Downloaded 26 times

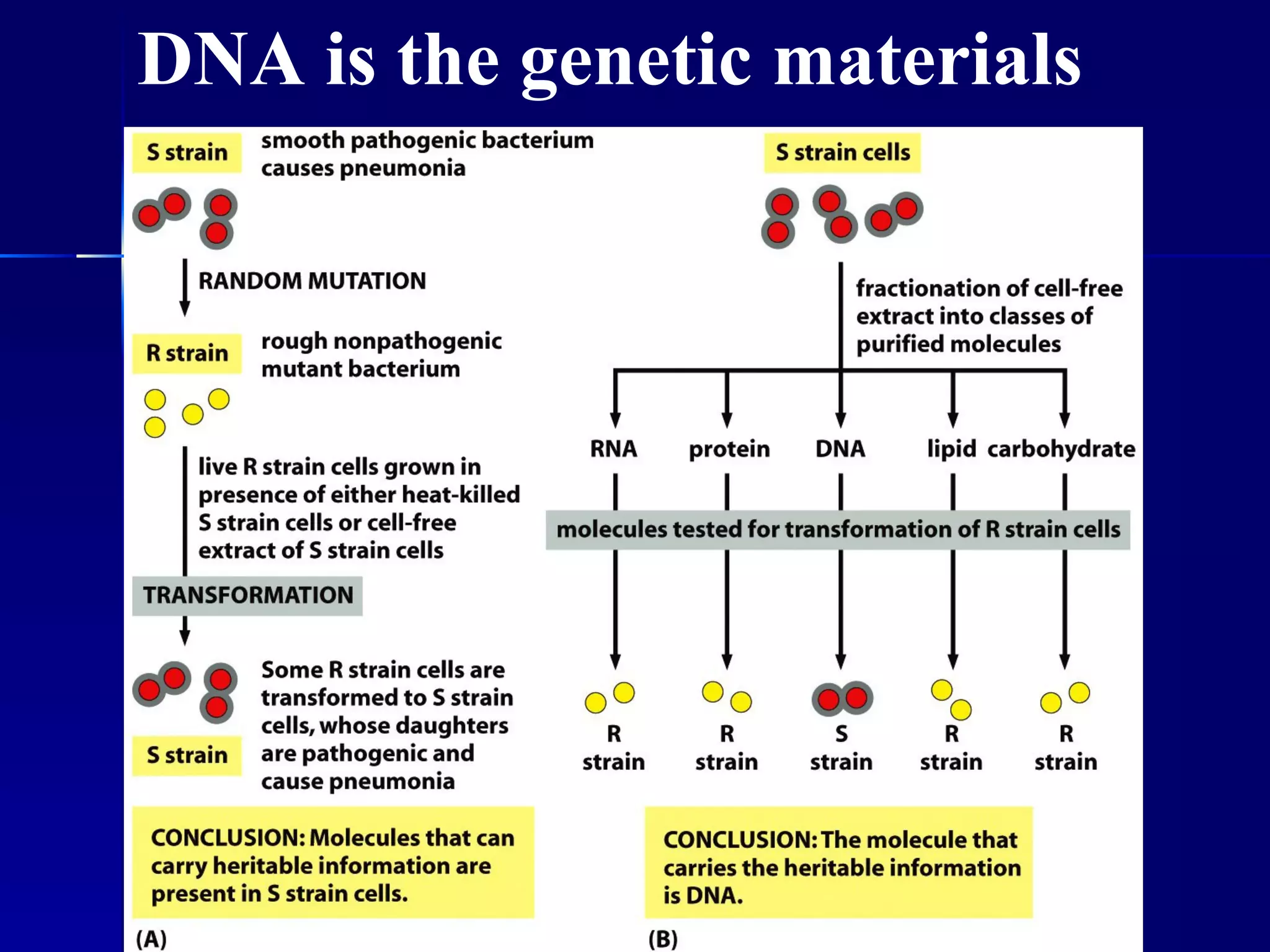
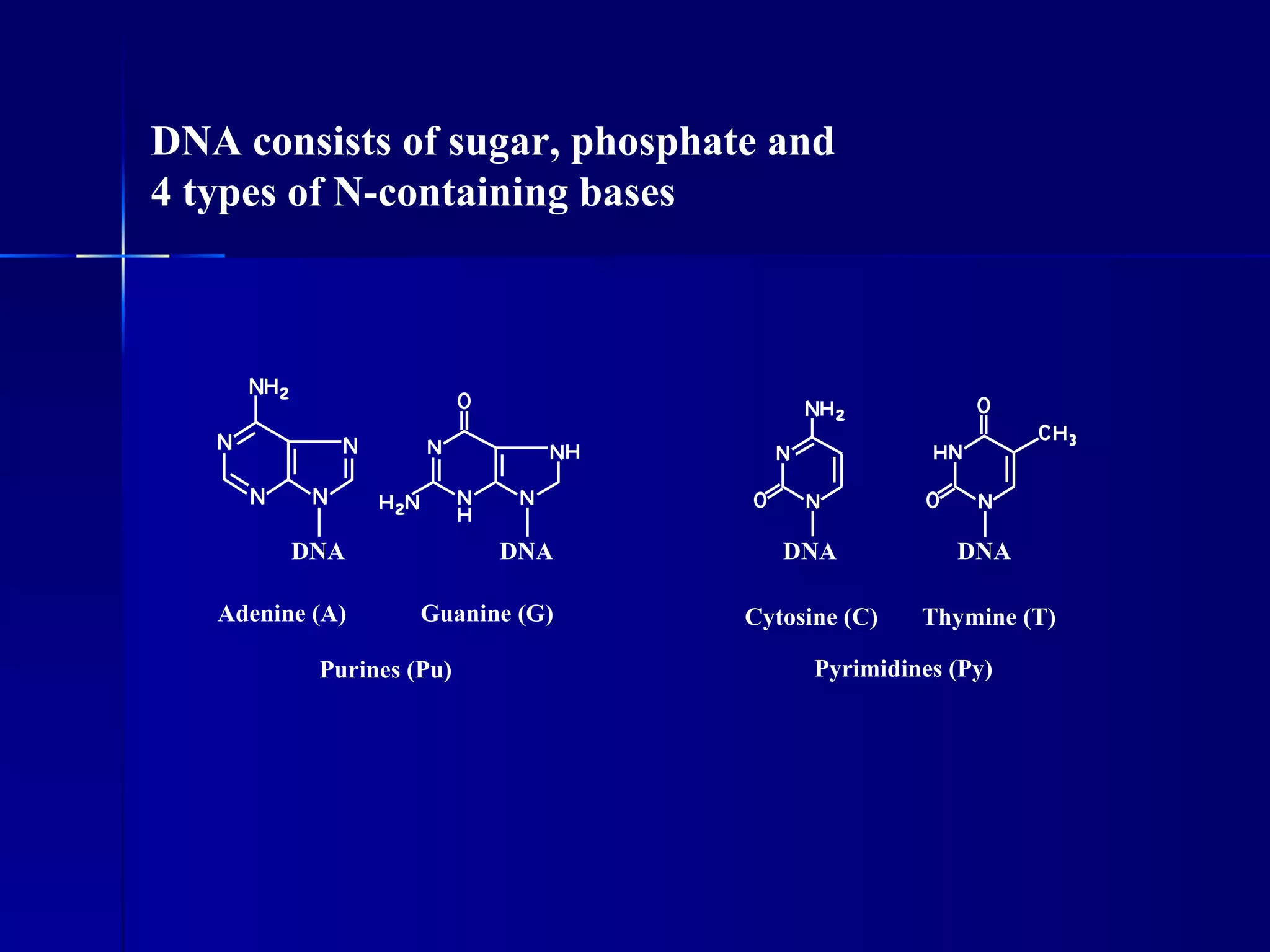
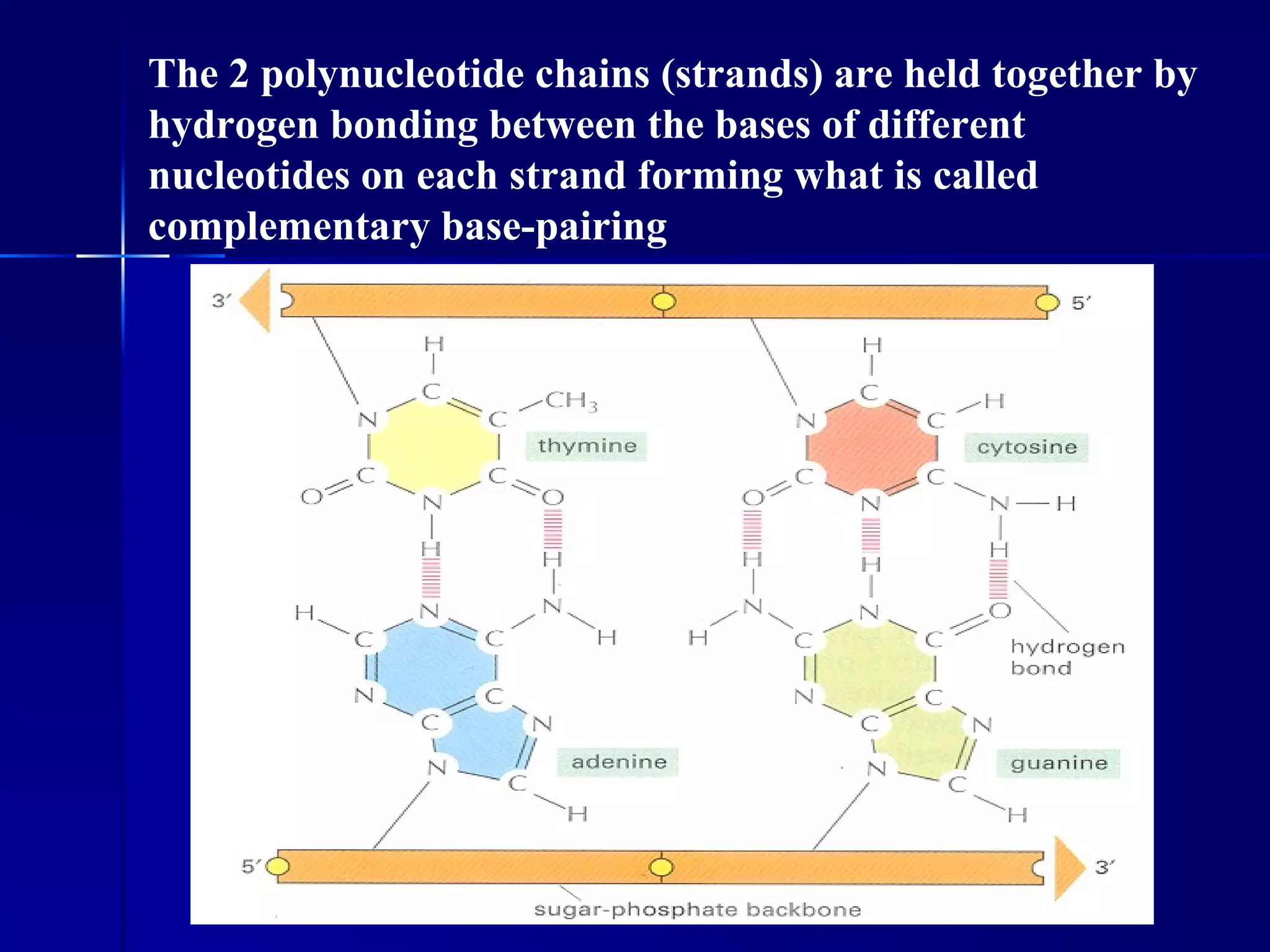
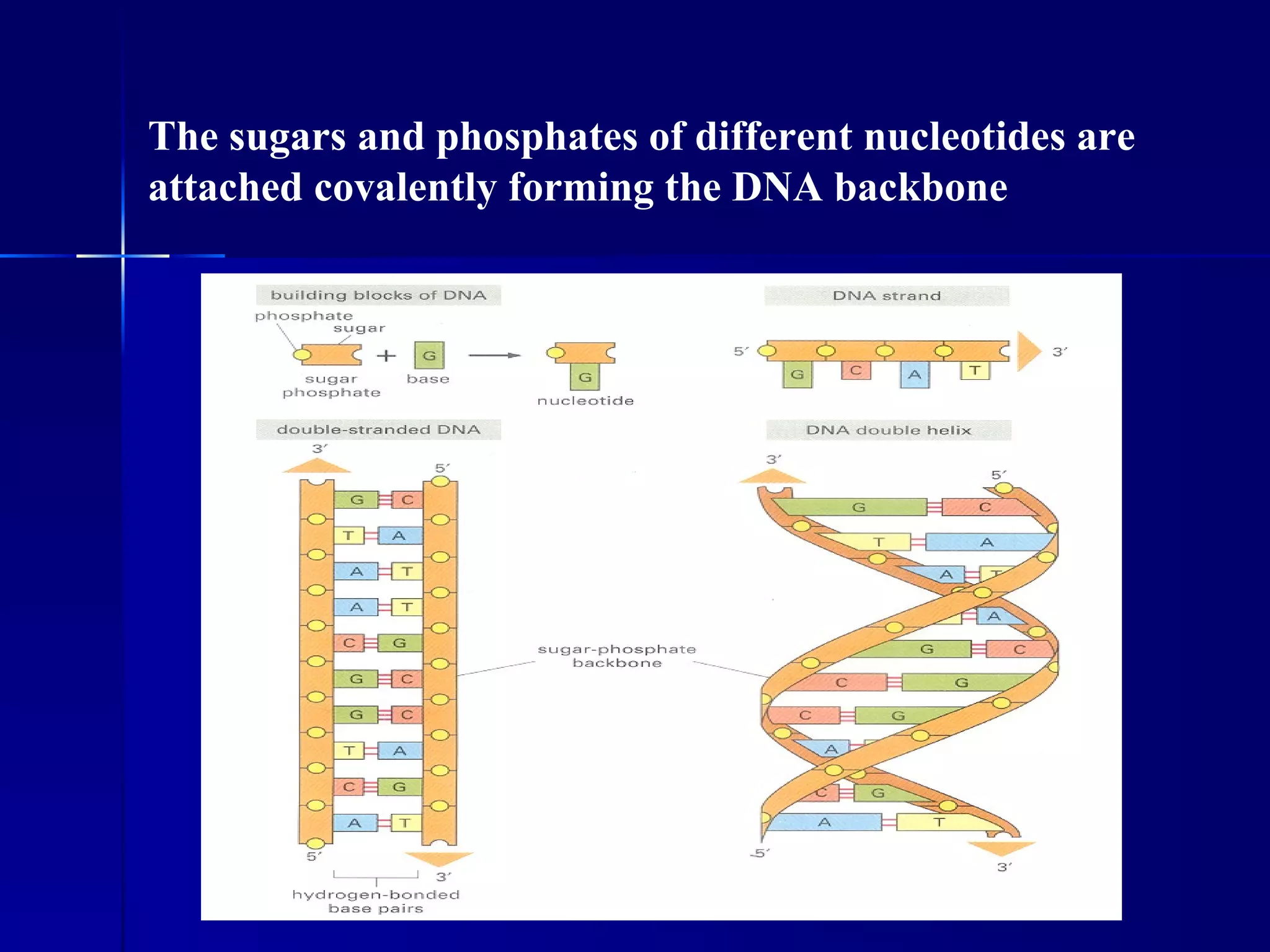
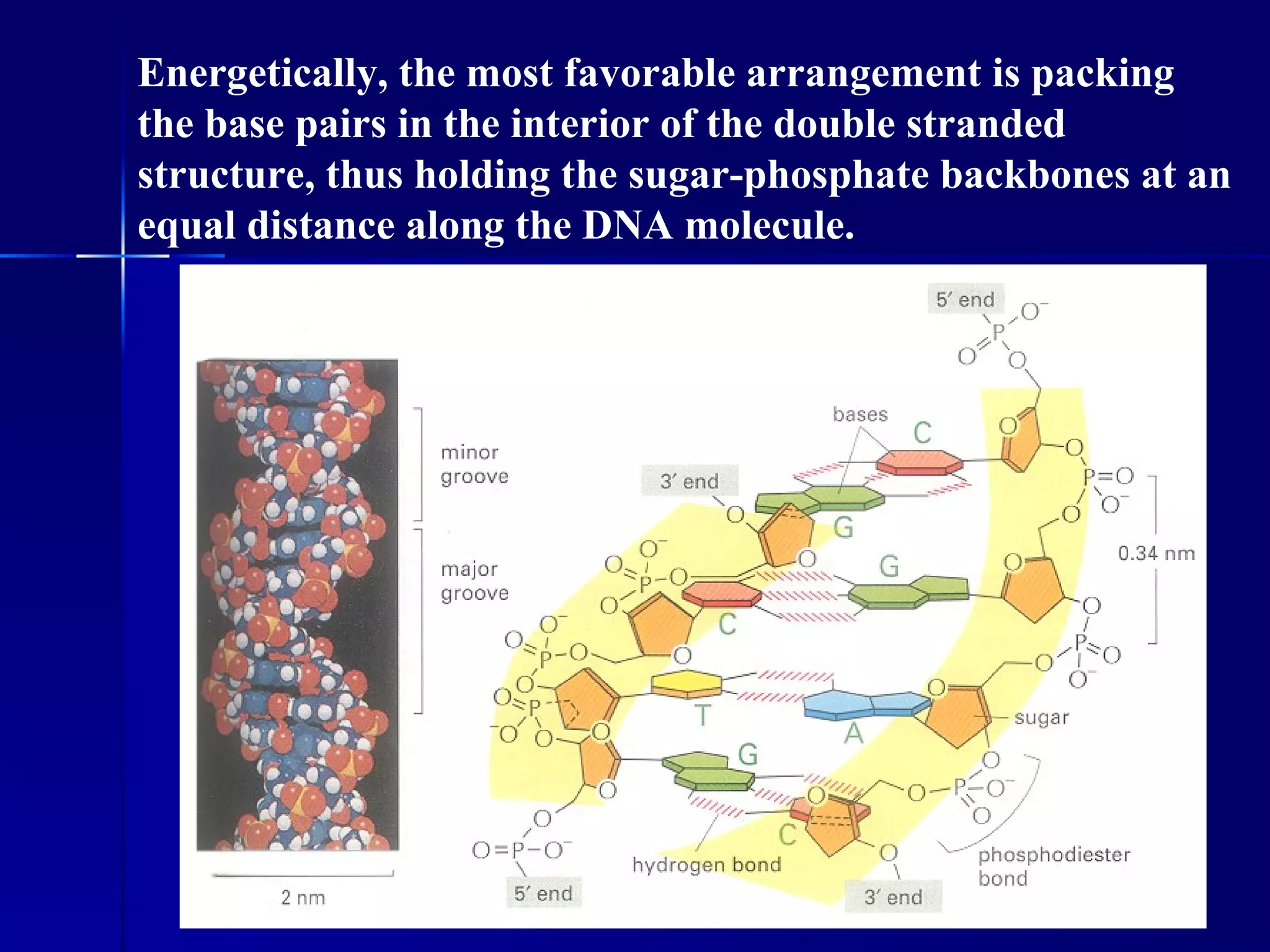

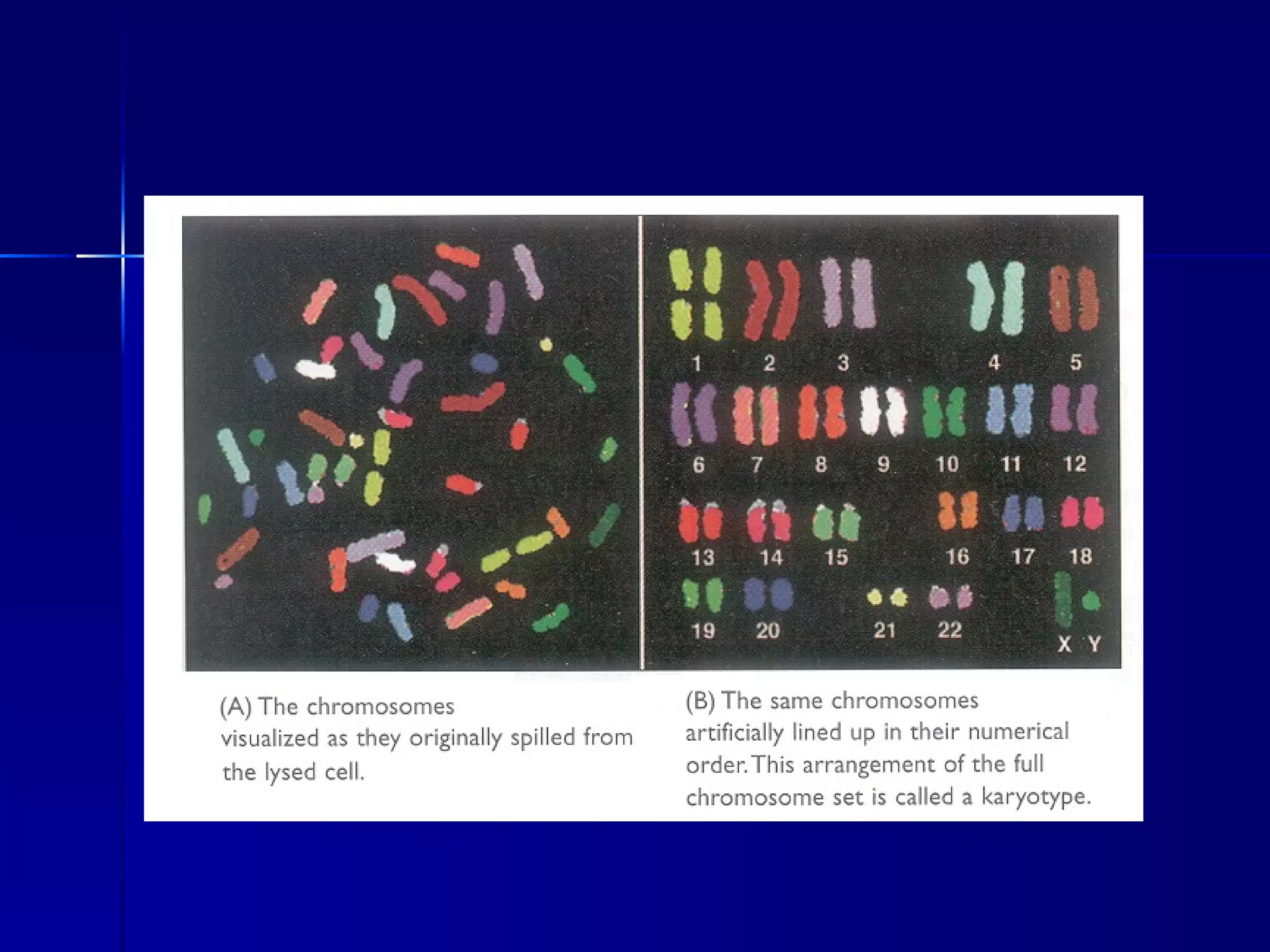
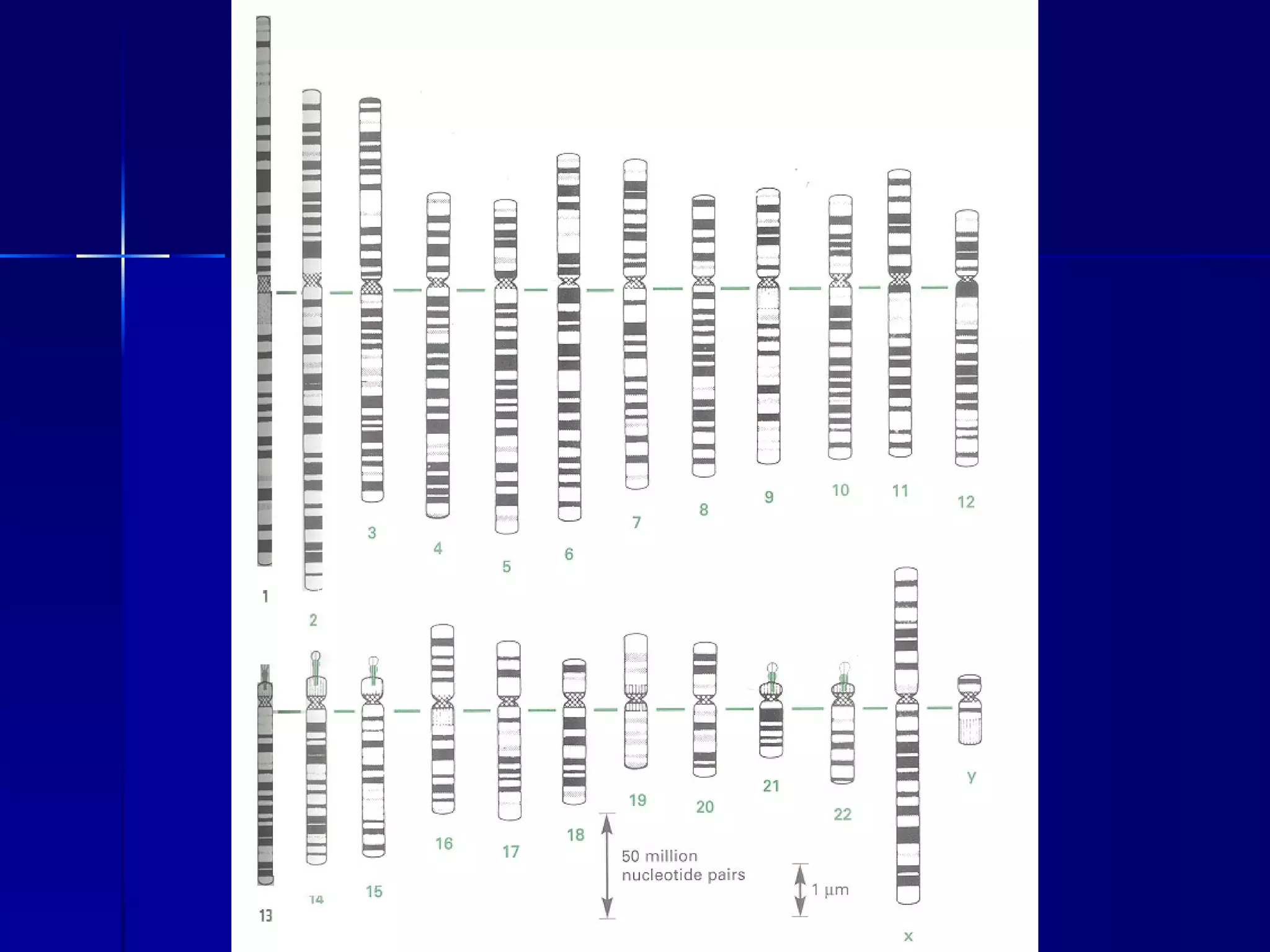

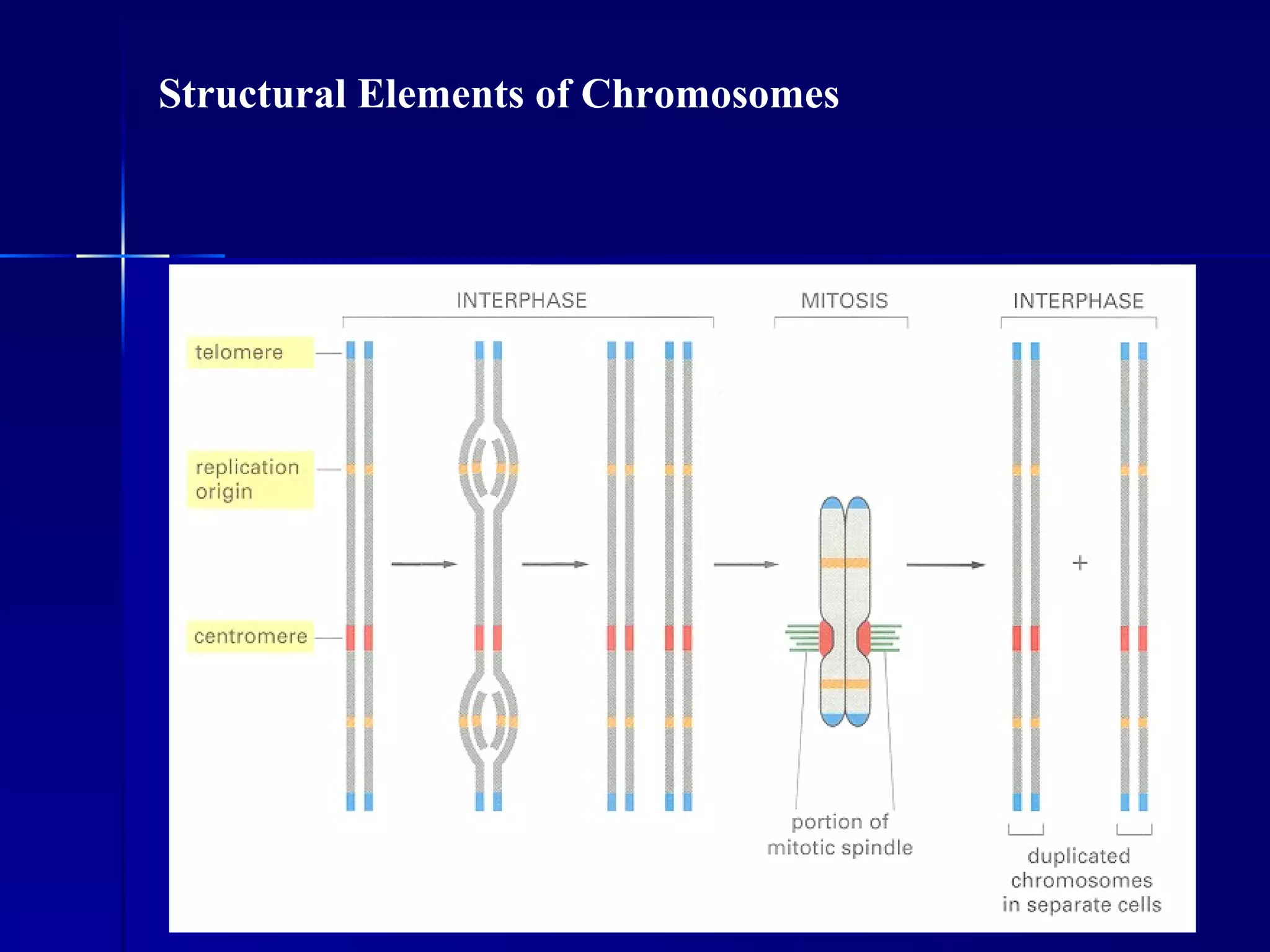

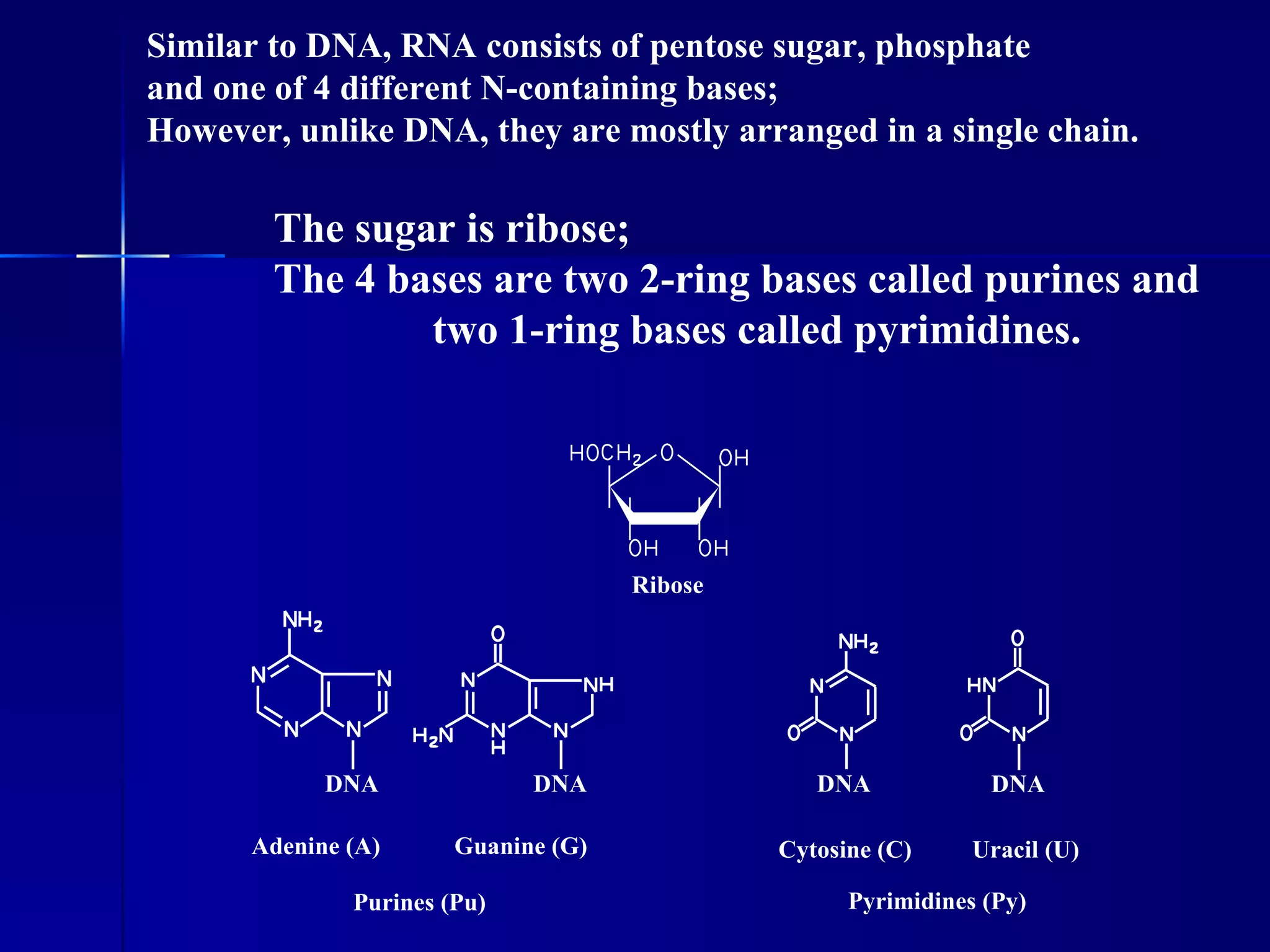
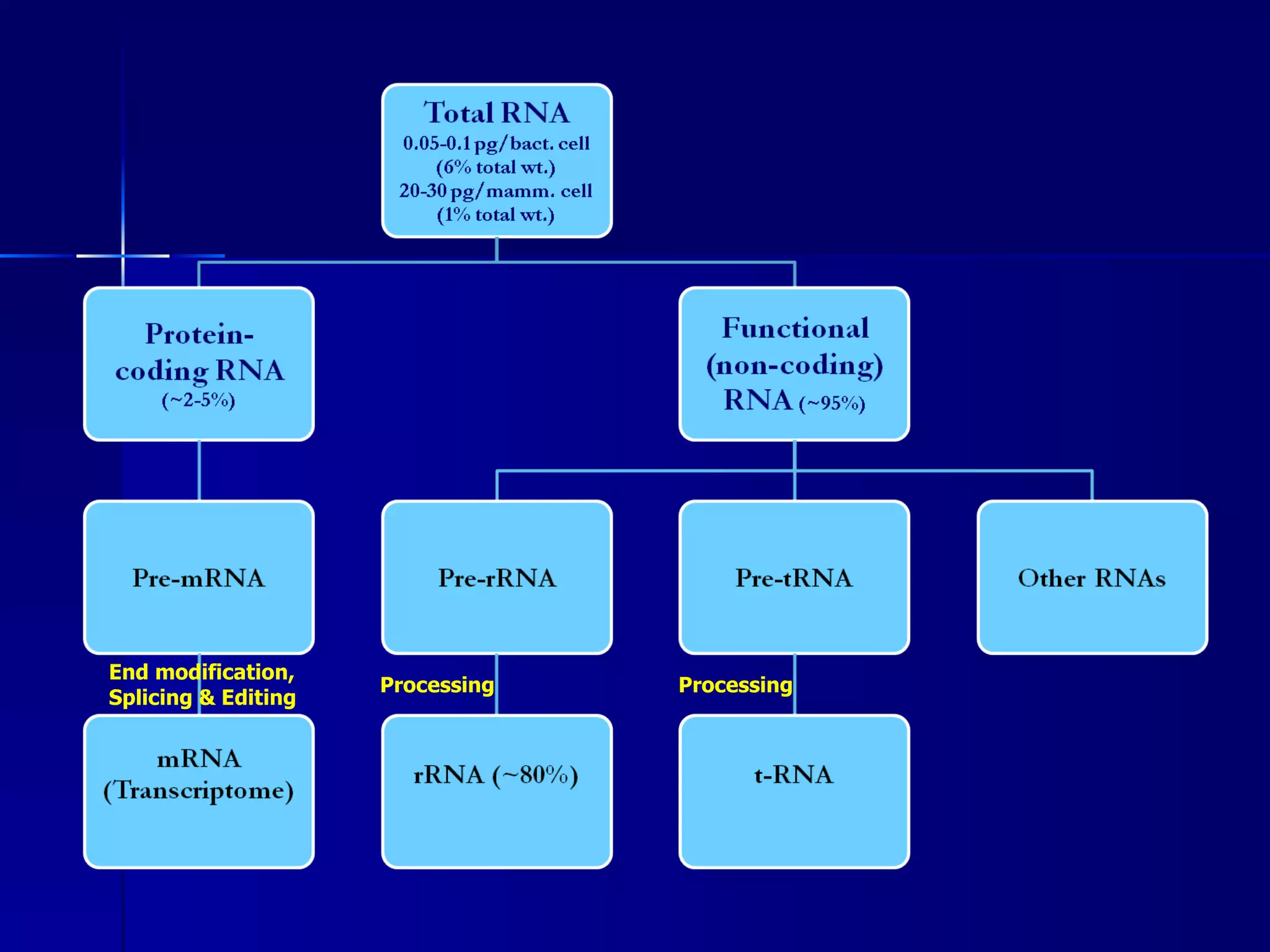









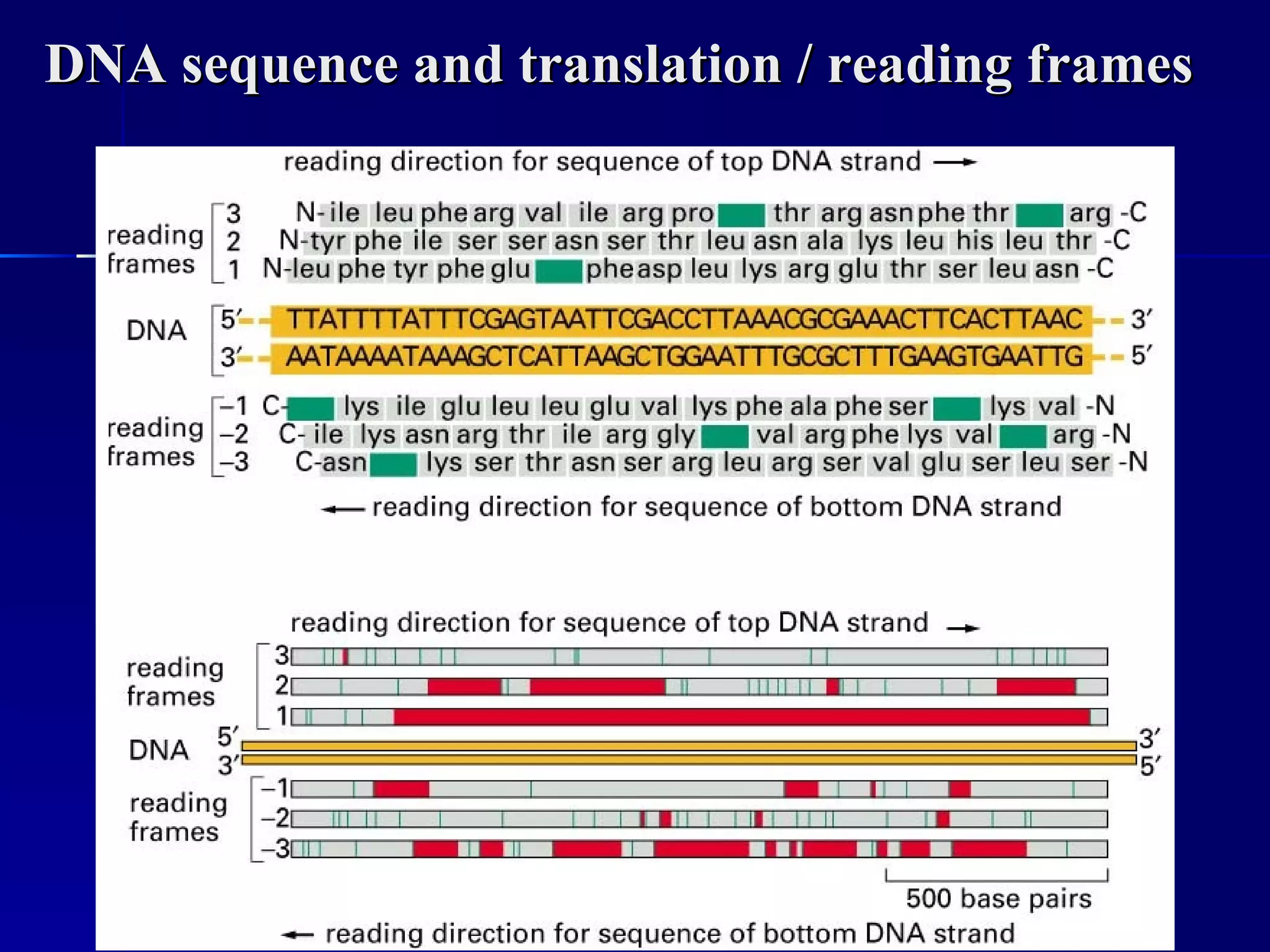
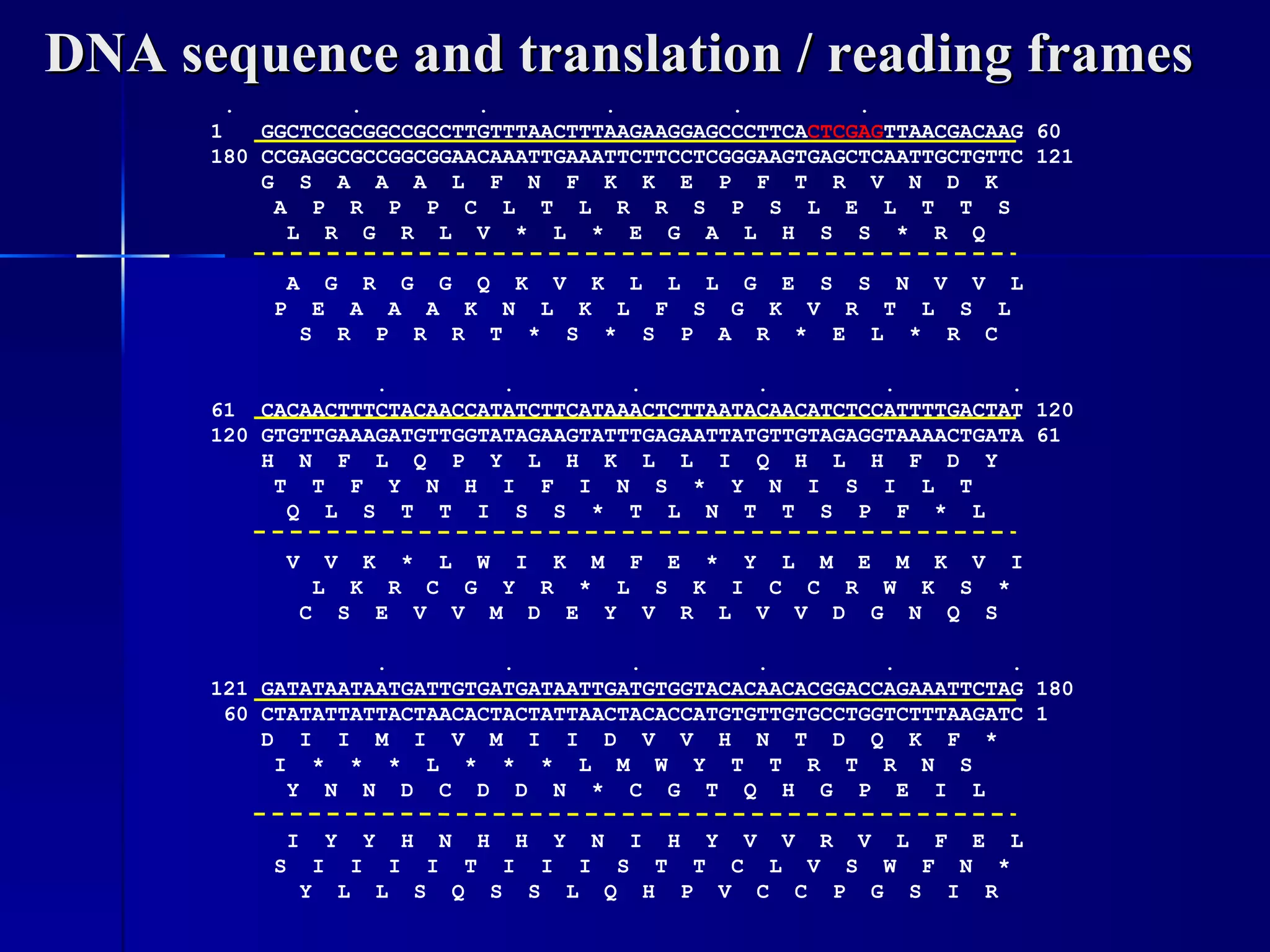

DNA contains the genetic material of organisms and is made up of nucleotides with a sugar-phosphate backbone. DNA is organized into chromosomes within the nucleus of eukaryotic cells. Genetic information flows from DNA to protein through two main processes - transcription of DNA to mRNA and translation of mRNA to protein using transfer RNA and ribosomes.















































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)







![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








