Downloaded 33 times



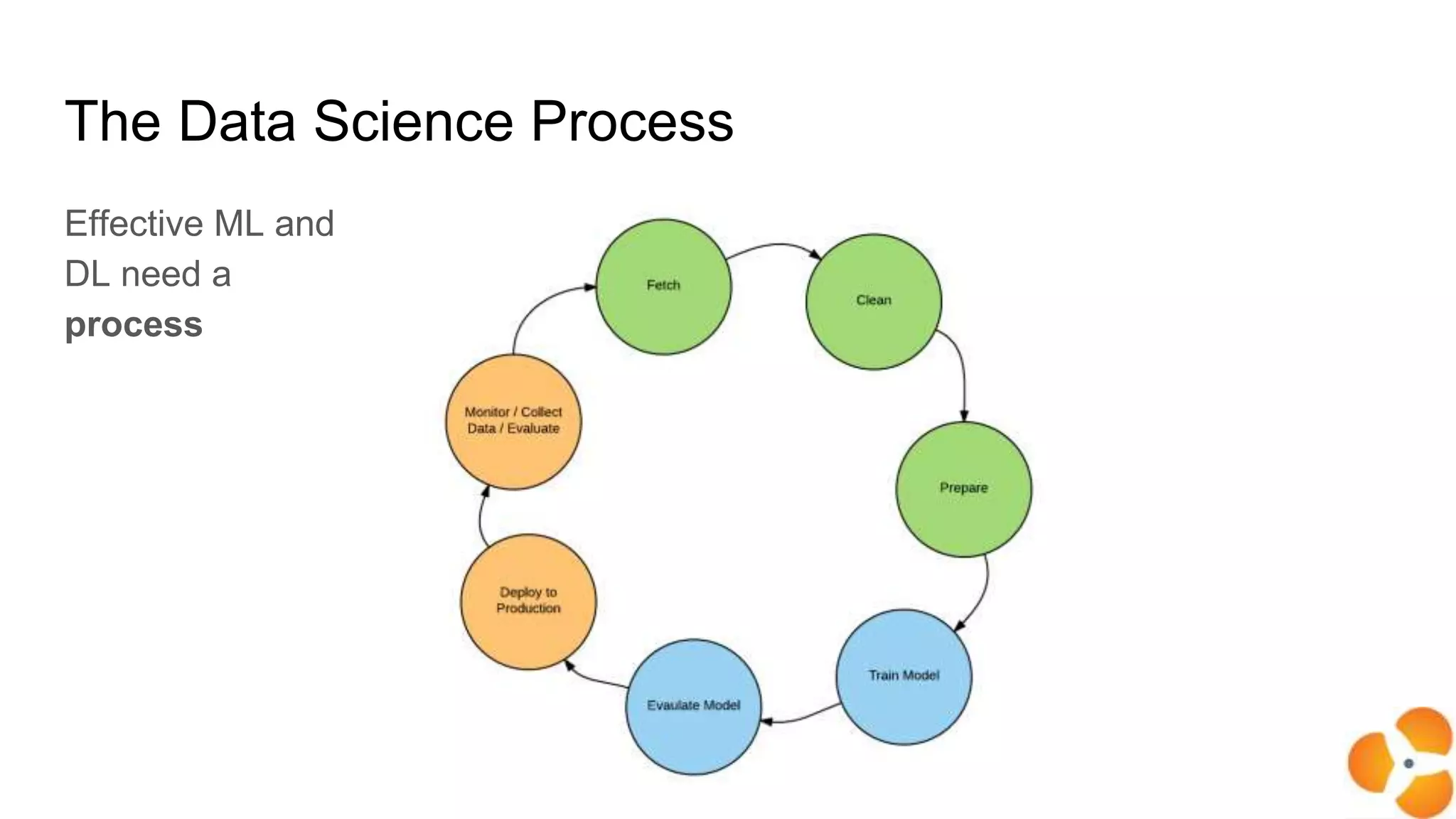
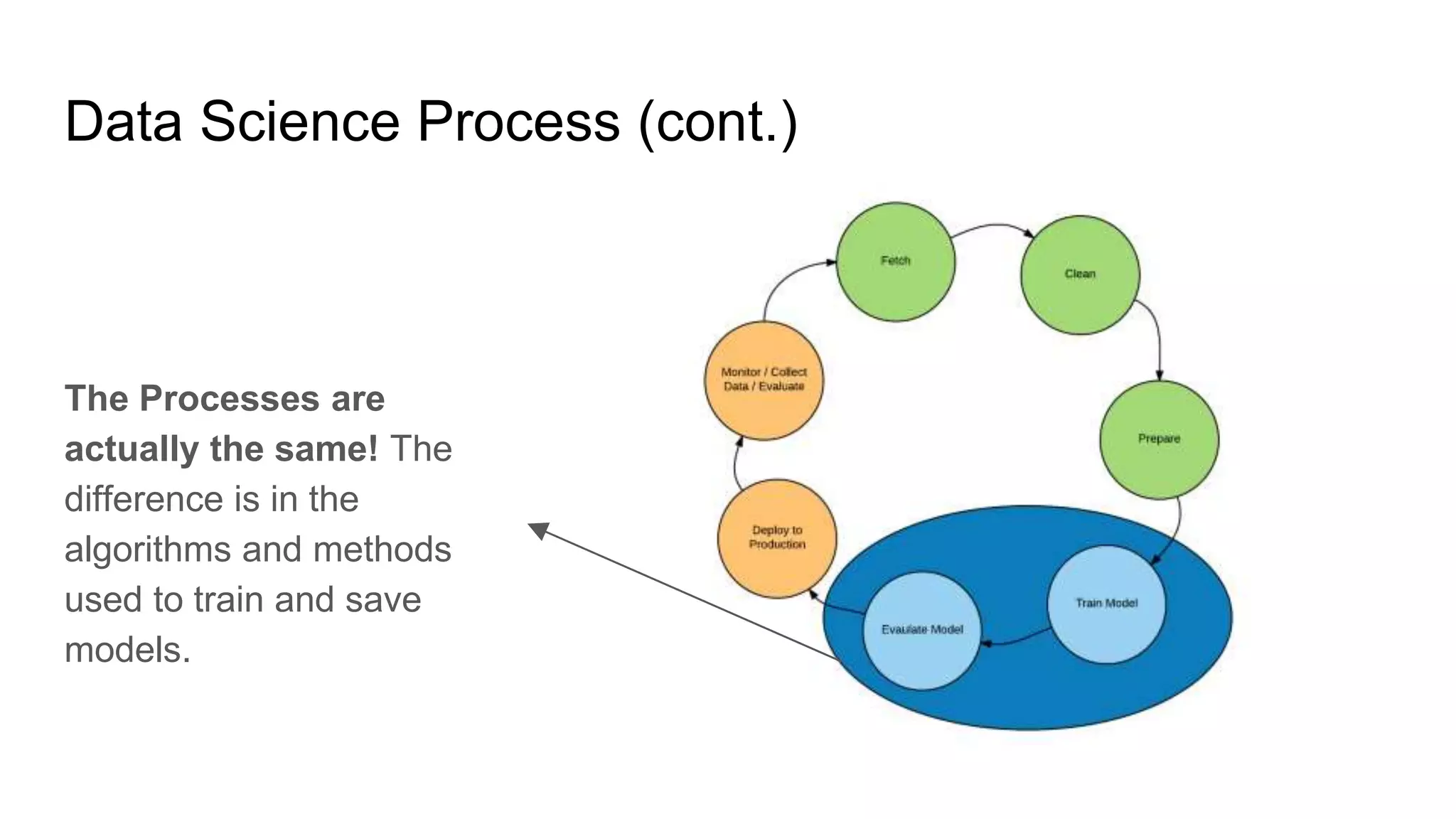
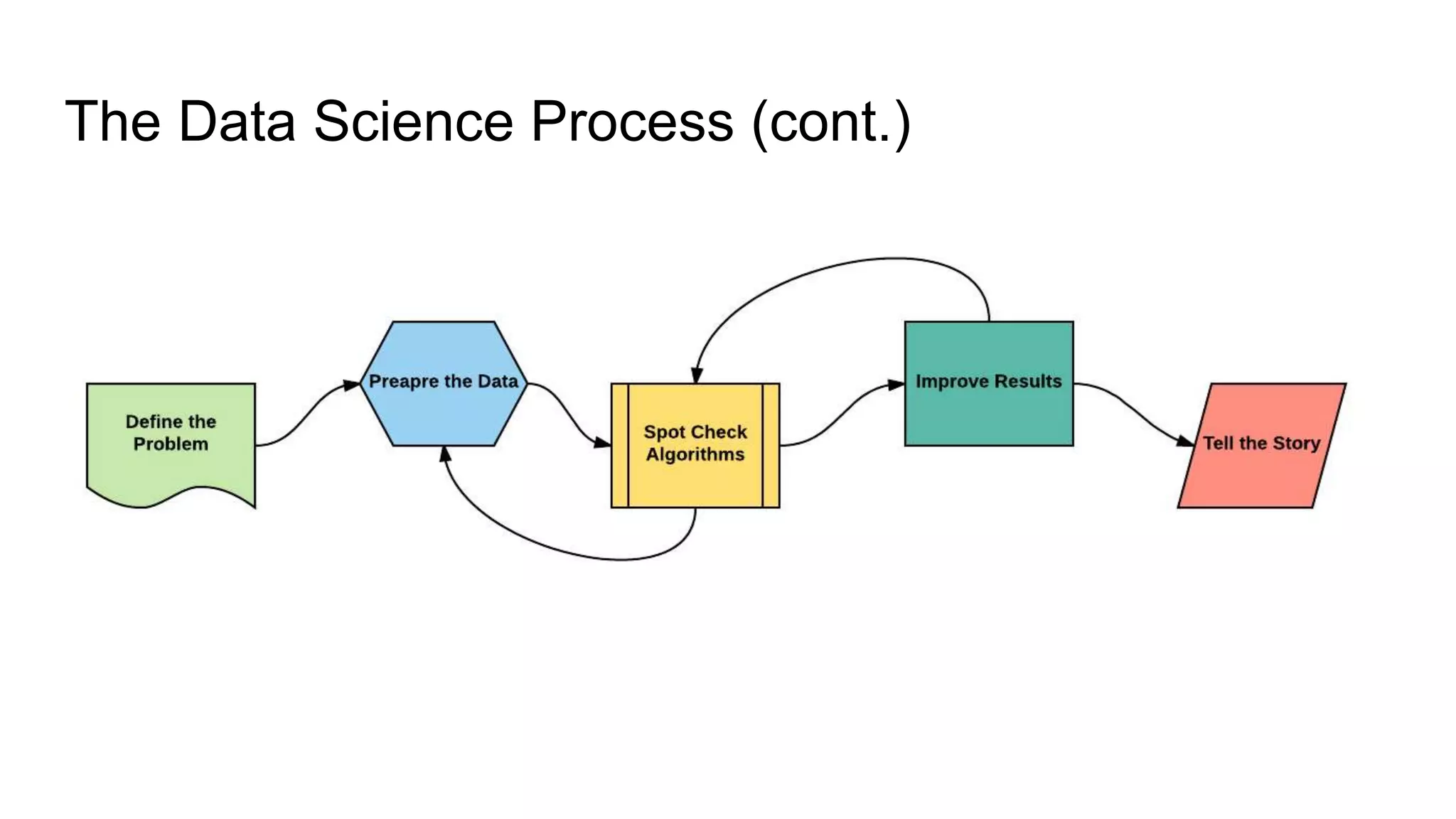
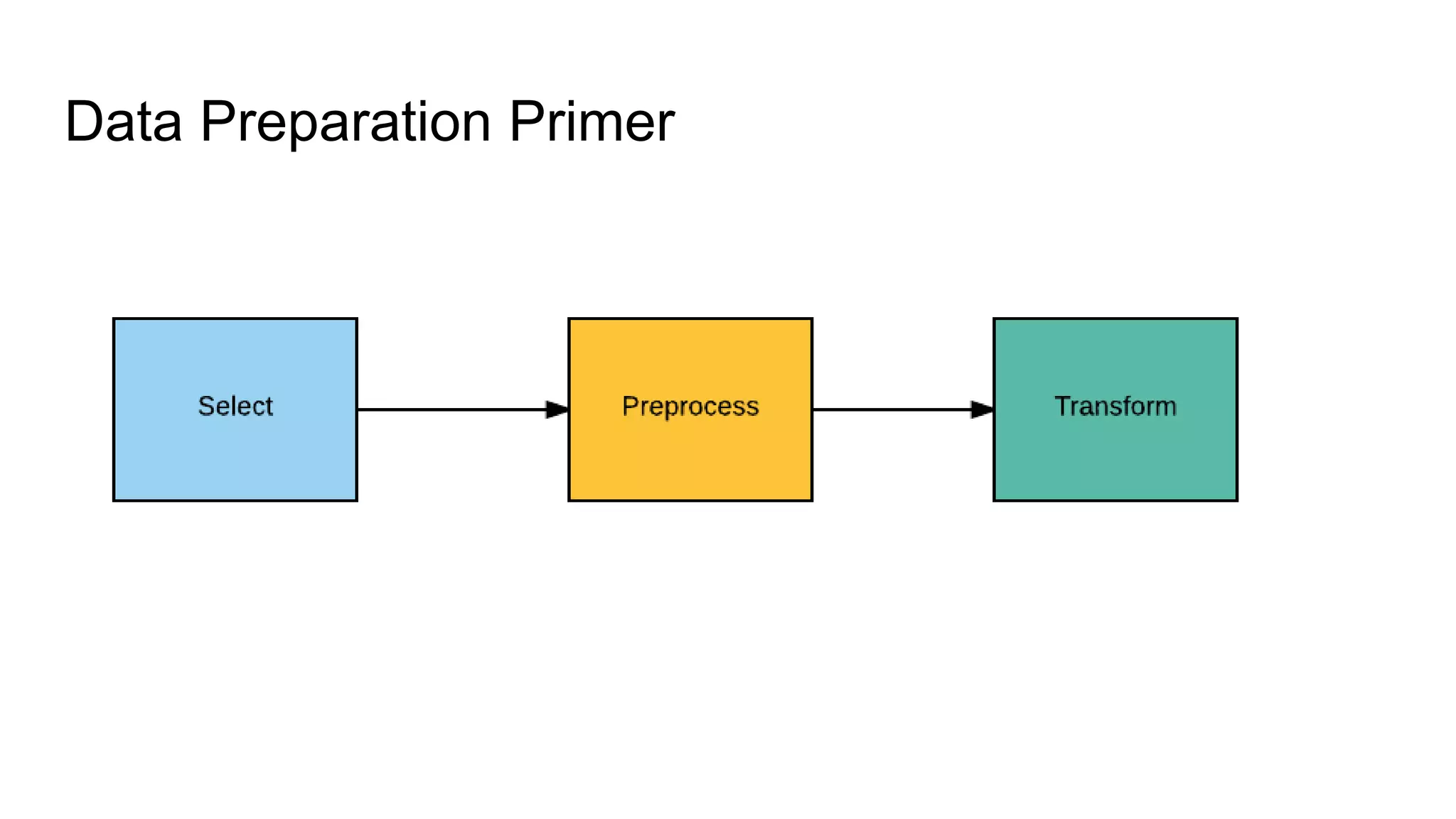
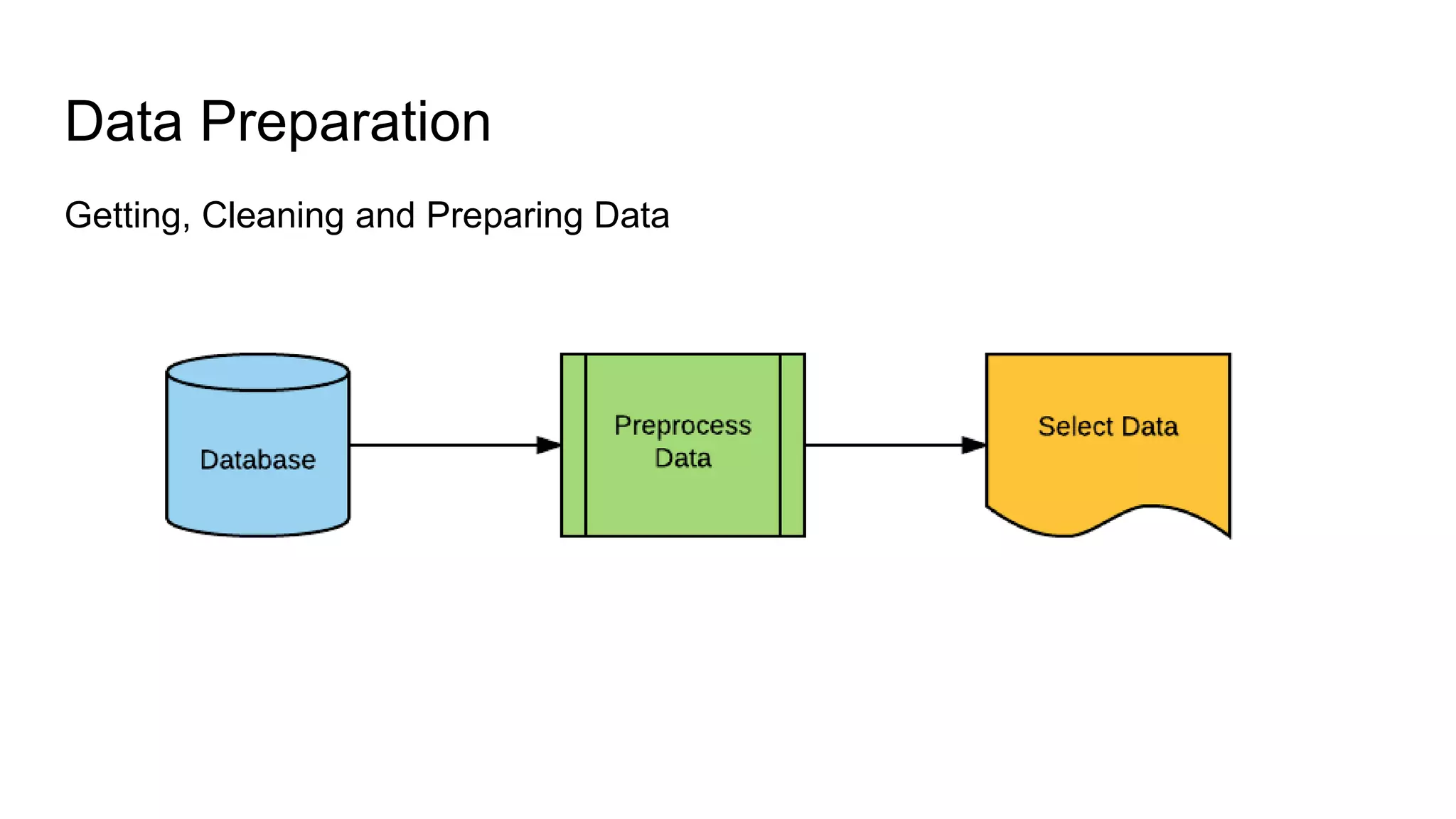
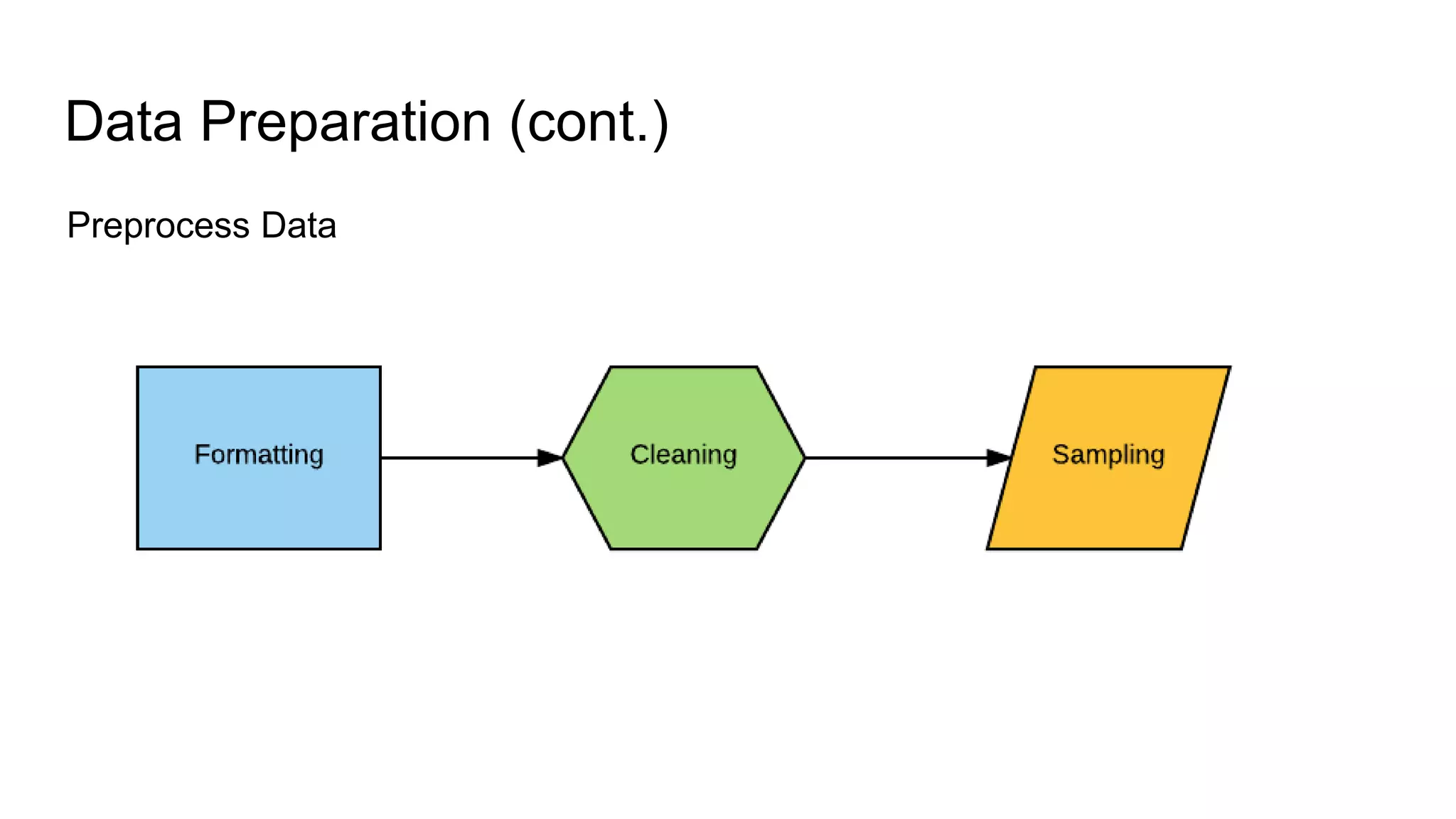
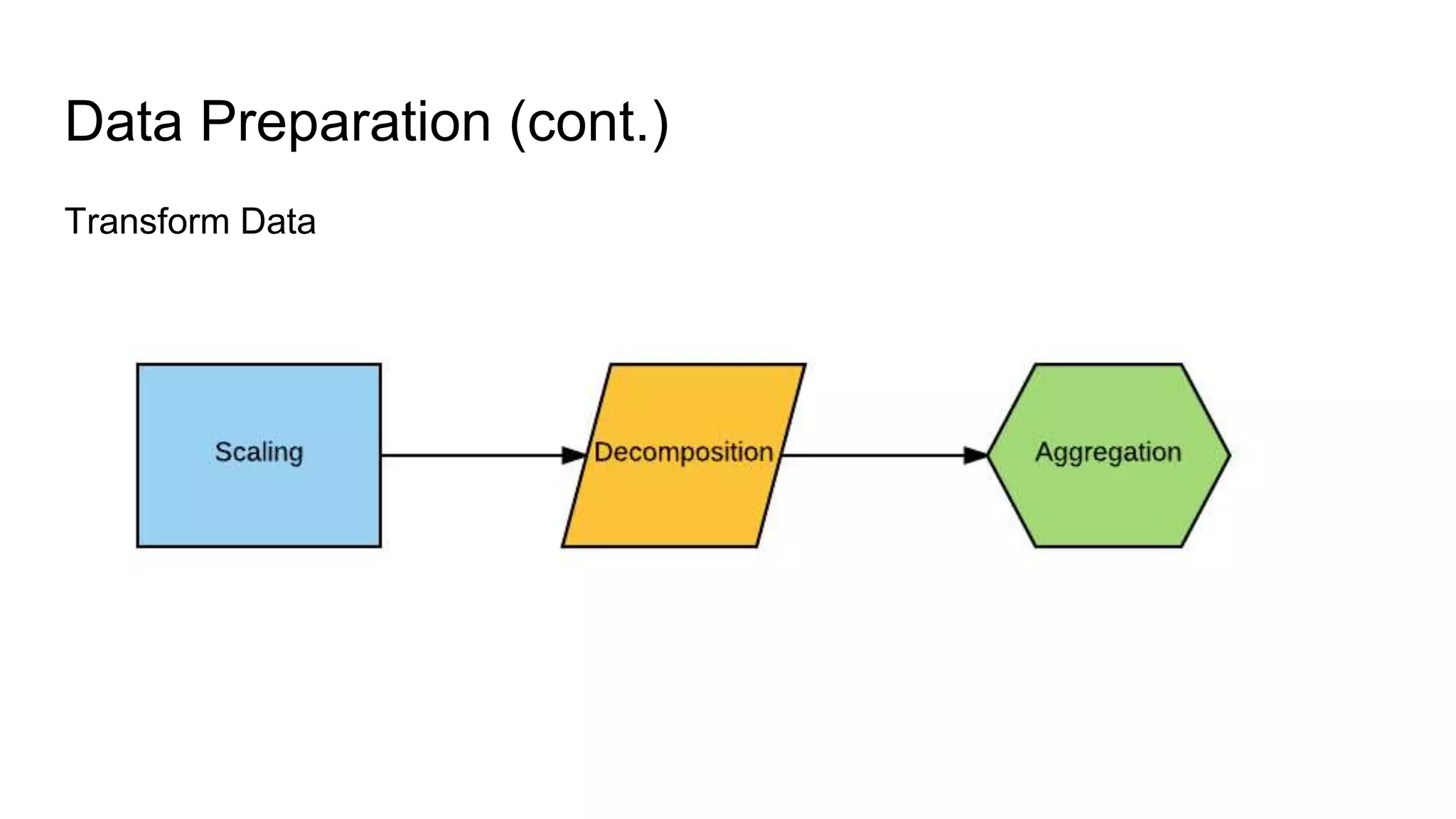
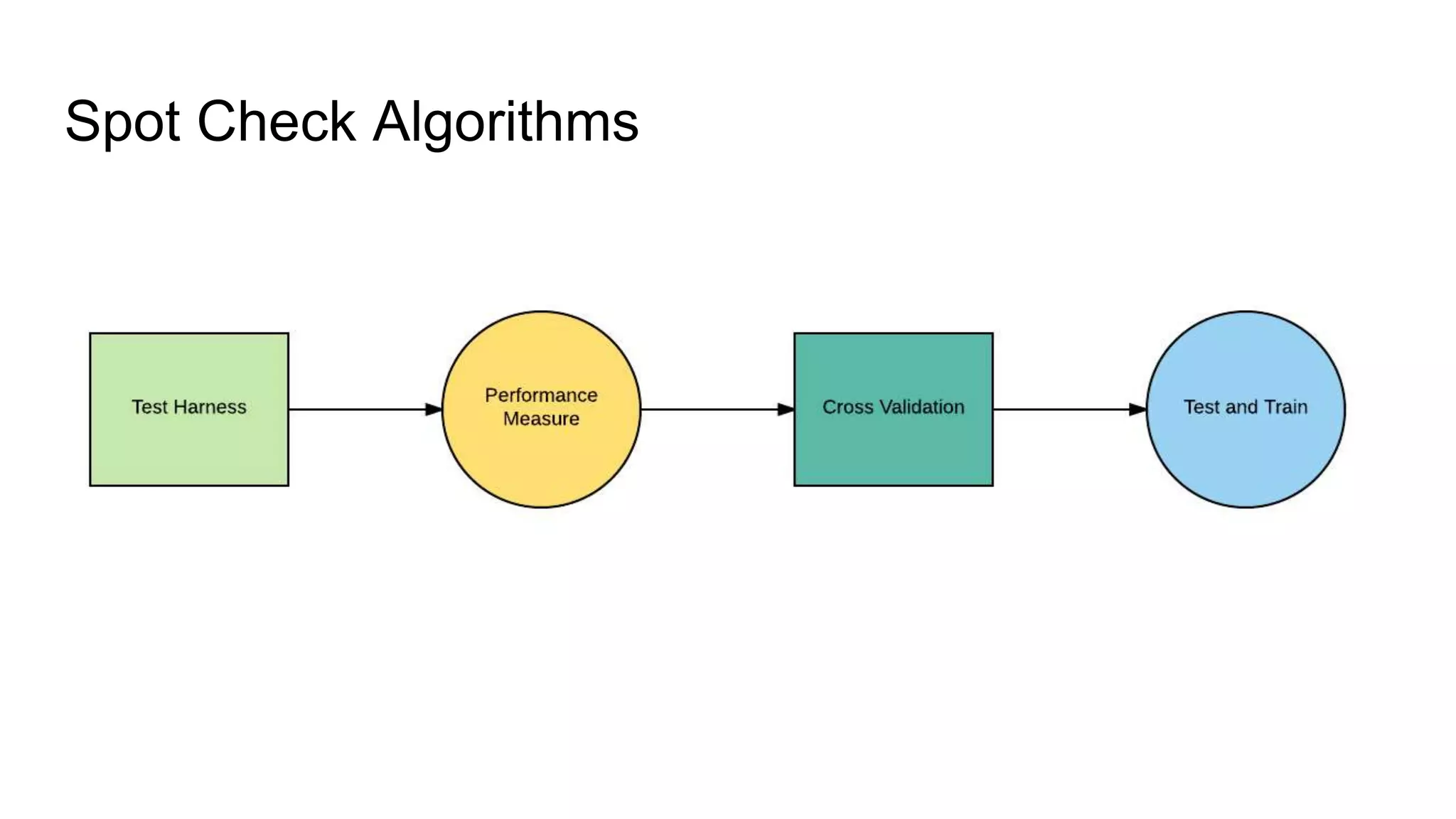
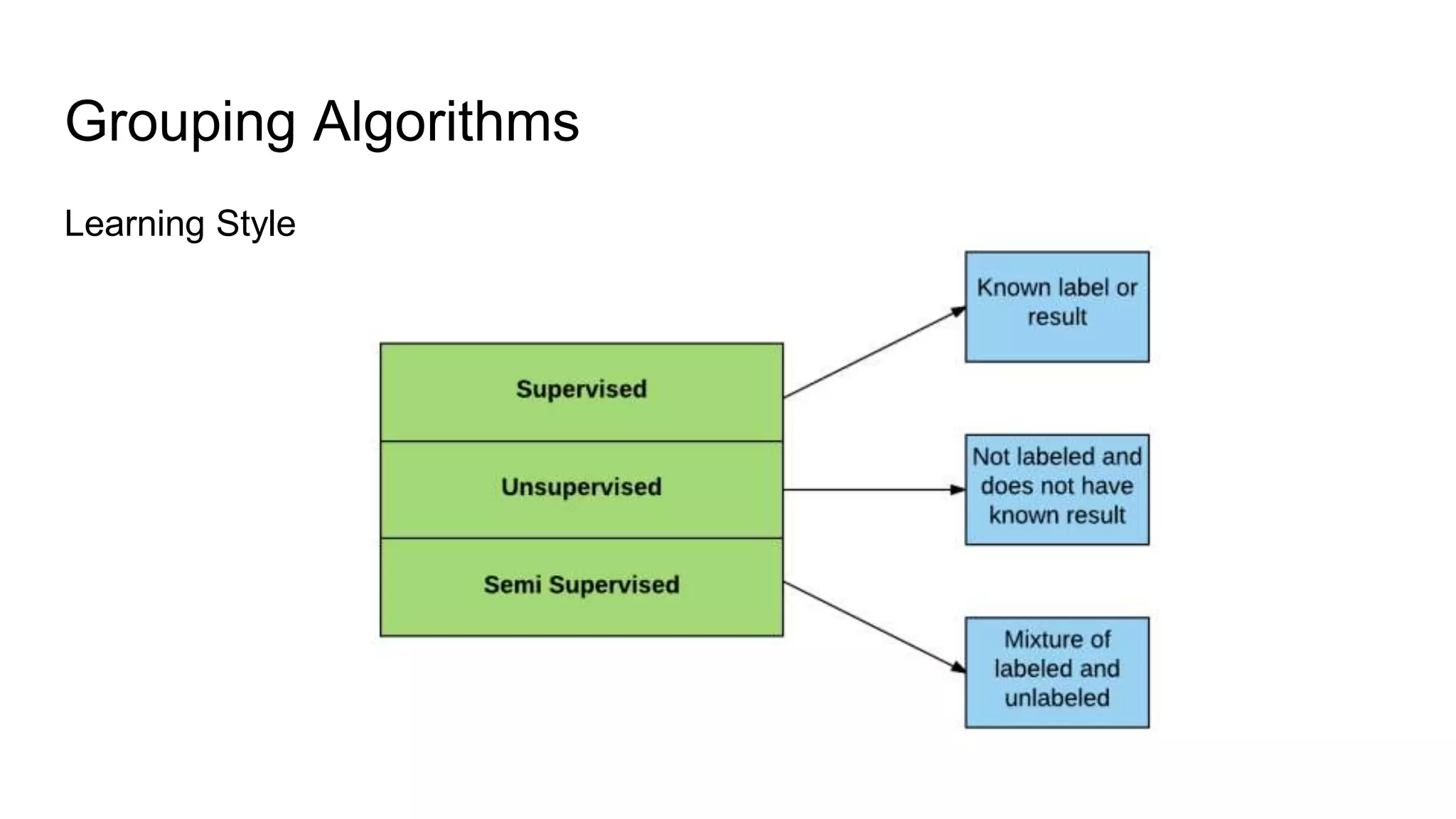

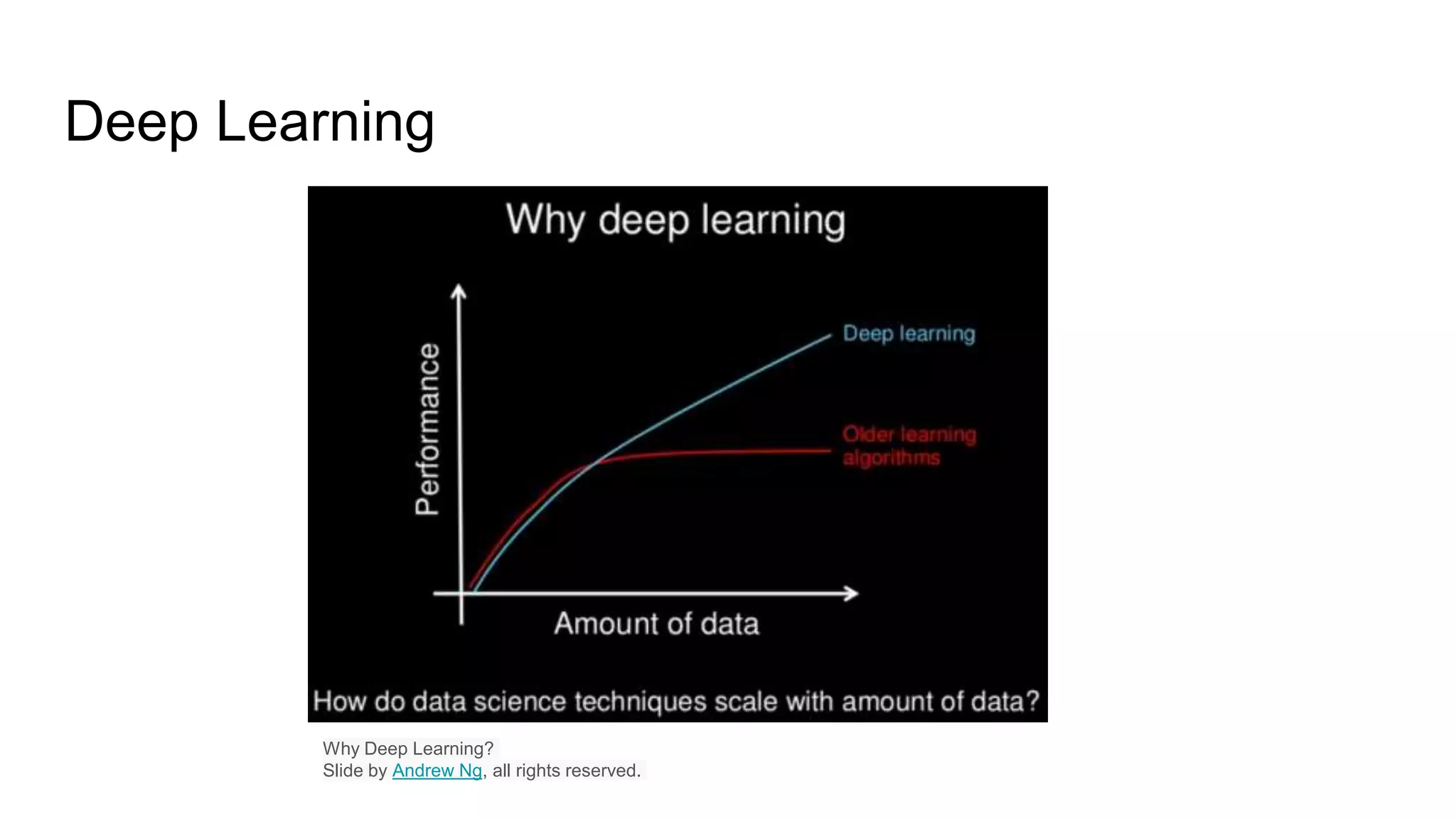

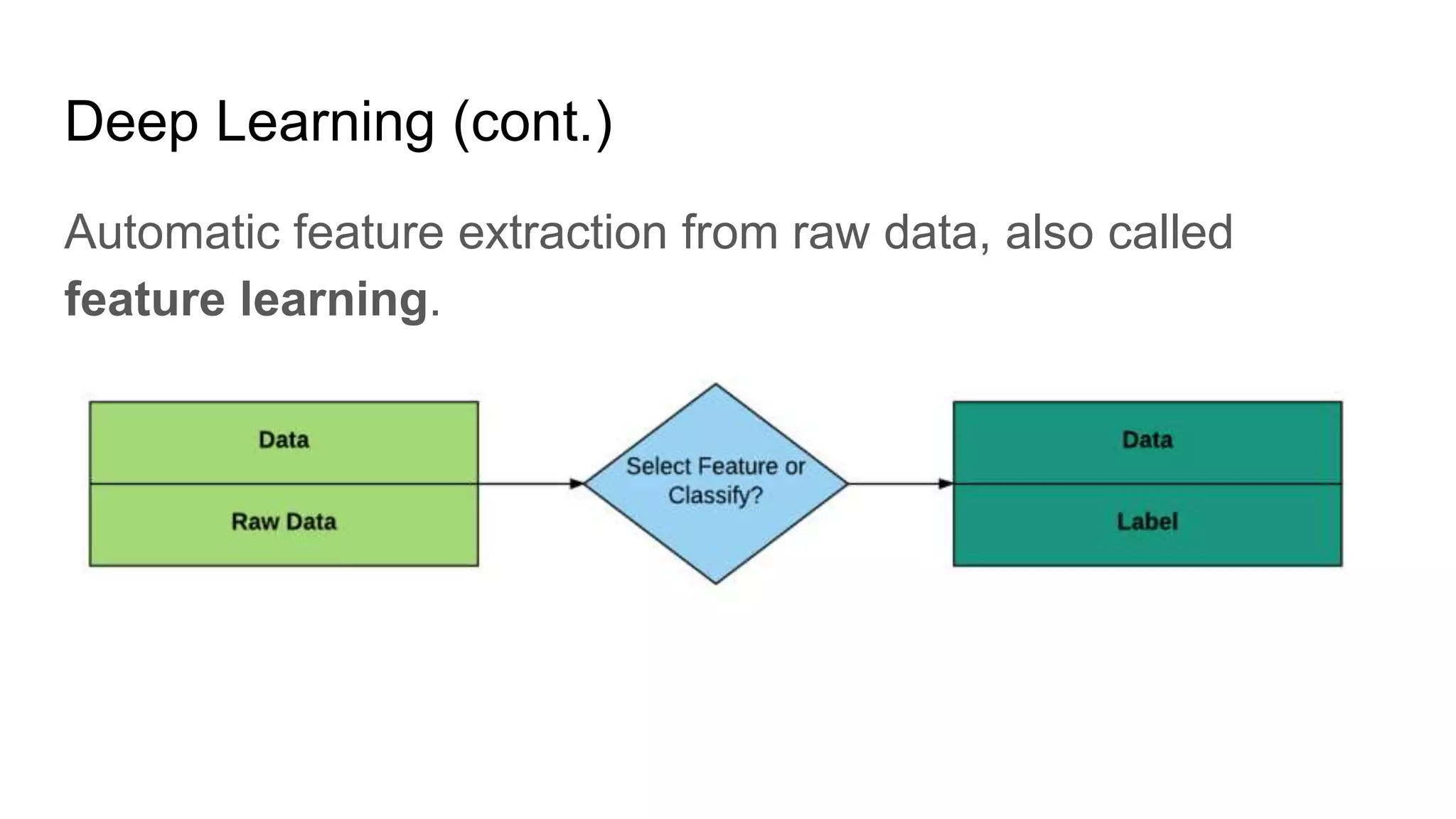
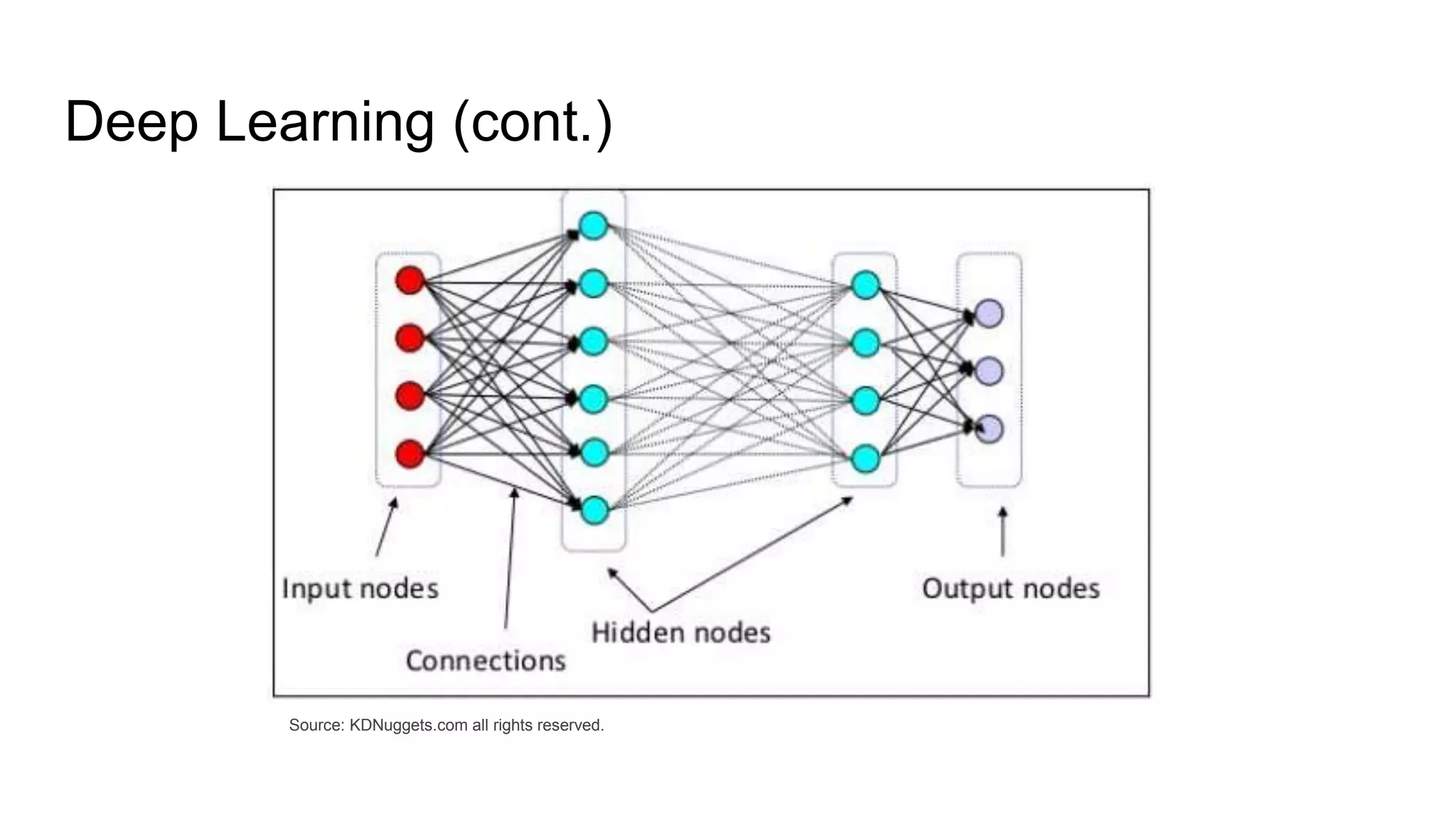




The document presents a guide distinguishing between machine learning (ML), deep learning (DL), and artificial intelligence (AI) while covering goals, use cases, and the data science process. It emphasizes that ML and DL are related with DL primarily used for supervised learning and focuses on the importance of data preparation and optimization techniques. Additionally, it highlights the necessity of automating the ML/DL pipeline and provides resources for further engagement.


















































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)












![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)