Download as PDF, PPTX


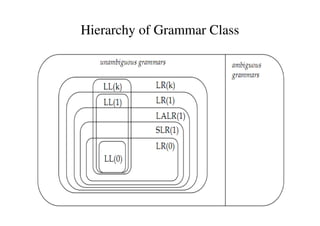







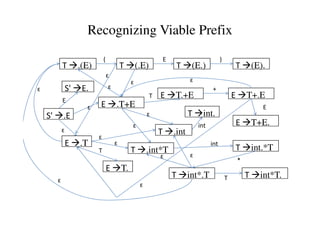
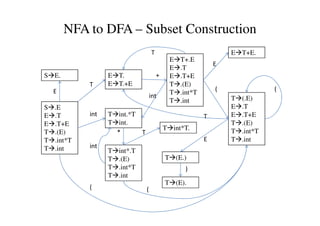


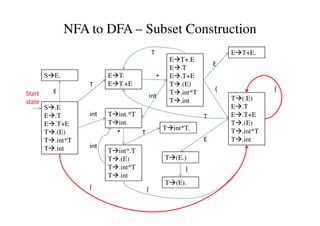


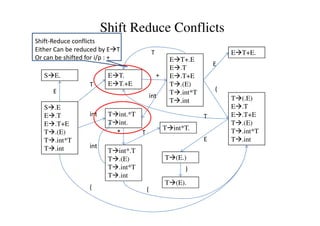



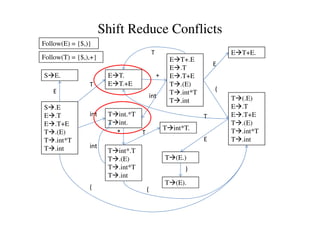



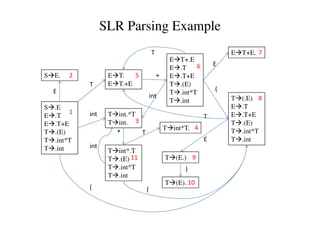



This document discusses bottom-up parsing and LR(0) parsing. It describes viable prefixes, LR(0) items, and how they are used to build an automaton that recognizes viable prefixes of a grammar. This automaton undergoes subset construction to determinize it, resulting in a DFA. SLR parsing improves on LR(0) by adding heuristics to resolve shift-reduce conflicts. An example SLR parsing of the string "int * int$" is provided to illustrate the algorithm.




































































































