solve [puzzle]
(let [sd-num (fd/domain 1 2 3 4 5 6 7 8 9)
board (repeatedly 81 lvar)
rows (into [] (map vec (partition 9 board)))
cols (apply map vector rows)
squares (for [x (range 0 9 3)
y (range 0 9 3)]
(get-square rows x y))]
(run* [q]
(== q board)
(everyg #(fd/in % sd-num) board)
(init-board board puzzle)
(everyg fd/distinct rows)
(everyg fd/distinct cols)
(everyg fd/distinct squares))))
https://gist.github.com/swannodette/3217582](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-50-320.jpg)
![sudoku
core.logiccore.logic
(def puzzle1
[0 0 0 0 0 9 0 6 0
0 3 8 0 0 5 0 0 4
0 2 0 0 6 0 0 7 0
0 0 0 0 0 0 3 9 0
0 0 0 9 2 6 0 0 0
0 9 7 0 0 0 0 0 0
0 4 0 0 7 0 0 3 0
5 0 0 4 0 0 2 1 0
0 7 0 8 0 0 0 0 0])
(partition 9 (first (solve puzzle1)))
((7 1 4 2 8 9 5 6 3)
(6 3 8 7 1 5 9 2 4)
(9 2 5 3 6 4 1 7 8)
(8 6 1 5 4 7 3 9 2)
(4 5 3 9 2 6 7 8 1)
(2 9 7 1 3 8 4 5 6)
(1 4 9 6 7 2 8 3 5)
(5 8 6 4 9 3 2 1 7)
(3 7 2 8 5 1 6 4 9))](https://image.slidesharecdn.com/logicprogrammingarubyperspective-150406185813-conversion-gate01/85/Logic-programming-a-ruby-perspective-51-320.jpg)

The document explores logic programming from a Ruby perspective, discussing libraries like core.logic for malware analysis and minikanren for relational programming. It demonstrates various logic programming techniques through code examples, including querying, relationships, and puzzles like Rock Paper Scissors and Sudoku. Overall, it emphasizes the power of logic programming in creating declarative queries and abstract problem-solving in real-world applications.














































![[ABDO] Logic As A Database Language](https://cdn.slidesharecdn.com/ss_thumbnails/logicasadblanguage-1232531111014566-3-thumbnail.jpg?width=640&height=640&fit=bounds)



























